
Benchmarking-Tools
TensorFlow Lite-Benchmarktools messen und berechnen derzeit Statistiken für die folgenden wichtigen Leistungsmesswerte:
- Initialisierungszeit
- Inferenzzeit des Aufwärmstatus
- Inferenzzeit des stabilen Zustands
- Arbeitsspeichernutzung während der Initialisierungszeit
- Arbeitsspeichernutzung insgesamt
Die Benchmark-Tools sind als Benchmark-Apps für Android und iOS sowie als native Befehlszeilen-Binärdateien verfügbar. Sie verwenden alle dieselbe Logik zur zentralen Leistungsmessung. Beachten Sie, dass sich die verfügbaren Optionen und Ausgabeformate aufgrund der Unterschiede in der Laufzeitumgebung leicht unterscheiden.
Android-Benchmark-App
Es gibt zwei Möglichkeiten, das Benchmark-Tool unter Android zu verwenden. Eine ist ein natives Benchmark-Binärprogramm und eine andere eine Android-Benchmark-App, mit der besser bewertet wird, wie das Modell in der App abschneiden würde. In jedem Fall weichen die Zahlen vom Benchmark-Tool leicht von denen im Fall einer Inferenz mit dem Modell in der tatsächlichen App ab.
Diese Android-Benchmark-App hat keine Benutzeroberfläche. Installieren und führen Sie ihn mit dem Befehl adb aus und rufen Sie mit dem Befehl adb logcat die Ergebnisse ab.
App herunterladen oder erstellen
Laden Sie die vordefinierten Android-Benchmark-Apps über die folgenden Links herunter:
Android-Benchmark-Apps, die TF-Ops über den Flex-Delegaten unterstützen, finden Sie unter den folgenden Links:
Sie können die Anwendung auch aus dem Quellcode erstellen, indem Sie instructions folgen.
Benchmark vorbereiten
Bevor Sie die Benchmark-App ausführen, installieren Sie sie und übertragen Sie die Modelldatei so auf das Gerät:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Benchmark ausführen
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph ist ein erforderlicher Parameter.
graph:string
Der Pfad zur TFLite-Modelldatei.
Sie können weitere optionale Parameter zum Ausführen der Benchmark angeben.
num_threads:int(Standard=1)
Die Anzahl der Threads, die zum Ausführen des TFLite-Interpreters verwendet werden sollen.use_gpu:bool(Standard=falsch)
Verwenden Sie den GPU-Delegaten.use_xnnpack:bool(Standard=false)
Verwenden Sie den XNNPACK-Delegaten.
Je nach verwendetem Gerät sind einige dieser Optionen möglicherweise nicht verfügbar oder haben keine Auswirkungen. Unter Parameter finden Sie weitere Leistungsparameter, die Sie mit der Benchmark-App ausführen können.
Sehen Sie sich die Ergebnisse mit dem Befehl logcat an:
adb logcat | grep "Inference timings"
Die Benchmark-Ergebnisse werden so erfasst:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Natives Benchmark-Binärprogramm
Das Benchmark-Tool wird auch als natives binäres benchmark_model-Tool bereitgestellt. Sie können dieses Tool über eine Shell-Befehlszeile auf Linux- und Mac-Geräten, eingebetteten Geräten und Android-Geräten ausführen.
Binärprogramm herunterladen oder erstellen
Klicken Sie auf die folgenden Links, um die nächtlichen vordefinierten nativen Befehlszeilen-Binärdateien herunterzuladen:
Für nächtliche vordefinierte Binärdateien, die TF-Ops über den Flex-Delegaten unterstützen, verwenden Sie die folgenden Links:
Sie können das native Benchmark-Binärprogramm auch aus einer Quelle auf Ihrem Computer erstellen.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Wenn Sie Builds mit der Android-NDK-Toolchain erstellen möchten, müssen Sie zuerst die Build-Umgebung einrichten. Folgen Sie dazu dieser Anleitung oder verwenden Sie das Docker-Image wie in dieser Anleitung beschrieben.
