
基准测试工具
TensorFlow Lite 基准工具目前可以测量和计算以下重要性能指标的统计信息:
- 初始化时间
- 推断预热状态的时间
- 推断稳定状态的时间
- 初始化期间的内存用量
- 总体内存用量
基准测试工具可用作 Android 和 iOS 基准应用以及原生命令行二进制文件,并且它们都共享相同的核心性能衡量逻辑。请注意,由于运行时环境中的差异,可用的选项和输出格式略有不同。
Android 基准应用
在 Android 应用中使用基准工具时,有两种方法可供选择。一个是原生基准二进制文件,另一个是 Android 基准应用,可以更好地衡量模型在应用中的表现。无论如何,基准工具中的数据都会与在实际应用中使用模型进行推断时的结果略有不同。
此 Android 基准应用没有界面。您可以使用 adb 命令安装并运行该软件包,并使用 adb logcat 命令检索结果。
下载或构建应用
使用以下链接下载每晚预构建的 Android 基准应用:
对于通过 Flex 委托支持 TF 操作的 Android 基准应用,请使用以下链接:
您还可以按照这些instructions从源代码构建应用。
准备基准
在运行基准应用之前,请按以下步骤安装该应用并将模型文件推送到设备:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
运行基准
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph 是必需参数。
graph:string
TFLite 模型文件的路径。
您可以为运行基准指定更多可选参数。
num_threads:int(默认值=1)
用于运行 TFLite 解释器的线程数。use_gpu:bool(default=false)
使用 GPU 代理。use_xnnpack:bool(默认值=false)
使用 XNNPACK 委托。
