
ベンチマーク ツール
現在、TensorFlow Lite ベンチマーク ツールは、次の重要なパフォーマンス指標の統計情報を測定して計算します。
- 初期化時間
- ウォームアップ状態の推論時間
- 定常状態の推論時間
- 初期化中のメモリ使用量
- 全体的なメモリ使用量
ベンチマーク ツールは、Android と iOS のベンチマーク アプリ、およびネイティブ コマンドライン バイナリとして提供され、すべて同じコア パフォーマンス測定ロジックを共有します。ランタイム環境の違いにより、使用可能なオプションと出力形式は若干異なります。
Android ベンチマーク アプリ
Android でベンチマーク ツールを使用するには、2 つの方法があります。1 つはネイティブ ベンチマーク バイナリ、もう 1 つは Android ベンチマーク アプリです。アプリでのモデルのパフォーマンスをより正確に把握するためのものです。どちらの場合も、ベンチマーク ツールからの数値は、実際のアプリでモデルを使用して推論を実行する場合とわずかに異なります。
この Android ベンチマーク アプリには UI がありません。adb コマンドを使用してインストールして実行し、adb logcat コマンドを使用して結果を取得します。
アプリをダウンロードまたはビルドする
以下のリンクを使用して、夜間にビルドされた Android ベンチマーク アプリをダウンロードします。
Flex デリゲートを介して TF ops をサポートする Android ベンチマーク アプリについては、以下のリンクを使用してください。
こちらのinstructionsに沿って、ソースからアプリをビルドすることもできます。
ベンチマークを準備する
ベンチマーク アプリを実行する前に、次のようにアプリをインストールしてモデルファイルをデバイスにプッシュします。
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
ベンチマークを実行する
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph は必須パラメータです。
graph:string
TFLite モデルファイルのパス。
ベンチマークを実行するためのオプション パラメータをさらに指定できます。
num_threads:int(デフォルト=1)
TFLite インタープリタの実行に使用するスレッド数。use_gpu:bool(デフォルト=false)
GPU デリゲートを使用します。use_xnnpack:bool(デフォルト=false)
XNNPACK デリゲートを使用します。
お使いのデバイスによっては、これらのオプションの一部を使用できない場合や、機能しない場合があります。ベンチマーク アプリで実行できるその他のパフォーマンス パラメータについては、パラメータをご覧ください。
logcat コマンドを使用して結果を表示します。
adb logcat | grep "Inference timings"
ベンチマーク結果は次のようにレポートされます。
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
ネイティブ ベンチマーク バイナリ
ベンチマーク ツールは、ネイティブ バイナリの benchmark_model としても提供されています。このツールは、Linux、Mac、組み込みデバイス、Android デバイスのシェル コマンドラインから実行できます。
バイナリをダウンロードまたはビルドする
以下のリンクから、ナイトリーにビルドされたネイティブ コマンドライン バイナリをダウンロードします。
Flex デリゲートを介して TF ops をサポートする夜間のビルド済みバイナリについては、以下のリンクを使用します。
パソコンのソースからネイティブ ベンチマーク バイナリをビルドすることもできます。
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Android NDK ツールチェーンを使用してビルドするには、このガイドに沿ってビルド環境を設定するか、このガイドで説明されているように Docker イメージを使用する必要があります。
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
ベンチマークを実行する
パソコンでベンチマークを実行するには、シェルからバイナリを実行します。
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
ネイティブ コマンドライン バイナリでは、上記と同じパラメータ セットを使用できます。
モデル オペレーションのプロファイリング
ベンチマーク モデルバイナリを使用すると、モデル オペレーションをプロファイリングし、各演算子の実行時間を取得することもできます。これを行うには、呼び出し時にフラグ --enable_op_profiling=true を benchmark_model に渡します。詳しくは、こちらをご覧ください。
1 回の実行で複数のパフォーマンス オプションに対応するネイティブ ベンチマーク バイナリ
1 回の実行で複数のパフォーマンス オプションのベンチマークを行うための便利でシンプルな C++ バイナリも用意されています。このバイナリは、一度に 1 つのパフォーマンス オプションしかベンチマークできない前述のベンチマーク ツールに基づいて作成されています。これらのバイナリは同じビルド/インストール/実行プロセスを共有しますが、このバイナリの BUILD ターゲット名は benchmark_model_performance_options で、いくつかの追加パラメータを受け取ります。このバイナリの重要なパラメータは次のとおりです。
perf_options_list: string(default='all')
ベンチマーク対象の TFLite パフォーマンス オプションのカンマ区切りのリスト。
以下のように、このツールの夜間にビルド済みのバイナリを取得できます。
iOS ベンチマーク アプリ
iOS デバイスでベンチマークを実行するには、ソースからアプリをビルドする必要があります。TensorFlow Lite モデルファイルをソースツリーの benchmark_data ディレクトリに配置し、benchmark_params.json ファイルを変更します。これらのファイルはアプリにパッケージ化され、アプリはディレクトリからデータを読み取ります。詳しい手順については、iOS ベンチマーク アプリをご覧ください。
既知のモデルのパフォーマンス ベンチマーク