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
Benchmark ausführen
Um Benchmarks auf Ihrem Computer auszuführen, führen Sie das Binärprogramm über die Shell aus.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
Sie können die oben genannten Parameter mit dem nativen Befehlszeilen-Binärprogramm verwenden.
Profilerstellung für Modellvorgänge
Mit dem Binärmodell des Benchmarkmodells können Sie außerdem ein Profil von Modellvorgängen erstellen und die Ausführungszeiten jedes Operators abrufen. Übergeben Sie dazu beim Aufruf das Flag --enable_op_profiling=true an benchmark_model. Weitere Informationen
Natives Benchmark-Binärprogramm für mehrere Leistungsoptionen bei einer einzigen Ausführung
Außerdem wird eine praktische und einfache C++-Binärdatei bereitgestellt, um mehrere Leistungsoptionen in einem einzigen Durchlauf zu vergleichen. Dieses Binärprogramm basiert auf dem oben genannten Benchmark-Tool, das jeweils nur eine einzige Leistungsoption für das Benchmarking verwenden konnte. Sie verwenden denselben Build-/Installations-/Ausführungsprozess, aber der build-Zielname dieser Binärdatei lautet benchmark_model_performance_options und es sind einige zusätzliche Parameter erforderlich.
Ein wichtiger Parameter für diese Binärdatei ist:
perf_options_list: string (default='all')
Eine durch Kommas getrennte Liste von TFLite-Leistungsoptionen für das Benchmarking.
Sie können für dieses Tool vorgefertigte Binärprogramme für Nachtaufnahmen abrufen, wie unten aufgeführt:
iOS-Benchmark-App
Zum Ausführen von Benchmarks auf einem iOS-Gerät müssen Sie die App aus der Quelle erstellen.
Legen Sie die TensorFlow Lite-Modelldatei im Verzeichnis benchmark_data der Quellstruktur ab und ändern Sie die Datei benchmark_params.json. Diese Dateien werden in die Anwendung gepackt und die Anwendung liest Daten aus dem Verzeichnis. Eine ausführliche Anleitung finden Sie in der Benchmark-App für iOS.
Leistungs-Benchmarks für bekannte Modelle
In diesem Abschnitt sind die TensorFlow Lite-Leistungs-Benchmarks für die Ausführung bekannter Modelle auf einigen Android- und iOS-Geräten aufgeführt.
Android-Leistungs-Benchmarks
Diese Leistungsvergleichszahlen wurden mit dem nativen Benchmark-Binärprogramm generiert.
Bei Android-Benchmarks ist die CPU-Affinität so eingestellt, dass auf dem Gerät große Kerne verwendet werden, um die Varianz zu reduzieren (siehe Details).
Dabei wird davon ausgegangen, dass Modelle heruntergeladen und in das Verzeichnis /data/local/tmp/tflite_models entpackt wurden. Die Benchmark-Binärdatei wird mit dieser Anleitung erstellt und geht davon aus, dass sie sich im Verzeichnis /data/local/tmp befindet.
So führen Sie die Benchmark aus:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Legen Sie --use_gpu=true für die Ausführung mit dem GPU-Delegaten fest.
Die unten aufgeführten Leistungswerte werden unter Android 10 gemessen.
| Modellname | Gerät | CPU, 4 Threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1.0_224 (Quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5,0 ms | --- | |
| NASNet Mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
iOS-Leistungs-Benchmarks
Diese Leistungsvergleichszahlen wurden mit der iOS-Benchmark-App generiert.
Zum Ausführen von iOS-Benchmarks wurde die Benchmark-App geändert, sodass sie das entsprechende Modell enthält, und benchmark_params.json wurde geändert, um num_threads auf 2 zu setzen. Zur Verwendung des GPU-Delegaten wurden die Optionen "use_gpu" : "1" und "gpu_wait_type" : "aggressive" auch zu benchmark_params.json hinzugefügt.
| Modellname | Gerät | CPU, 2 Threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (Quant) | iPhone XS | 11 ms | --- |
| NASNet Mobile | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
TensorFlow Lite-Internes verfolgen
TensorFlow Lite-Internes in Android verfolgen
Interne Ereignisse vom TensorFlow Lite-Interpreter einer Android-App können von Android-Tracing-Tools erfasst werden. Es handelt sich um dieselben Ereignisse mit der Android Trace API, sodass die aus Java-/Kotlin-Code erfassten Ereignisse zusammen mit den internen TensorFlow Lite-Ereignissen angezeigt werden.