根据您所使用的设备,其中一些选项可能不可用或不起作用。如需详细了解可与基准应用一起运行的性能参数,请参阅参数。
使用 logcat 命令查看结果:
adb logcat | grep "Inference timings"
基准测试结果报告为:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
原生基准二进制文件
基准测试工具也作为原生二进制文件 benchmark_model 提供。您可以在 Linux、Mac、嵌入式设备和 Android 设备上通过 shell 命令行执行此工具。
下载或构建二进制文件
点击下面的链接可下载每晚预先构建的原生命令行二进制文件:
对于通过 Flex 委托支持 TF 操作的每晚预构建二进制文件,请使用以下链接:
您还可以在计算机上从源代码构建原生基准二进制文件。
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
如需使用 Android NDK 工具链进行构建,您需要先按照本指南设置构建环境,或者按照本指南中所述的方式使用 Docker 映像。
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
运行基准
如需在计算机上运行基准测试,请从 shell 执行二进制文件。
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
您可以将上面提到的同一组参数用于原生命令行二进制文件。
对模型操作进行性能分析
通过基准模型二进制文件,您还可以分析模型操作并获取每个运算符的执行时间。为此,请在调用期间将标志 --enable_op_profiling=true 传递给 benchmark_model。详见此处。
在一次运行中测试多个性能选项的原生基准二进制文件
