
Designstrategien für Prompts wie „wenige-Shot-Prompts“ führen nicht immer zu dem Ergebnis, Ergebnisse, die Sie benötigen. Die Feinabstimmung ist ein Prozess, mit dem Sie die bei bestimmten Aufgaben zu unterstützen oder dem Modell zu helfen, wenn die Anleitung nicht ausreicht und Sie eine Reihe von Beispielen haben die die gewünschten Ausgaben zeigen.
Diese Seite bietet einen konzeptionellen Überblick über die Feinabstimmung des Textmodells, Gemini API-Textdienst. Wenn Sie mit der Optimierung beginnen möchten, sehen Sie sich die Anleitung zur Feinabstimmung an. Eine allgemeinere Einführung in die Anpassung von LLMs für bestimmte Anwendungsfälle finden Sie im Crashkurs für maschinelles Lernen unter LLMs: Feinabstimmung, Destillation und Prompt-Engineering.
So funktioniert die Feinabstimmung
Das Ziel der Feinabstimmung besteht darin, die Leistung des Modells für Ihre spezifische Aufgabe weiter zu verbessern. Für die Feinabstimmung wird ein Training für das Modell bereitgestellt. Dataset mit vielen Beispielen für die Aufgabe. Bei Nischenaufgaben können Sie erhebliche Verbesserungen der Modellleistung erzielen, wenn Sie das Modell mit einer kleinen Anzahl von Beispielen abstimmen. Diese Art der Modellabstimmung wird überwachte Feinabstimmungen, um sie von anderen Arten der Feinabstimmung zu unterscheiden.
Ihre Trainingsdaten sollten als Beispiele mit Prompt-Eingaben erwartete Antwortausgaben. Sie können Modelle auch direkt in Google AI Studio mit Beispieldaten optimieren. Ziel ist es, dem Modell beizubringen, das gewünschte Verhalten nachzuahmen. oder Aufgabe, indem Sie ihm viele Beispiele geben, die dieses Verhalten oder diese Aufgabe veranschaulichen.
Wenn Sie einen Abstimmungsjob ausführen, lernt das Modell zusätzliche Parameter, die ihm helfen Die notwendigen Informationen zu codieren, um die gewünschte Aufgabe auszuführen oder das Gesuchte zu lernen verhalten. Diese Parameter können dann zum Zeitpunkt der Inferenz verwendet werden. Die Ausgabe des Abstimmungsjob ist ein neues Modell, das praktisch eine Kombination aus erlernten Parameter und dem ursprünglichen Modell.
Dataset vorbereiten
Bevor Sie mit der Feinabstimmung beginnen können, benötigen Sie ein Dataset, mit dem Sie das Modell abstimmen können. Für die beste Leistung bietet, sollten die Beispiele im Dataset hochwertig, vielfältig und für echte Ein- und Ausgaben repräsentativ sind.
Format
Die Beispiele in Ihrem Dataset sollten dem erwarteten Produktionstraffic entsprechen. Wenn Ihr Dataset bestimmte Formatierungen, Keywords, Anleitungen oder Informationen enthält, sollten die Produktionsdaten auf die gleiche Weise formatiert sein und die gleichen Anweisungen enthalten.
Wenn die Beispiele in Ihrem Dataset beispielsweise ein "question:" und ein "context:" enthalten, sollte der Produktionstraffic ebenfalls so formatiert werden, dass er ein "question:" und ein "context:" in der gleichen Reihenfolge wie in den Dataset-Beispielen enthält. Wenn Sie den Kontext ausschließen,
kann das Modell das Muster nicht erkennen.
auch wenn die genaue Frage
in einem Beispiel im Dataset enthalten war.
Hier ein weiteres Beispiel für Python-Trainingsdaten für eine Anwendung, die die nächste Zahl in einer Sequenz generiert:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
Es kann auch hilfreich sein, zu jedem Beispiel in Ihrem Dataset einen Prompt oder eine Präambel hinzuzufügen. die Leistung des abgestimmten Modells verbessern. Hinweis: Wenn Ihr Dataset einen Prompt oder eine Präambel enthält, sollte dieser auch in der Prompt-Anfrage an das optimierte Modell bei der Inferenz enthalten sein.
Beschränkungen
Hinweis: Die Abstimmung von Datasets für Gemini 1.5 Flash umfasst Folgendes: Einschränkungen:
- Die maximale Eingabegröße pro Beispiel beträgt 40.000 Zeichen.
- Die maximale Ausgabegröße pro Beispiel beträgt 5.000 Zeichen.
Größe der Trainingsdaten
Sie können ein Modell mit nur 20 Beispielen optimieren. Zusätzliche Daten verbessert allgemein die Qualität der Antworten. Sie sollten zwischen 100 und 500 Beispiele, je nach Anwendung. In der folgenden Tabelle sind die empfohlenen Dataset-Größen für die Feinabstimmung eines Textmodells für verschiedene gängige Aufgaben aufgeführt:
| Aufgabe | Anzahl der Beispiele im Dataset |
|---|---|
| Klassifizierung | 100+ |
| Zusammenfassung | 100-500+ |
| Dokumentsuche | 100+ |
Abstimmungs-Dataset hochladen
Die Daten werden entweder inline mit der API oder über Dateien übergeben, die in Google AI Studio
Wenn du die Clientbibliothek verwenden möchtest, musst du die Datendatei im createTunedModel-Aufruf angeben.
Die maximal zulässige Dateigröße beträgt 4 MB. Weitere Informationen finden Sie in der
Kurzanleitung zur Optimierung mit Python
um loszulegen.