Hier einige Beispiele für Ereignisse:
- Operatoraufruf
- Diagrammänderung durch Bevollmächtigten
- Tensor-Zuweisung
In dieser Anleitung werden unter anderem der CPU-Profiler von Android Studio und die App „System Tracing“ behandelt. Weitere Optionen finden Sie unter Perfetto-Befehlszeilentool und Systrace-Befehlszeilentool.
Trace-Ereignisse in Java-Code hinzufügen
Dies ist ein Code-Snippet aus der Beispielanwendung für die Bildklassifizierung. Der TensorFlow Lite-Interpreter wird im Abschnitt recognizeImage/runInference ausgeführt. Dieser Schritt ist optional, aber es hilft zu erkennen, wo der Inferenzaufruf erfolgt.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
TensorFlow Lite-Tracing aktivieren
Um TensorFlow Lite-Tracing zu aktivieren, legen Sie die Android-Systemeigenschaft debug.tflite.trace auf 1 fest, bevor Sie die Android-App starten.
adb shell setprop debug.tflite.trace 1
Wenn dieses Attribut bei der Initialisierung des TensorFlow Lite-Interpreters festgelegt wurde, werden Schlüsselereignisse (z.B. Operatoraufruf) vom Interpreter verfolgt.
Wenn Sie alle Traces erfasst haben, deaktivieren Sie das Tracing. Dazu setzen Sie den Attributwert auf 0.
adb shell setprop debug.tflite.trace 0
CPU-Profiler von Android Studio
So erfassen Sie Traces mit dem Android Studio CPU Profiler:
Wählen Sie in den oberen Menüs Ausführen > Profil 'app' aus.
Klicken Sie auf eine beliebige Stelle auf der CPU-Zeitachse, wenn das Profiler-Fenster angezeigt wird.
Wählen Sie als CPU-Profilerstellung die Option „Trace System Calls“ (Systemaufrufe verfolgen) aus.
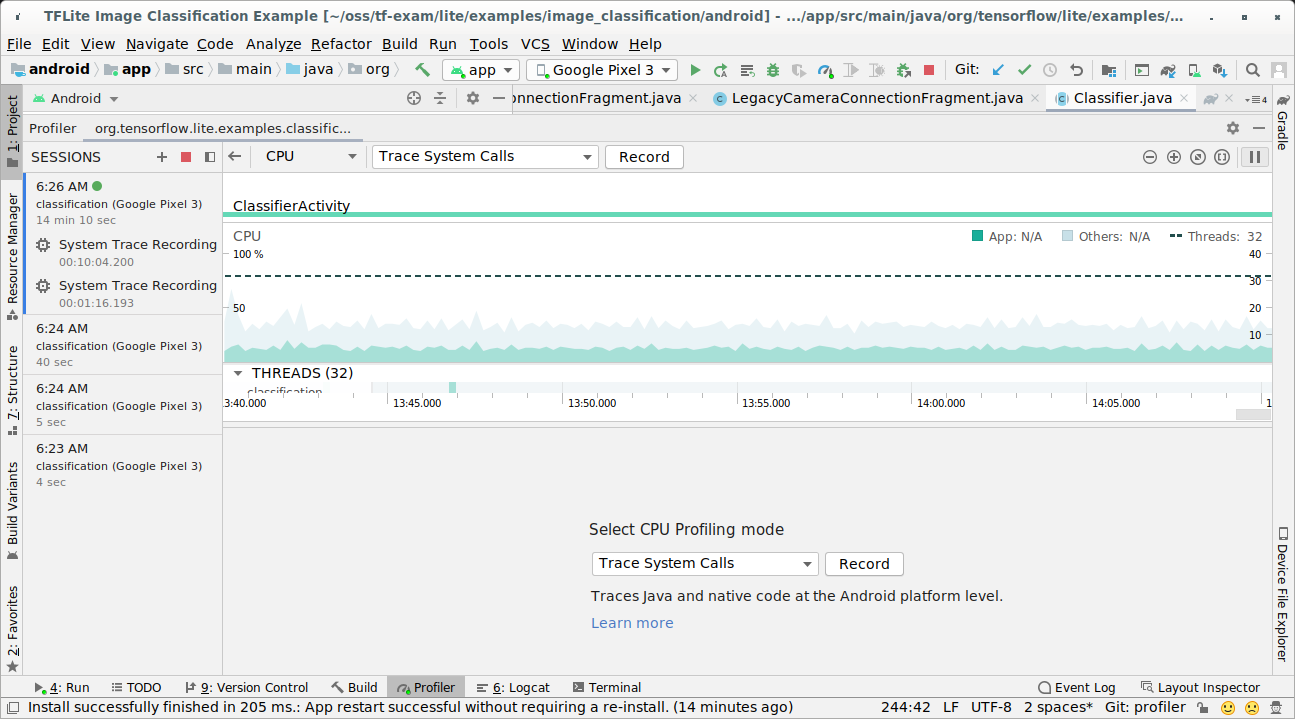
Drücke auf die Schaltfläche „Aufnehmen“.
Drücken Sie die Schaltfläche „Stopp“.
Untersuchen Sie das Trace-Ergebnis.
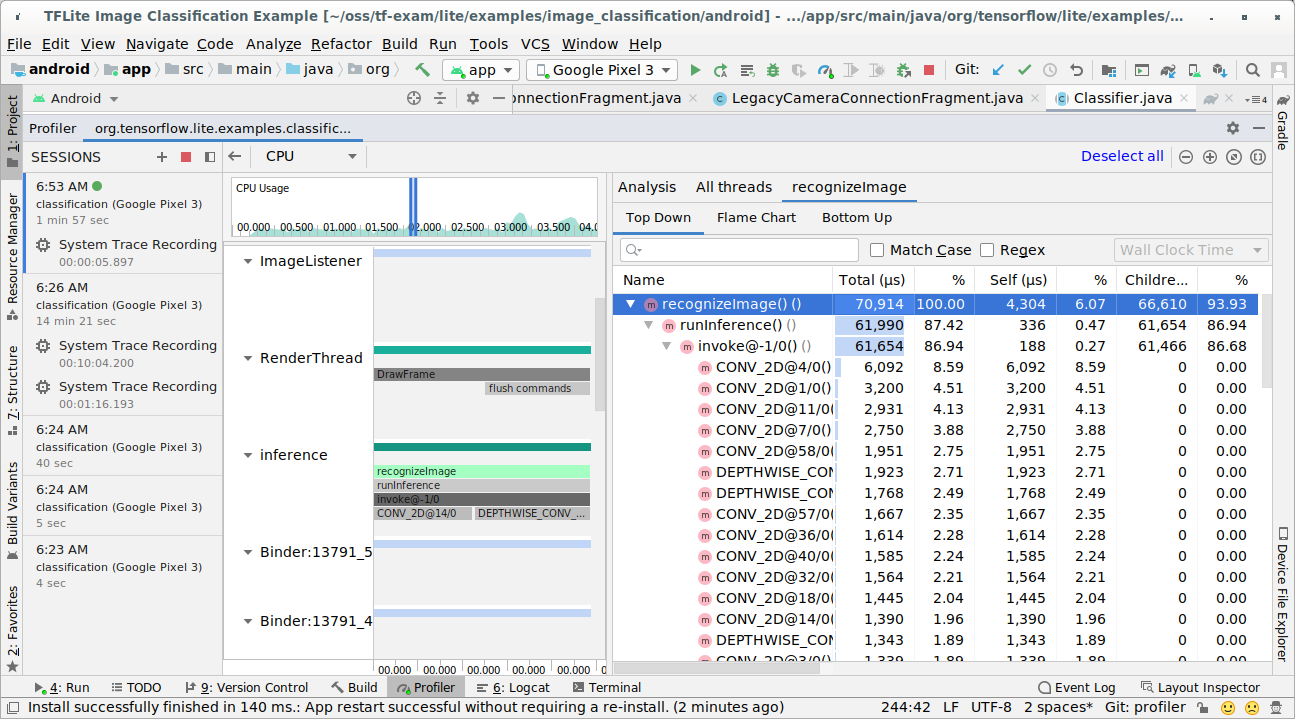
In diesem Beispiel sehen Sie die Hierarchie der Ereignisse in einem Thread und Statistiken für jede Operatorzeit sowie den Datenfluss der gesamten Anwendung zwischen den Threads.