此外,我们还提供了一个方便简单的 C++ 二进制文件,用于在一次运行中对多个性能选项进行基准测试。此二进制文件是基于上述基准工具构建的,该工具一次只能对一个性能选项进行基准测试。这些文件的构建/安装/运行流程相同,但此二进制文件的 build 目标名称为 benchmark_model_performance_options,并且需要一些额外的参数。
此二进制文件的一个重要参数是:
perf_options_list:string (default='all')
要进行基准测试的 TFLite 性能选项的逗号分隔列表。
您可以在每晚获取此工具的预构建二进制文件,如下所示:
iOS 基准应用
如需在 iOS 设备上运行基准测试,您需要从源代码构建应用。将 TensorFlow Lite 模型文件放在源代码树的 benchmark_data 目录中,并修改 benchmark_params.json 文件。这些文件会被打包到应用中,然后应用从该目录中读取数据。如需了解详细说明,请访问 iOS 基准应用。
知名模型的性能基准
本部分列出了在某些 Android 和 iOS 设备上运行已知模型时的 TensorFlow Lite 性能基准。
Android 性能基准
这些性能基准数据是使用原生基准二进制文件生成的。
对于 Android 基准测试,CPU 亲和性设置为在设备上使用大核心以减少方差(请参阅详细信息)。
它假定模型已下载并解压缩到 /data/local/tmp/tflite_models 目录。基准二进制文件根据这些说明构建,并假定位于 /data/local/tmp 目录中。
如需运行基准,请执行以下操作:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
如需使用 GPU 代理运行,请设置 --use_gpu=true。
以下性能值是在 Android 10 上衡量的。
