
שימוש ביחידות עיבוד גרפיות (GPU) להרצת מודלים של למידת מכונה (ML) יכול לשפר באופן משמעותי את ביצועי המודל ואת חוויית המשתמש של האפליקציות שלכם שתומכות בלמידת מכונה. במכשירי iOS, ניתן להפעיל את השימוש ב- לביצוע מואץ GPU של המודלים שלך באמצעות הענקת גישה. משתמשים שקיבלו הרשאה פועלים כמנהלי חומרה עבור LiteRT, מאפשרת להריץ את קוד המודל במעבדי GPU.
בדף הזה נסביר איך להפעיל האצת GPU לדגמי LiteRT ב- אפליקציות ל-iOS. למידע נוסף על השימוש בהאצלת GPU עבור LiteRT, כולל שיטות מומלצות ושיטות מתקדמות, מומלץ לעיין בGPU משתמשים שקיבלו הרשאה.
שימוש ב-GPU עם ממשק ה-API של Google Translate
תרגום שיחה פעילה (LiteRT) API מספק לפיתוח אפליקציות של למידת מכונה. הבאים שמנחות אתכם איך להוסיף תמיכה ב-GPU לאפליקציה ל-iOS. המדריך הזה ההנחה היא שכבר יש לכם אפליקציה ל-iOS שיכולה להפעיל מודל למידת מכונה עם LiteRT.
שינוי ה-Podfile כך שיכלול תמיכה ב-GPU
החל מגרסת LiteRT 2.3.0, מקבל הגישה ל-GPU לא נכלל
מרצף ה-Pod כדי להקטין את הגודל הבינארי. כדי לכלול אותם, צריך לציין
תת-מפרט של רצף המודעות TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
או
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
אפשר גם להשתמש ב-TensorFlowLiteObjC או ב-TensorFlowLiteC אם רוצים להשתמש
יעד C, שזמין לגרסאות 2.4.0 ואילך, או C API.
אתחול ושימוש בהענקת גישה ל-GPU
אפשר להשתמש בהענקת גישה ל-GPU עם תרגום שיחה פעילה של LiteRT API בכמה תכנות בשפות שונות. מומלץ להשתמש ב-Swift וב-Objective-C, אבל אפשר גם להשתמש ב-C++ סי. נדרש שימוש ב-C אם משתמשים בגרסה של LiteRT לפני כן מ-2.4. בדוגמאות הבאות אפשר לקרוא איך להשתמש בהענקת הגישה של השפות האלה.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (לפני 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
הערות לשימוש בשפת GPU API
- בגרסאות LiteRT שקודמות לגרסה 2.4.0 אפשר להשתמש ב-C API רק לצורך מטרה ג'
- ה-API של C++ זמין רק כשמשתמשים ב-bazel או בשלב הפיתוח של TensorFlow Lite בעצמך. לא ניתן להשתמש ב-API של C++ עם CocoaPods.
- כשמשתמשים ב-LiteRT עם נציג ל-GPU עם C++, מקבלים את ה-GPU
להעניק גישה באמצעות הפונקציה
TFLGpuDelegateCreate()ואז להעביר אותה אלInterpreter::ModifyGraphWithDelegate(), במקום להתקשרInterpreter::AllocateTensors().
יצירה ובדיקה באמצעות מצב גרסה
עוברים ל-build של גרסה עם ההגדרות המתאימות של מאיץ ה-מתכת API כך: כדי לקבל ביצועים טובים יותר ולבדיקה אחרונה. בקטע הזה נסביר איך לאפשר גרסת build של גרסה וקביעת הגדרות להאצת מטאל.
כדי לעבור ל-build של הגרסה:
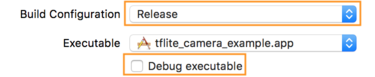
- כדי לערוך את הגדרות ה-build, בוחרים באפשרות מוצר > סכימה > עריכת סכימה... ובוחרים באפשרות Run.
- בכרטיסייה Info (מידע), משנים את Build Configuration (הגדרת Build) ל-Release (גרסה)
מבטלים את הסימון של קובץ הפעלה של ניפוי באגים.
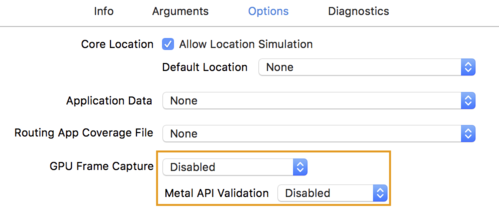
- לוחצים על הכרטיסייה אפשרויות ומשנים את האפשרות צילום מסגרת של GPU למושבת.
ואימות מטאל API למצב מושבת.
- חשוב לבחור בגרסאות build של גרסאות build בלבד עם ארכיטקטורה של 64 ביט. מתחת
ניווט בפרויקט > tflite_camera_example > פרויקט > your_project_name >
Build Settings (הגדרות Build) מגדירים Build Active Architecture Only > (יצירת ארכיטקטורה פעילה בלבד) משחררים את הסמן כדי:
כן.

תמיכה מתקדמת ב-GPU
בקטע הזה מתוארים שימושים מתקדמים בהאצלת GPU ל-iOS, כולל אפשרויות להענקת גישה, מאגרי נתונים זמניים של קלט ופלט ושימוש במודלים כמותיים.
אפשרויות של הענקת גישה ל-iOS
ה-constructor של מקבל הגישה ל-GPU מקבל struct של אפשרויות ב-Swift
API,
Objective-C
API,
ו-C
API.
העברת nullptr (C API) או שום דבר (Objective-C ו-Swift API) אל
המאתחל מגדיר את אפשרויות ברירת המחדל (שמבוטאות בקטע 'שימוש בסיסי'
לדוגמה למעלה).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
מאגרי נתונים זמניים של קלט/פלט באמצעות C++ API
כדי לחשב את ה-GPU, הנתונים צריכים להיות זמינים ל-GPU. הזה המשמעות היא בדרך כלל שתצטרכו ליצור עותק של הזיכרון. עליך להימנע אם אפשר, הנתונים חוצים את גבולות הזיכרון של המעבד (CPU) או של ה-GPU, פרק זמן משמעותי. בדרך כלל, המעבר הזה הוא בלתי נמנע, אבל בחלק מהמקרים במקרים מיוחדים, שניתן להשמיט אחד מהשני.
אם הקלט של הרשת הוא תמונה שכבר נטענה בזיכרון ה-GPU ( למשל, טקסטורה של GPU שמכיל את פיד המצלמה). הוא יכול להישאר בזיכרון של ה-GPU בלי להזין אף פעם את זיכרון המעבד. באופן דומה, אם הפלט של הרשת בצורה של תמונה שניתנת לעיבוד, כמו סגנון לתמונה העברה ניתן להציג את התוצאה ישירות על המסך.
כדי להשיג את הביצועים הטובים ביותר, LiteRT מאפשר למשתמשים קריאה וכתיבה ישירות ממאגר הנתונים הזמני של TensorFlow ולמעקף עותקים של זיכרון שאפשר להימנע מהם.
בהנחה שקלט התמונה נמצא בזיכרון GPU, תחילה עליכם להמיר אותו
אובייקט MTLBuffer בשביל מתכת. אפשר לשייך TfLiteTensor אל
MTLBuffer הוכן על ידי המשתמש עם TFLGpuDelegateBindMetalBufferToTensor()
מותאמת אישית. שימו לב שחובה לקרוא לפונקציה הזו אחרי
Interpreter::ModifyGraphWithDelegate(). בנוסף, פלט ההסקה הוא
מועתקות מזיכרון ה-GPU לזיכרון המעבד (CPU) כברירת מחדל. אפשר להשבית את ההתנהגות הזו
באמצעות התקשרות אל Interpreter::SetAllowBufferHandleOutput(true) במהלך
באתחול.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
אחרי שמשביתים את התנהגות ברירת המחדל, מעתיקים את פלט ההסקה מה-GPU.
מהזיכרון לזיכרון המעבד (CPU) נדרשת קריאה מפורשת
Interpreter::EnsureTensorDataIsReadable() לכל ארגומנט פלט. הזה
עובדת גם במודלים כמותיים, אבל עדיין צריך להשתמש
חוצץ בגודל float32 עם נתוני float32, כי מאגר הנתונים הזמני קשור
מאגר נתונים זמני ונפרד.
מודלים כמותיים
ספריות הקצאת הגישה ל-GPU ב-iOS תומכות במודלים כמותיים כברירת מחדל. לא תצטרכו לבצע שינויים בקוד כדי להשתמש במודלים כמותיים עם מקבל הגישה ל-GPU. בקטע הבא מוסבר איך להשבית תמיכה כמותית בבדיקה למטרות ניסיוניות.
השבתת התמיכה במודל כמותי
הקוד הבא מסביר איך להשבית את התמיכה במודלים כמותיים.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
למידע נוסף על הרצת מודלים כמותיים עם האצת GPU, ראו: סקירה כללית בנושא הענקת גישה ל-GPU.