System-Tracing-App
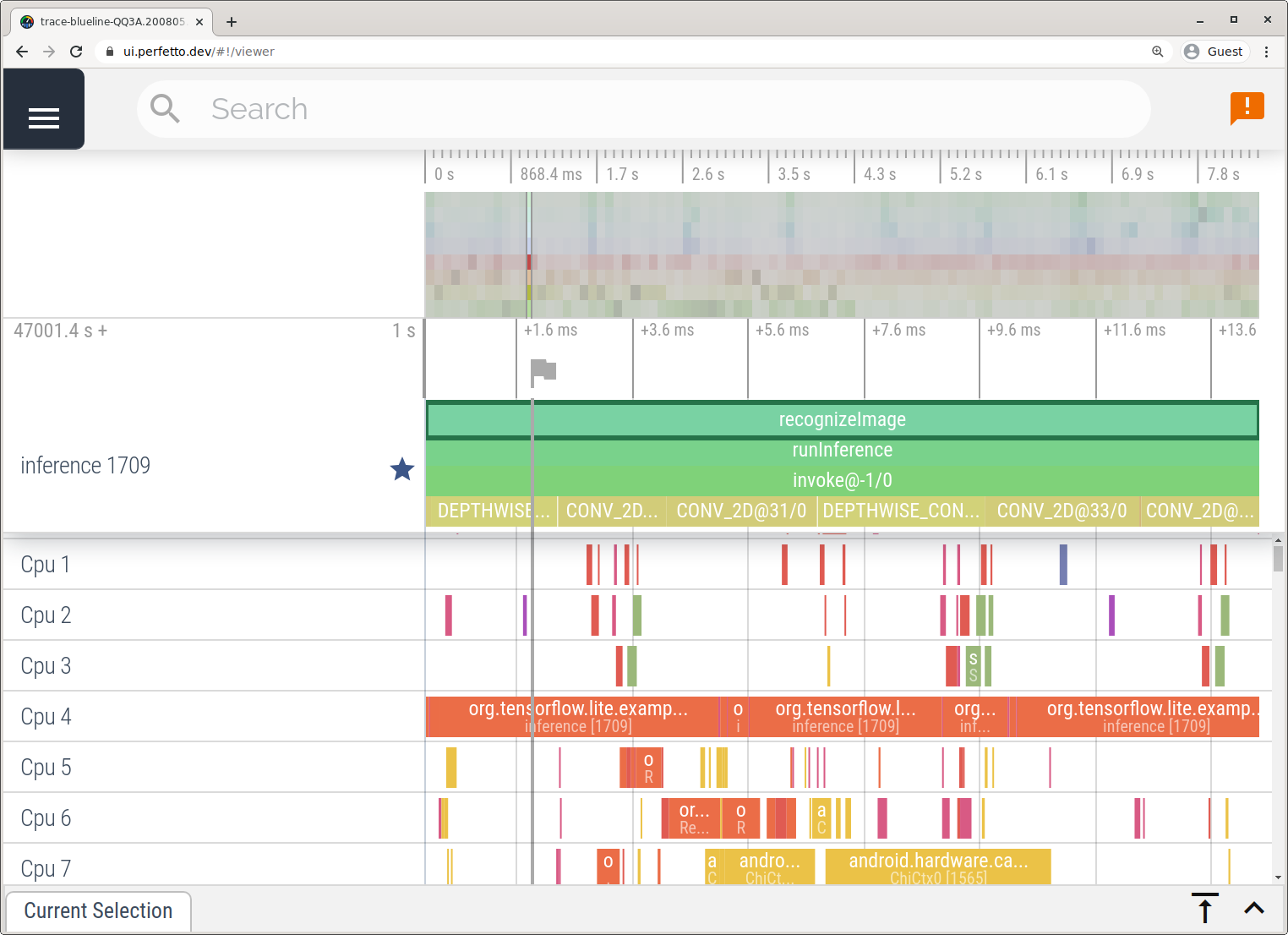
Erfassen Sie Traces ohne Android Studio, indem Sie die in der System Tracing-App beschriebenen Schritte ausführen.
