
Grafikprozessoren (Graphics Processing Units, GPUs) zum Ausführen Ihrer Modelle für maschinelles Lernen (ML) verwenden kann die Leistung Ihres Modells und die Nutzererfahrung erheblich verbessern. Ihrer ML-fähigen Anwendungen. Auf iOS-Geräten können Sie die Verwendung von GPU-beschleunigte Ausführung Ihrer Modelle mit einem delegieren. Bevollmächtigte fungieren als Hardwaretreiber für LiteRT ermöglicht es Ihnen, den Code Ihres Modells auf GPU-Prozessoren auszuführen.
Auf dieser Seite wird beschrieben, wie Sie die GPU-Beschleunigung für LiteRT-Modelle in iOS-Apps. Weitere Informationen zur Verwendung des GPU-Delegaten für LiteRT finden Sie einschließlich Best Practices und fortgeschrittener Techniken, siehe GPU Seite „Bevollmächtigte“.
GPU mit Interpreter API verwenden
Der LiteRT-Interpreter API eine Reihe von allgemeinen APIs zum Erstellen von ML-Anwendungen entwickelt. Die folgenden in der Anleitung, wie Sie einer iOS-App GPU-Unterstützung hinzufügen. Dieser Leitfaden Es wird davon ausgegangen, dass Sie bereits eine iOS-App haben, mit der ein ML-Modell erfolgreich ausgeführt werden kann. mit LiteRT.
Podfile so anpassen, dass es GPU-Unterstützung bietet
Ab LiteRT 2.3.0 ist der GPU-Delegate ausgeschlossen.
aus dem Pod entfernen,
um die Binärgröße zu reduzieren. Sie können sie einschließen, indem Sie
-Unterspezifikation für den Pod TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
ODER
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Sie können auch TensorFlowLiteObjC oder TensorFlowLiteC verwenden, wenn Sie
das Objective-C, das für Version 2.4.0 und höher verfügbar ist, oder die C API.
GPU-Delegaten initialisieren und verwenden
Sie können den GPU-Delegaten mit dem LiteRT-Interpreter verwenden. API mit einer Reihe von Programmierfunktionen Sprachen. Swift und Objective-C werden empfohlen, Sie können aber auch C++ und C) Die Verwendung von C ist erforderlich, wenn Sie eine frühere Version von LiteRT verwenden als 2,4. In den folgenden Codebeispielen wird erläutert, wie Sie den Delegaten mit jedem dieser Sprachen.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (vor Version 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Hinweise zur Verwendung der GPU API-Sprache
- In LiteRT-Versionen vor 2.4.0 kann die C API nur für Objective-C
- Die C++ API ist nur verfügbar, wenn Sie Bali verwenden oder TensorFlow erstellen Der Lite für dich allein. Die C++ API kann nicht mit CocoaPods verwendet werden.
- Bei Verwendung von LiteRT mit dem GPU-Delegaten mit C++ die GPU abrufen
über die
TFLGpuDelegateCreate()-Funktion delegieren und sie dann anInterpreter::ModifyGraphWithDelegate(), anstatt aufzurufenInterpreter::AllocateTensors()
Im Releasemodus erstellen und testen
Wechsel zu einem Release-Build mit den entsprechenden Einstellungen für den Metal API-Beschleuniger zu um eine bessere Leistung zu erzielen, und für abschließende Tests. In diesem Abschnitt wird erläutert, wie Sie Release-Build aktivieren und Einstellung für die Metal-Beschleunigung konfigurieren
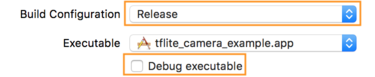
So wechseln Sie zu einem Release-Build:
- Bearbeiten Sie die Build-Einstellungen, indem Sie Produkt > Schema > Schema bearbeiten... und wählen Sie dann Ausführen aus.
- Ändern Sie auf dem Tab Info die Option Build Configuration in Release und
Entfernen Sie das Häkchen bei Fehlerbehebung aus ausführbarer Datei.
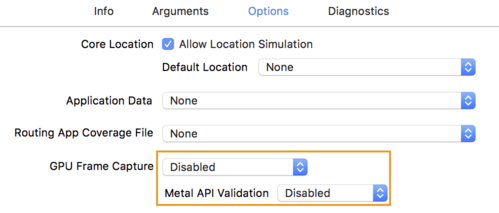
- Klicken Sie auf den Tab Options (Optionen) und ändern Sie GPU Frame Capture in Disabled.
und Metal API Validation auf Disabled.