| 模型名称 | 设备 | CPU,4 个线程 | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 毫秒 | 6.45 毫秒 |
| Pixel 4 | 14.0 毫秒 | 9.0 毫秒 | |
| Mobilenet_1.0_224(量化) | Pixel 3 | 13.4 毫秒 | --- |
| Pixel 4 | 5.0 毫秒 | --- | |
| NASNet 移动设备 | Pixel 3 | 56 毫秒 | --- |
| Pixel 4 | 34.5 毫秒 | --- | |
| SqueezeNet | Pixel 3 | 35.8 毫秒 | 9.5 毫秒 |
| Pixel 4 | 23.9 毫秒 | 11.1 毫秒 | |
| Inception_ResNet_V2 | Pixel 3 | 422 毫秒 | 99.8 毫秒 |
| Pixel 4 | 272.6 毫秒 | 87.2 毫秒 | |
| Inception_V4 | Pixel 3 | 486 毫秒 | 93 毫秒 |
| Pixel 4 | 324.1 毫秒 | 97.6 毫秒 |
iOS 性能基准
这些性能基准数据是使用 iOS 基准应用生成的。
为了运行 iOS 基准,我们修改了基准应用以包含适当的模型,并修改了 benchmark_params.json 以将 num_threads 设置为 2。为了使用 GPU 代理,我们还在 benchmark_params.json 中添加了 "use_gpu" : "1" 和 "gpu_wait_type" : "aggressive" 选项。
| 模型名称 | 设备 | CPU,2 个线程 | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 毫秒 | 3.4 毫秒 |
| Mobilenet_1.0_224(量化) | iPhone XS | 11 毫秒 | --- |