In diesem Beispiel wurden dieselben TFLite-Ereignisse erfasst und je nach Android-Version im Perfetto- oder Systrace-Format gespeichert. Die erfassten Trace-Dateien können in der Perfetto-UI geöffnet werden.
TensorFlow Lite-Internes unter iOS verfolgen
Interne Ereignisse vom TensorFlow Lite-Interpreter einer iOS-App können vom Instruments-Tool erfasst werden, das in Xcode enthalten ist. Es handelt sich um die iOS-Wegweiser-Ereignisse, sodass die erfassten Ereignisse aus dem Swift-/Objective-C-Code zusammen mit den internen TensorFlow Lite-Ereignissen angezeigt werden.
Hier einige Beispiele für Ereignisse:
- Operatoraufruf
- Diagrammänderung durch Bevollmächtigten
- Tensor-Zuweisung
TensorFlow Lite-Tracing aktivieren
Legen Sie die Umgebungsvariable debug.tflite.trace so fest:
Wählen Sie in den oberen Menüs von Xcode Produkt > Schema > Schema bearbeiten... aus.
Klicken Sie im linken Bereich auf „Profil“.
Heben Sie die Auswahl des Kästchens "Use the run action's argument's and Um variables" (Argumente und Umgebungsvariablen der Ausführungsaktion verwenden) auf.
Fügen Sie im Bereich „Umgebungsvariablen“
debug.tflite.tracehinzu.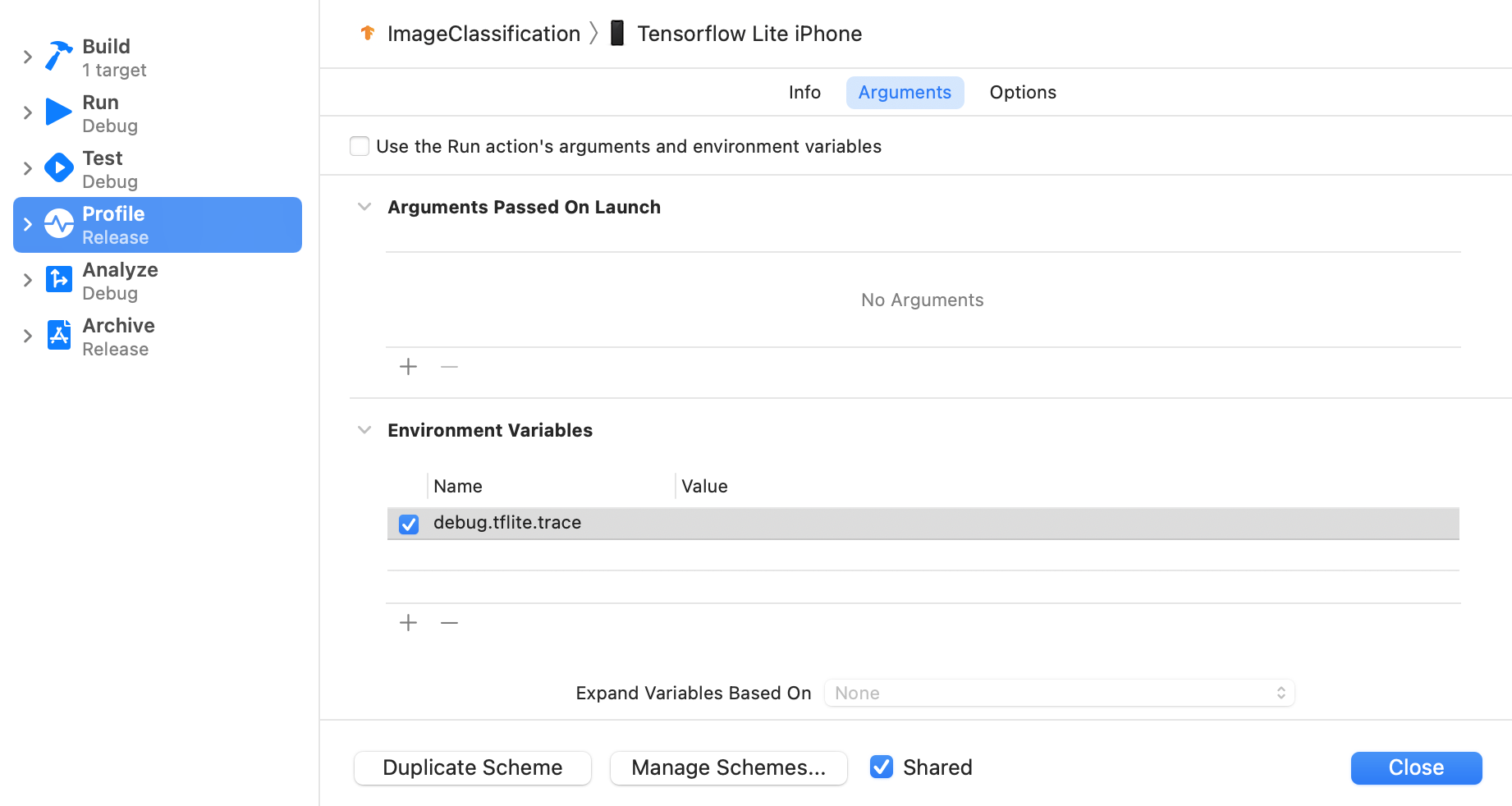
Wenn Sie TensorFlow Lite-Ereignisse bei der Profilerstellung für die iOS-App ausschließen möchten, deaktivieren Sie das Tracing, indem Sie die Umgebungsvariable entfernen.
XCode-Instrumente
So erfassen Sie Traces:
Wählen Sie aus den oberen Menüs von Xcode Product > Profile (Produkt > Profil) aus.
Klicken Sie beim Starten des Tools „Instruments“ unter den Profilerstellungsvorlagen auf Logging.
Drücke auf die Schaltfläche „Start“.
Drücken Sie die Schaltfläche „Stopp“.
Klicken Sie auf „os_signpost“, um die Elemente des OS Logging-Subsystems zu maximieren.
Klicken Sie auf „org.tensorflow.lite“ OS Logging-Subsystem.
Untersuchen Sie das Trace-Ergebnis.