- Achten Sie darauf, dass Sie „Nur Release-Builds“ auf einer 64-Bit-Architektur auswählen. Weniger als
Projektnavigator > tflite_camera_example > PROJEKT > Ihr_Projektname >
Build-Einstellungen auf Nur aktive Architektur erstellen > Loslassen in
Ja.

Erweiterte GPU-Unterstützung
In diesem Abschnitt geht es um die erweiterte Verwendung des GPU-Delegaten für iOS, einschließlich Optionen, Eingabe- und Ausgabepuffer und die Verwendung quantisierter Modelle delegieren.
Optionen für iOS delegieren
Der Konstruktor für den GPU-Delegaten akzeptiert eine struct an Optionen im Swift-
API,
Objective-C
API
und C
API
Übergabe von nullptr (C API) oder nichts (Objective-C und Swift API) an die
Initialisierer legt die Standardoptionen fest (diese werden im Abschnitt "Grundlegende Verwendung" erläutert.)
im Beispiel oben).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Eingabe-/Ausgabepuffer mit der C++ API
Für eine Berechnung auf der GPU müssen die Daten der GPU zur Verfügung stehen. Dieses Anforderung bedeutet häufig, dass Sie eine Speicherkopie ausführen müssen. Sie sollten damit Ihre Daten nach Möglichkeit die Speichergrenze von CPU/GPU überschreiten, da dies sehr viel Zeit vergeht. Normalerweise ist eine solche Überquerung unvermeidlich, Sonderfälle kann weggelassen werden.
Handelt es sich bei der Eingabe des Netzwerks um ein Bild, das bereits im GPU-Arbeitsspeicher geladen ist (für z. B. einer GPU-Textur mit dem Kamerafeed), kann diese im GPU-Arbeitsspeicher bleiben. ohne in den CPU-Arbeitsspeicher einzudringen. Das Gleiche gilt, wenn die Ausgabe des Netzwerks Die Form eines renderbaren Bildes, beispielsweise eines Bildstils Übertragung können Sie das Ergebnis direkt auf dem Bildschirm anzeigen.
Um die beste Leistung zu erzielen, ermöglicht LiteRT den Nutzern direkt aus dem TensorFlow-Hardwarepuffer lesen und in diesen schreiben und umgehen vermeidbare Speicherkopien.
Unter der Annahme, dass sich die Bildeingabe im GPU-Arbeitsspeicher befindet, müssen Sie sie zuerst in einen
MTLBuffer Objekt für „Metal“. Sie können ein TfLiteTensor mit einem
vom Nutzer vorbereitete MTLBuffer mit TFLGpuDelegateBindMetalBufferToTensor()
. Diese Funktion muss nach dem
Interpreter::ModifyGraphWithDelegate() Außerdem ist die Inferenzausgabe:
wird standardmäßig vom GPU-
in den CPU-Arbeitsspeicher kopiert. Sie können dieses Verhalten deaktivieren,
durch Anruf bei Interpreter::SetAllowBufferHandleOutput(true) im Zeitraum
die Initialisierung bei.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Sobald das Standardverhalten deaktiviert ist, wird die Inferenzausgabe von der GPU kopiert
zu CPU-Arbeitsspeicher erfordert einen expliziten Aufruf von
Interpreter::EnsureTensorDataIsReadable() für jeden Ausgabetensor. Dieses
funktioniert auch für quantisierte Modelle. Sie müssen jedoch
Puffer der Größe "float32" mit Daten der Größe "float32", da der Puffer an den
internen de-quantisierten Zwischenspeicher.
Quantisierte Modelle
Die GPU Delegate-Bibliotheken für iOS unterstützen standardmäßig quantisierte Modelle. Du nicht Codeänderungen vornehmen, um quantisierte Modelle mit dem GPU-Delegaten zu verwenden. Die Im folgenden Abschnitt wird erläutert, wie Sie die quantisierte Unterstützung für Tests oder zu experimentellen Zwecken.
Unterstützung quantisierter Modelle deaktivieren
Der folgende Code zeigt, wie Sie die Unterstützung für quantisierte Modelle deaktivieren.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Weitere Informationen zum Ausführen quantisierter Modelle mit GPU-Beschleunigung finden Sie unter GPU Delegate