| NASNet 移动设备 | iPhone XS | 30.4 毫秒 | --- |
| SqueezeNet | iPhone XS | 21.1 毫秒 | 15.5 毫秒 |
| Inception_ResNet_V2 | iPhone XS | 261.1 毫秒 | 45.7 毫秒 |
| Inception_V4 | iPhone XS | 309 毫秒 | 54.4 毫秒 |
跟踪 TensorFlow Lite 内部构件
在 Android 中跟踪 TensorFlow Lite 内部构件
来自 Android 应用的 TensorFlow Lite 解释器的内部事件可由 Android 跟踪工具捕获。它们与 Android Trace API 中的事件相同,因此从 Java/Kotlin 代码中捕获的事件会与 TensorFlow Lite 内部事件一起显示。
部分事件示例如下:
- 运算符调用
- 通过委托方修改图表
- 张量分配
除了捕获跟踪记录的不同选项外,本指南还介绍了 Android Studio CPU 性能分析器和 System Tracing 应用。如需了解其他选项,请参阅 Perfetto 命令行工具或 Systrace 命令行工具。
在 Java 代码中添加跟踪事件
这是图片分类示例应用中的代码段。TensorFlow Lite 解释器在 recognizeImage/runInference 部分运行。此步骤是可选步骤,但有助于注意推断调用的执行位置。
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
启用 TensorFlow Lite 跟踪
如需启用 TensorFlow Lite 跟踪,请在启动 Android 应用之前将 Android 系统属性 debug.tflite.trace 设置为 1。
adb shell setprop debug.tflite.trace 1
如果在初始化 TensorFlow Lite 解释器时设置了此属性,则将跟踪来自解释器的关键事件(例如,运算符调用)。
捕获所有跟踪记录后,将属性值设置为 0 即可停用跟踪。
adb shell setprop debug.tflite.trace 0
Android Studio CPU 性能分析器
若要使用 Android Studio CPU 性能分析器捕获跟踪记录,请按以下步骤操作:
从顶部菜单中依次选择 Run > Profile 'app'。
当出现 Profiler 窗口时,点击 CPU 时间轴上的任意位置。
在 CPU 性能分析模式中选择“跟踪系统调用”。
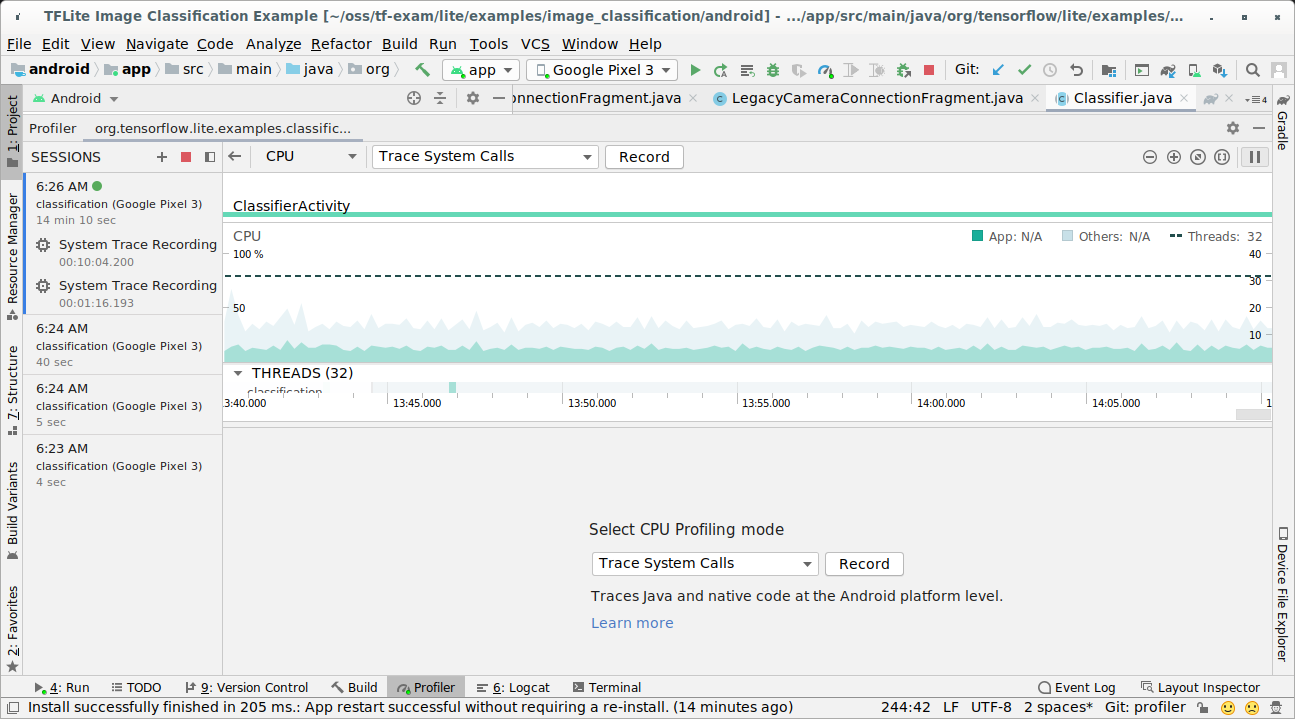
按“录制”按钮。
按“停止”按钮。
调查轨迹结果。
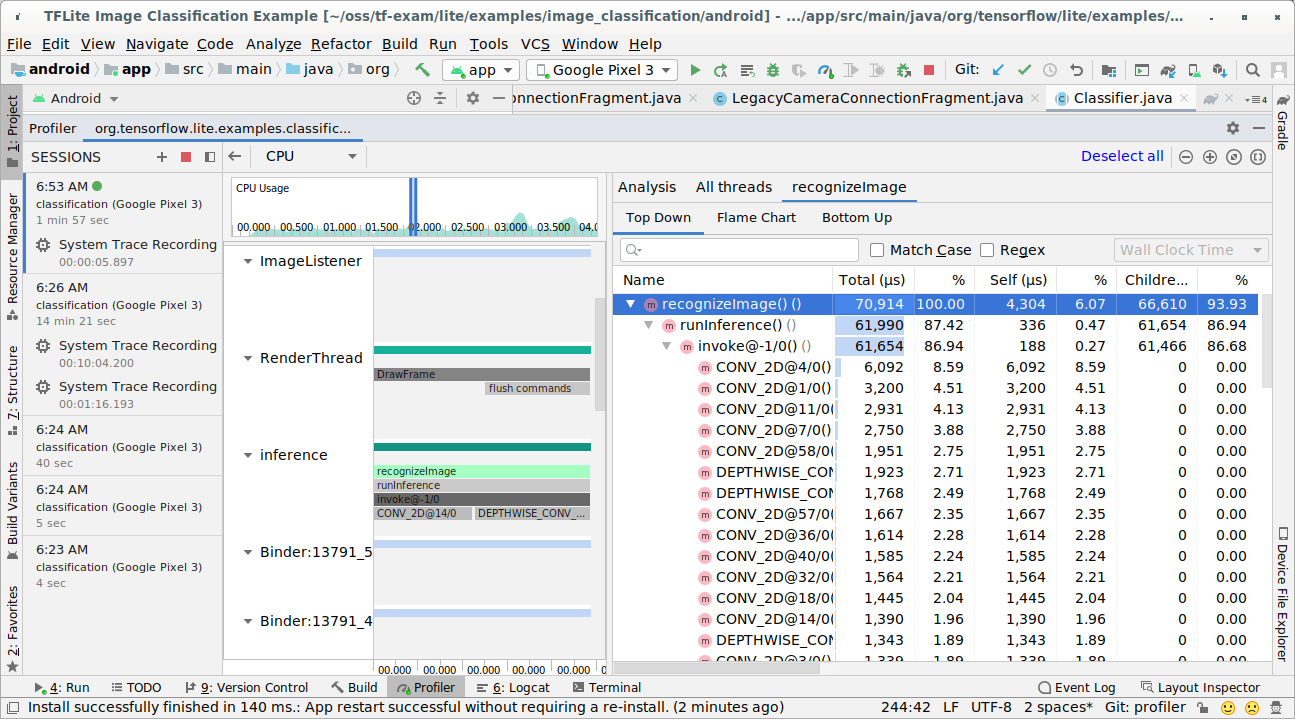
在此示例中,您可以查看线程中的事件层次结构和每个运算符时间的统计信息,还可以看到整个应用在各个线程之间的数据流。
“系统跟踪”应用
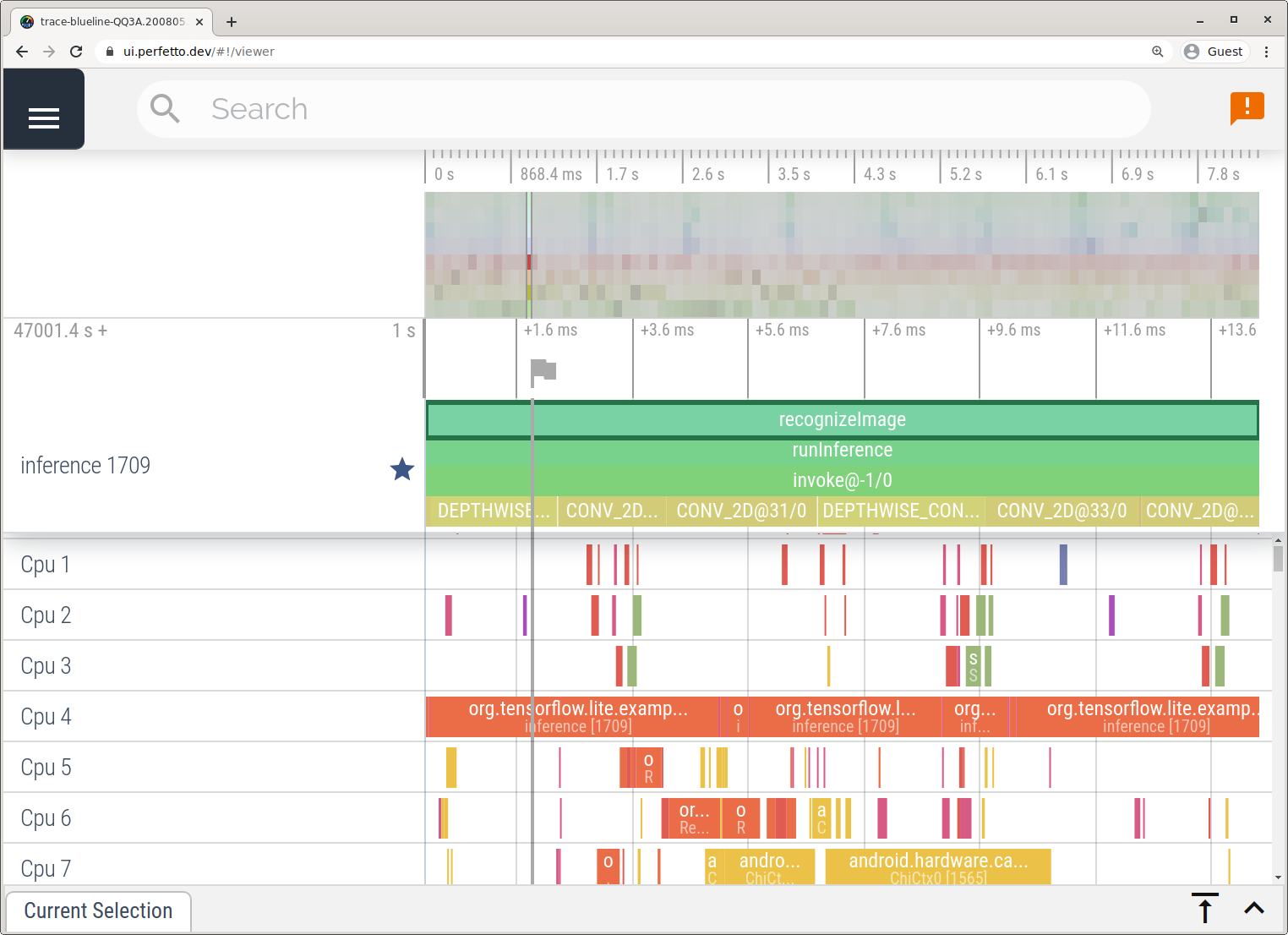
按照 System Tracing 应用中详述的步骤在不使用 Android Studio 的情况下捕获跟踪记录。
在此示例中,系统会捕获相同的 TFLite 事件,并将其保存为 Perfetto 或 Systrace 格式,具体取决于 Android 设备的版本。可以在 Perfetto 界面中打开捕获的轨迹文件。
在 iOS 中跟踪 TensorFlow Lite 内部结构
来自 iOS 应用的 TensorFlow Lite 解释器的内部事件可由 Xcode 随附的 Instruments 工具捕获。它们是 iOS 路标事件,因此从 Swift/Objective-C 代码捕获的事件会与 TensorFlow Lite 内部事件一起显示。
部分事件示例如下:
- 运算符调用
- 通过委托方修改图表
- 张量分配
启用 TensorFlow Lite 跟踪
按照以下步骤设置环境变量 debug.tflite.trace:
从 Xcode 的顶部菜单中,依次选择 Product > Scheme > Edit Scheme...。
点击左侧窗格中的“个人资料”。
取消选中“使用运行操作的参数和环境变量”复选框。
在“环境变量”部分下添加
debug.tflite.trace。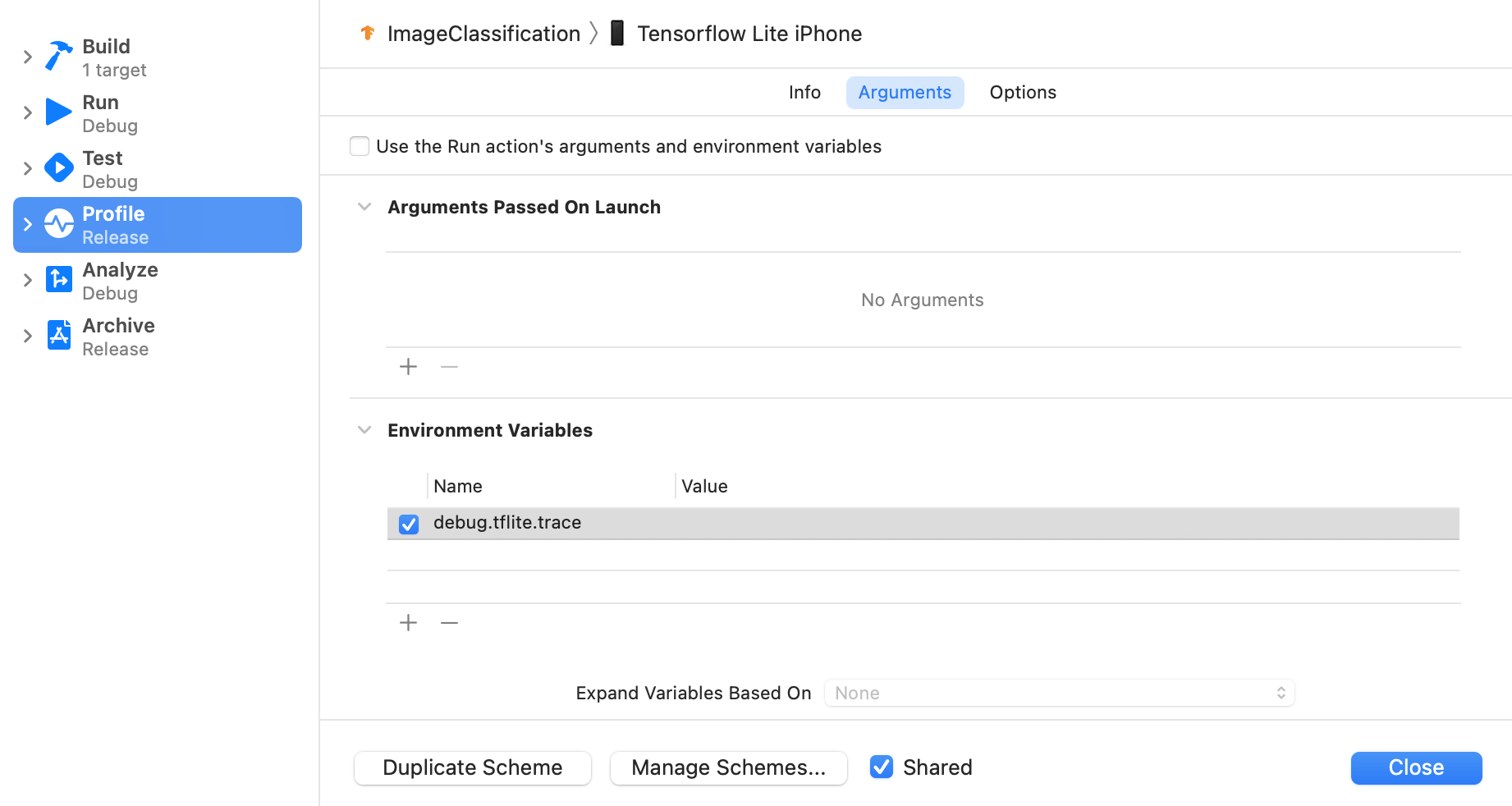
如果您想在分析 iOS 应用时排除 TensorFlow Lite 事件,请通过移除环境变量来停用跟踪。
Xcode 乐器
按照以下步骤捕获跟踪记录:
从 Xcode 的顶部菜单中选择 Product(产品)> Profile(配置文件)。
Instruments 工具启动时,在性能分析模板之间点击 Logging。
按“开始”按钮。
按“停止”按钮。
点击“os_signpost”以展开 OS Logging 子系统项。
点击“org.tensorflow.lite”OS Logging 子系统。
调查轨迹结果。
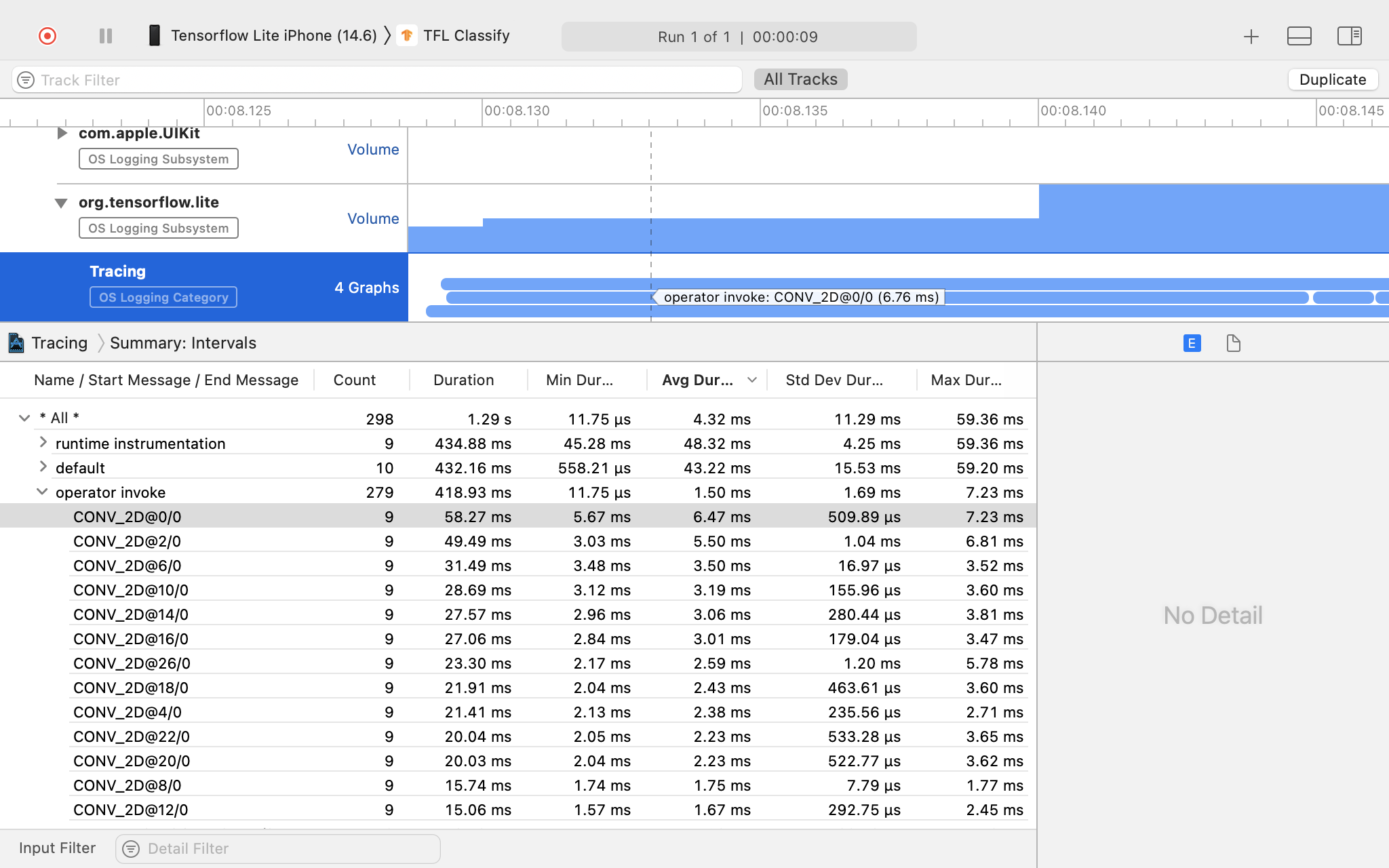
在以下示例中,您可以看到每个运算符时间的事件和统计信息的层次结构。
使用跟踪数据
通过跟踪数据,您可以识别性能瓶颈。
以下是一些您可以从性能分析器获取的数据分析示例,以及有助于提升性能的潜在解决方案:
- 如果可用 CPU 核心数少于推理线程数,则 CPU 调度开销可能会导致性能不佳。您可以重新调度应用中的其他 CPU 密集型任务,以避免与模型推断重叠,或者调整解释器线程的数量。
- 如果运算符未完全委托,则模型图的某些部分会在 CPU(而不是预期的硬件加速器)上执行。您可以将不受支持的运算符替换为受支持的类似运算符。