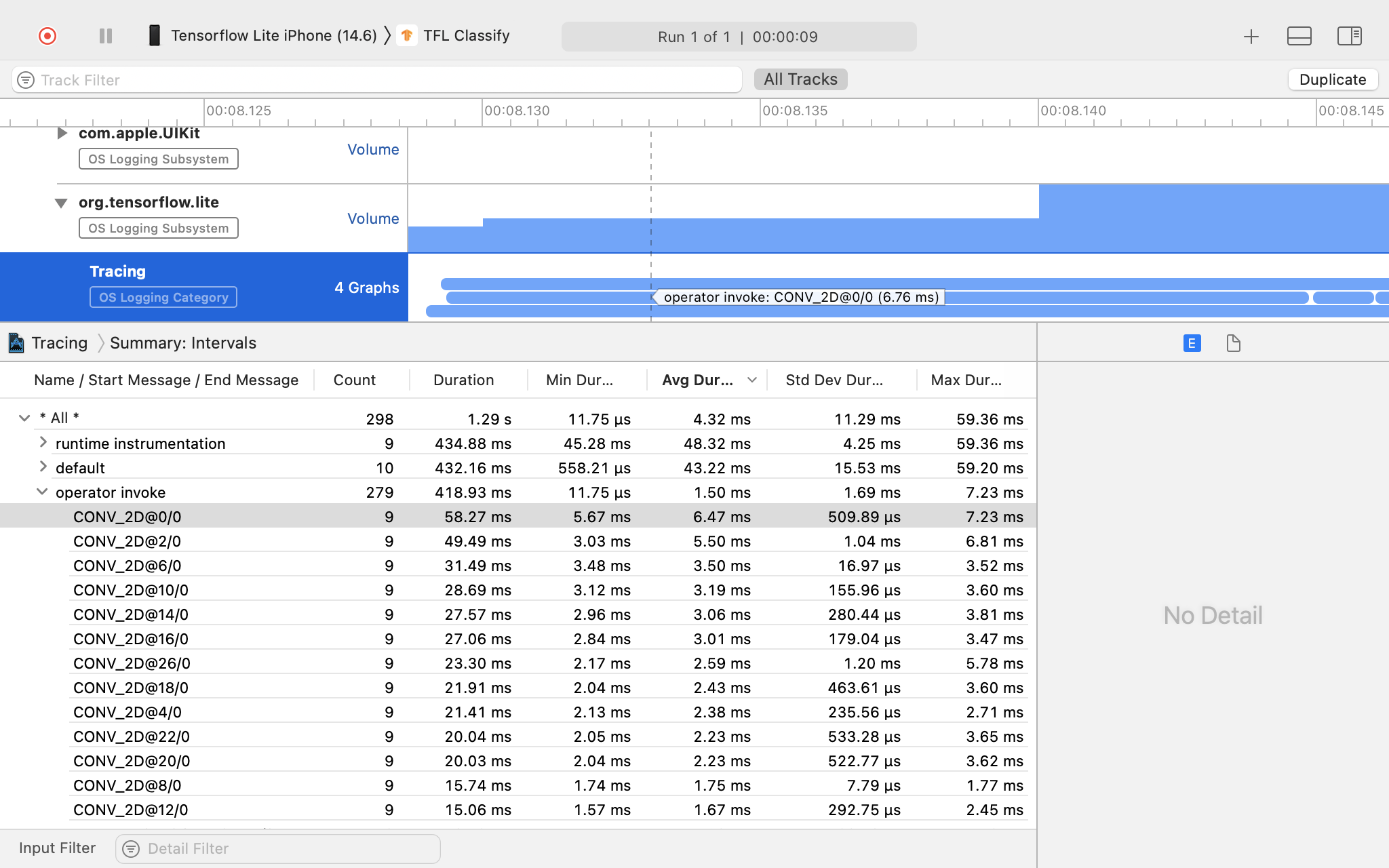
In diesem Beispiel sehen Sie die Hierarchie der Ereignisse und Statistiken für jede Operatorzeit.
Tracing-Daten verwenden
Die Nachverfolgungsdaten ermöglichen es Ihnen, Leistungsengpässe zu erkennen.
Hier sind einige Beispiele für Erkenntnisse, die Sie vom Profiler erhalten können, sowie mögliche Lösungen zur Leistungsverbesserung:
- Wenn die Anzahl der verfügbaren CPU-Kerne kleiner als die Anzahl der Inferenzthreads ist, kann der CPU-Planungsaufwand zu einer unterdurchschnittlichen Leistung führen. Sie können andere CPU-intensive Aufgaben in Ihrer Anwendung verschieben, um eine Überlappung mit der Modellinferenz zu vermeiden, oder die Anzahl der Interpreter-Threads optimieren.
- Wenn die Operatoren nicht vollständig delegiert sind, werden einige Teile der Modellgrafik auf der CPU und nicht auf dem erwarteten Hardwarebeschleuniger ausgeführt. Sie können die nicht unterstützten Operatoren durch ähnliche unterstützte Operatoren ersetzen.