Um die REST API mit cURL aufzurufen, stellen Sie dem
training_data-Argument. Informationen zu den ersten Schritten finden Sie unter Schnellstart zur Optimierung mit cURL.
Erweiterte Abstimmungseinstellungen
Beim Erstellen eines Abstimmungsjobs können Sie die folgenden erweiterten Einstellungen festlegen:
- Epochen:Ein vollständiger Trainingsdurchlauf über das gesamte Trainings-Dataset, sodass jedes Beispiel wurde einmal verarbeitet.
- Batchgröße:Die Reihe von Beispielen, die in einem Trainingsdurchlauf verwendet werden. Die die Batchgröße bestimmt die Anzahl der Beispiele in einem Batch.
- Lernrate:Eine Gleitkommazahl, die dem Algorithmus angibt, um die Modellparameter bei jeder Iteration anzupassen. Beispiel: eine Lernrate von 0,3, würden Gewichtungen und Verzerrungen dreimal mehr als eine Lernrate von 0,1. Hohe und niedrige Lernraten haben jeweils Vor- und Nachteile und sollten entsprechend dem Anwendungsfall angepasst werden.
- Multiplikator für Lernrate:Mit dem Multiplikator wird der Wert ursprüngliche Lernrate zu verbessern. Ein Wert von 1 verwendet die ursprüngliche Lernrate der modellieren. Werte über 1 erhöhen die Lernrate und Werte zwischen 1 und 0 die Lernrate senken.
Empfohlene Konfigurationen
In der folgenden Tabelle sehen Sie die empfohlenen Konfigurationen für die Foundation Model:
| Hyperparameter | Standardwert | Empfohlene Anpassungen |
|---|---|---|
| Epoche | 5 |
Verwenden Sie einen kleineren Wert, wenn der Verlust vor fünf Epochen zu einem Plateau führt. Wenn der Verlust konvergieren und sich nicht auffallen lässt, verwenden Sie einen höheren Wert. |
| Batchgröße | 4 | |
| Lernrate | 0,001 | Verwenden Sie für kleinere Datasets einen kleineren Wert. |
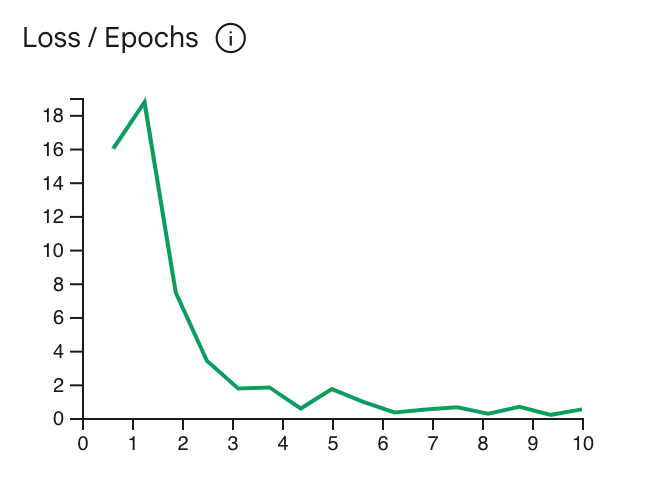
Die Verlustkurve zeigt, wie stark die Vorhersage des Modells vom Idealwert abweicht.
Vorhersagen in den Trainingsbeispielen nach jeder Epoche. Idealerweise sollten Sie
am tiefsten Punkt der Kurve direkt vor dem Plateau. Im folgenden Diagramm ist beispielsweise zu sehen, dass die Verlustkurve bei etwa 4 bis 6 Epochen ein Plateau erreicht. Das bedeutet, dass Sie den Parameter Epoch auf 4 festlegen können und trotzdem dieselbe Leistung erzielen.
Status des Abstimmungsjobs prüfen
Sie können den Status Ihres Abstimmungsjobs in Google AI Studio unter dem
Meine Bibliothek oder mithilfe des Attributs metadata des abgestimmten Modells im
Gemini API verfügbar.
Fehler beheben
Dieser Abschnitt enthält Tipps zur Behebung von Fehlern, die beim Erstellen des optimierten Modells auftreten können.
Authentifizierung
Für die Abstimmung mithilfe der API und der Clientbibliothek ist eine Nutzerauthentifizierung erforderlich. API-Schlüssel
allein reicht nicht aus. Wenn der Fehler 'PermissionDenied: 403 Request had
insufficient authentication scopes' angezeigt wird, müssen Sie den Nutzer
Authentifizierung.
Eine Anleitung zum Konfigurieren von OAuth-Anmeldedaten für Python findest du in diesem Artikel.
Gekündigte Modelle
Sie können einen Abstimmungsjob jederzeit vor Abschluss des Jobs abbrechen. Die Inferenzleistung eines abgebrochenen Modells ist jedoch nicht vorhersehbar, insbesondere wenn der Optimierungsjob zu Beginn des Trainings abgebrochen wird. Wenn du gekündigt hast, weil du Wenn Sie das Training zu einer früheren Epoche beenden möchten, sollten Sie eine neue Abstimmung erstellen und legen Sie für die Epoche einen niedrigeren Wert fest.
Einschränkungen abgestimmter Modelle
Hinweis:Abgestimmte Modelle unterliegen den folgenden Einschränkungen:
- Das Eingabelimit für ein abgestimmtes Flash-Modell von Gemini 1.5 beträgt 40.000 Zeichen.
- Der JSON-Modus wird von abgestimmten Modellen nicht unterstützt.
- Es wird nur die Texteingabe unterstützt.
Nächste Schritte
Hier finden Sie Anleitungen zur Feinabstimmung: