
استخدام وحدات معالجة الرسومات (GPU) لتشغيل نماذج تعلُّم الآلة (ML) تحسين أداء النموذج وتجربة المستخدم بشكل كبير من تطبيقاتك التي تستخدم تعلُّم الآلة على أجهزة iOS، يمكنك تفعيل استخدام التنفيذ المسرّع عبر وحدة معالجة الرسومات لنماذجك باستخدام التفويض: يعمل المفوَّضون كبرامج تشغيل للأجهزة يتيح لك LiteRT تشغيل رمز النموذج على معالِجات وحدة معالجة الرسومات.
توضح هذه الصفحة كيفية تفعيل تسريع وحدة معالجة الرسومات لنماذج LiteRT في تطبيقات iOS. لمزيد من المعلومات حول استخدام تفويض وحدة معالجة الرسومات في LiteRT، بما في ذلك أفضل الممارسات والتقنيات المتقدمة، راجع وحدة معالجة الرسومات المفوَّض.
استخدام وحدة معالجة الرسومات مع واجهة برمجة التطبيقات للترجمة الفورية
The LiteRT مترجم فوري توفّر واجهة برمجة التطبيقات مجموعة من والغرض من ذلك لإنشاء تطبيقات التعلم الآلي. ما يلي: خلال إضافة إمكانية استخدام وحدة معالجة الرسومات إلى تطبيق iOS. هذا الدليل أن لديك تطبيق iOS يمكنه تنفيذ نموذج تعلُّم الآلة بنجاح مع LiteRT.
تعديل Podfile لتضمين وحدة معالجة الرسومات المتوافقة
بدءًا من إصدار LiteRT 2.3.0، يتم استبعاد تفويض وحدة معالجة الرسومات
من الصفيحة لخفض الحجم الثنائي. يمكنك تضمينها عن طريق تحديد
المواصفات الفرعية للمجموعة الإعلانية TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
أو
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
يمكنك أيضًا استخدام TensorFlowLiteObjC أو TensorFlowLiteC إذا كنت تريد استخدام
أو Objective-C المتوفر للإصدار 2.4.0 والإصدارات اللاحقة، أو واجهة برمجة التطبيقات C API.
تهيئة واستخدام تفويض وحدة معالجة الرسومات
يمكنك استخدام تفويض وحدة معالجة الرسومات مع الترجمة الفورية في LiteRT. واجهة برمجة تطبيقات مع عدد من البرامج اللغات. يوصى باستخدام Swift وObjective-C، ولكن يمكنك أيضًا استخدام C++ "قصر العدل في اسطنبول"، يجب استخدام C إذا كنت تستخدم إصدارًا من LiteRT من 2.4. توضّح أمثلة التعليمات البرمجية التالية كيفية استخدام المفوَّض مع كل من هذه اللغات.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (قبل 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
ملاحظات حول استخدام لغة واجهة برمجة التطبيقات لوحدة معالجة الرسومات
- ويمكن لإصدارات LiteRT السابقة للإصدار 2.4.0 استخدام واجهة برمجة تطبيقات C API فقط. الهدف-ج.
- لا تتوفّر واجهة برمجة التطبيقات C++ إلا عند استخدام bazel أو إصدار TensorFlow. يمكنك استخدام الوضع البسيط بمفردك. لا يمكن استخدام واجهة برمجة تطبيقات C++ مع CocoaPods.
- عند استخدام LiteRT مع تفويض وحدة معالجة الرسومات مع C++، احصل على وحدة GPU
تفويضًا عبر الدالة
TFLGpuDelegateCreate()ثم تمريره إلىInterpreter::ModifyGraphWithDelegate()، بدلاً من الاتصالInterpreter::AllocateTensors()
إنشاء التطبيقات واختبارها باستخدام وضع الإصدار
التغيير إلى إصدار باستخدام الإعدادات المناسبة لمسرِّع واجهة برمجة التطبيقات Metal API إلى للحصول على أداء أفضل وللاختبار النهائي. يشرح هذا القسم كيفية تفعيل إصدار إصدار وضبط إعداد تسريع الأجهزة المعدنية.
للتغيير إلى إصدار إصدار:
- تعديل إعدادات الإصدار من خلال اختيار المنتج > المخطط > تعديل المخطّط... ثم اختيار Run (تشغيل).
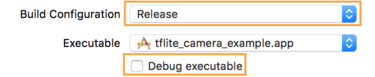
- في علامة التبويب المعلومات، غيِّر إعدادات الإصدار إلى الإصدار.
أزِل العلامة من المربّع تصحيح الأخطاء القابل للتنفيذ.
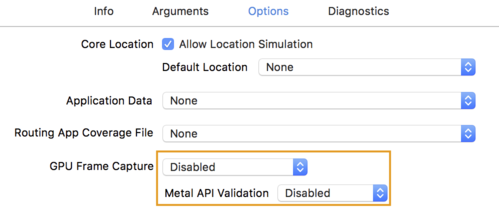
- انقر على علامة التبويب خيارات (Options) وغيِّر التقاط إطار وحدة معالجة الرسومات إلى غير مفعّل
والتحقق من واجهة برمجة تطبيقات Metal على غير مفعّل.
- تأكد من تحديد "الإصدار فقط يعتمد على بنية 64 بت". تحت
أداة التنقّل في المشروع > tflite_camera_example > المشروع > your_project_name >
ضبط إعدادات الإصدار على إنشاء بنية نشطة فقط > التحرير إلى
نعم.

التوافق المتقدِّم مع وحدة معالجة الرسومات
يتناول هذا القسم الاستخدامات المتقدّمة لتفويض وحدة معالجة الرسومات في أجهزة iOS، بما في ذلك تفويض الخيارات، والموارد الاحتياطية للإدخال والمخرجات، واستخدام النماذج الكَمية.
تفويض الخيارات لنظام التشغيل iOS
تقبل الدالة الإنشائية لمفوض وحدة معالجة الرسومات struct من الخيارات في ملف Swift
واجهة برمجة التطبيقات،
Objective-C
واجهة برمجة التطبيقات،
وC
واجهة برمجة التطبيقات.
تمرير واجهة برمجة التطبيقات nullptr (C API) أو عدم إدخال أي شيء (Objective-C وSwift API) إلى واجهة برمجة التطبيقات
يحدد برنامج تهيئة الإعدادات الخيارات الافتراضية (والتي يتم توضيحها في قسم الاستخدام الأساسي
المثال أعلاه).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
مخازن مؤقتة للإدخال والإخراج باستخدام واجهة برمجة التطبيقات C++
تتطلب الحوسبة على وحدة معالجة الرسومات توفر البيانات لوحدة GPU. هذا النمط أو متطلبات جديدة عادةً أنه يجب عليك عمل نسخة من الذاكرة. يجب أن تتجنب وجود بياناتك تتخطى حدود ذاكرة وحدة المعالجة المركزية (CPU)/وحدة معالجة الرسومات إن أمكن، حيث قد يستغرق ذلك لفترة كبيرة من الوقت. عادةً، يكون هذا العبور أمرًا لا مفر منه، ولكن في بعض في حالات خاصة، يمكن حذف أحدهما أو الآخر.
إذا كان مدخل الشبكة عبارة عن صورة تم تحميلها بالفعل في ذاكرة وحدة معالجة الرسومات (على سبيل المثال، مثال، تركيبة وحدة معالجة رسومات تحتوي على خلاصة الكاميرا) يمكن أن تبقى في ذاكرة وحدة معالجة الرسومات دون الدخول إلى ذاكرة وحدة المعالجة المركزية (CPU) على الإطلاق. وبالمثل، إذا كان ناتج الشبكة في شكل صورة قابلة للعرض، مثل نمط الصورة النقل يمكنك عرض النتيجة مباشرةً على الشاشة.
لتحقيق أفضل أداء، يتيح LiteRT للمستخدمين القراءة مباشرةً من المخزن المؤقت لأجهزة TensorFlow والكتابة إليها وتجاوز نسخ الذاكرة التي يمكن تجنبها.
وبافتراض أن إدخال الصورة في ذاكرة وحدة معالجة الرسومات، يجب أولاً تحويله إلى
عنصر واحد (MTLBuffer) لتطبيق Metal. يمكنك ربط TfLiteTensor بـ
MTLBuffer من تجهيز المستخدم من خلال TFLGpuDelegateBindMetalBufferToTensor()
الأخرى. تجدر الإشارة إلى أنّه يجب استدعاء هذه الدالة بعد
Interpreter::ModifyGraphWithDelegate() علاوة على ذلك، يكون ناتج الاستنتاج هو
بشكل افتراضي، يتم نسخه من ذاكرة وحدة معالجة الرسومات إلى ذاكرة وحدة المعالجة المركزية. يمكنك إيقاف هذا السلوك
من خلال الاتصال بالرقم Interpreter::SetAllowBufferHandleOutput(true) أثناء
التهيئة.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
بعد إيقاف السلوك التلقائي، نسخ ناتج الاستنتاج من وحدة معالجة الرسومات
الذاكرة إلى ذاكرة وحدة المعالجة المركزية (CPU) طلبًا صريحًا
Interpreter::EnsureTensorDataIsReadable() لكل مقياس من مؤشرات الإخراج. هذا النمط
أيضًا مع النماذج الكميّة، ولكنك ما زلت بحاجة إلى استخدام
المخزن المؤقت ذو حجم float32 مع بيانات float32، لأن المخزن المؤقت مرتبط
المورد الاحتياطي الداخلي غير الكمّي.
النماذج الكَمية
مكتبات تفويض وحدة معالجة الرسومات في iOS تتوافق تلقائيًا مع النماذج الكَمية. أنت لا إلى إجراء أي تغييرات على التعليمات البرمجية لاستخدام نماذج محددة الكمية مع تفويض وحدة معالجة الرسومات. تشير رسالة الأشكال البيانية يوضح القسم التالي كيفية إيقاف الدعم الكمّي للاختبار أو لأغراض تجريبية.
إيقاف إتاحة النموذج الكمي
يوضّح الرمز التالي كيفية إيقاف إتاحة النماذج الكَمية.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
لمزيد من المعلومات عن تشغيل نماذج الكمية باستخدام تسريع وحدة معالجة الرسومات، يُرجى الاطّلاع على نظرة عامة على تفويض وحدة معالجة الرسومات.