このセクションでは、一部の Android デバイスと iOS デバイスで既知のモデルを実行する場合の TensorFlow Lite のパフォーマンス ベンチマークを示します。
Android のパフォーマンス ベンチマーク
これらのパフォーマンス ベンチマークの数値は、ネイティブ ベンチマーク バイナリで生成されました。
Android ベンチマークでは、デバイス上の大きなコアを使用してばらつきを減らすように CPU アフィニティが設定されています(詳細)。
モデルが /data/local/tmp/tflite_models ディレクトリにダウンロードされ、解凍されたことを前提としています。ベンチマーク バイナリは、こちらの手順に沿ってビルドされ、/data/local/tmp ディレクトリにあることを前提としています。
ベンチマークを実行するには:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
GPU デリゲートで実行するには、--use_gpu=true を設定します。
以下のパフォーマンス値は Android 10 で測定された値です。
| モデル名 | デバイス | CPU、4 スレッド | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Google Pixel 3 | 23.9 ミリ秒 | 6.45 ミリ秒 |
| Google Pixel 4 | 14.0 ミリ秒 | 9.0 ミリ秒 | |
| Mobilenet_1.0_224(quant) | Google Pixel 3 | 13.4 ミリ秒 | --- |
| Google Pixel 4 | 5.0 ミリ秒 | --- | |
| NASNet モバイル | Google Pixel 3 | 56 ミリ秒 | --- |
| Google Pixel 4 | 34.5 ミリ秒 | --- | |
| SqueezeNet | Google Pixel 3 | 35.8 ミリ秒 | 9.5 ミリ秒 |
| Google Pixel 4 | 23.9 ミリ秒 | 11.1 ミリ秒 | |
| Inception_ResNet_V2 | Google Pixel 3 | 422 ミリ秒 | 99.8 ミリ秒 |
| Google Pixel 4 | 272.6 ミリ秒 | 87.2 ミリ秒 | |
| Inception_V4 | Google Pixel 3 | 486 ミリ秒 | 93 ミリ秒 |
| Google Pixel 4 | 324.1 ミリ秒 | 97.6 ミリ秒 |
iOS のパフォーマンス ベンチマーク
これらのパフォーマンス ベンチマークの数値は、iOS ベンチマーク アプリで生成されたものです。
iOS ベンチマークを実行するために、適切なモデルを含めるようにベンチマーク アプリを変更し、num_threads を 2 に設定するように benchmark_params.json を変更しました。GPU デリゲートを使用するために、"use_gpu" : "1" オプションと "gpu_wait_type" : "aggressive" オプションも benchmark_params.json に追加されました。
| モデル名 | デバイス | CPU、2 スレッド | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 ミリ秒 | 3.4 ミリ秒 |
| Mobilenet_1.0_224(quant) | iPhone XS | 11 ミリ秒 | --- |
| NASNet モバイル | iPhone XS | 30.4 ミリ秒 | --- |
| SqueezeNet | iPhone XS | 21.1 ミリ秒 | 15.5 ミリ秒 |
| Inception_ResNet_V2 | iPhone XS | 261.1 ミリ秒 | 45.7 ミリ秒 |
| Inception_V4 | iPhone XS | 309 ミリ秒 | 54.4 ミリ秒 |
TensorFlow Lite の内部をトレースする
Android で TensorFlow Lite の内部をトレースする
Android アプリの TensorFlow Lite インタープリタからの内部イベントは、Android トレースツールでキャプチャできます。これらは Android Trace API と同じイベントであるため、Java/Kotlin コードからキャプチャされたイベントは、TensorFlow Lite の内部イベントと一緒に表示されます。
イベントの例を以下に示します。
- 演算子の呼び出し
- 委譲によるグラフ変更
- テンソルの割り当て
このガイドでは、トレースをキャプチャするためのさまざまなオプションのうち、Android Studio の CPU Profiler と System Tracing アプリについて説明します。その他のオプションについては、Perfetto コマンドライン ツールまたは Systrace コマンドライン ツールをご覧ください。
Java コードにトレース イベントを追加する
これは、画像分類サンプルアプリのコード スニペットです。TensorFlow Lite インタープリタは recognizeImage/runInference セクションで実行されます。このステップは省略可能ですが、推論呼び出しが行われる場所を確認するのに役立ちます。
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
TensorFlow Lite トレースを有効にする
TensorFlow Lite トレースを有効にするには、Android アプリを起動する前に Android システム プロパティ debug.tflite.trace を 1 に設定します。
adb shell setprop debug.tflite.trace 1
TensorFlow Lite インタープリタの初期化時にこのプロパティが設定されている場合、インタープリタからのキーイベント(オペレーターの呼び出しなど)がトレースされます。
すべてのトレースをキャプチャしたら、プロパティ値を 0 に設定してトレースを無効にします。
adb shell setprop debug.tflite.trace 0
Android Studio の CPU Profiler
Android Studio の CPU Profiler でトレースをキャプチャする手順は次のとおりです。
上部のメニューから [Run] > [Profile 'app'] を選択します。
Profiler ウィンドウが表示されたら、CPU タイムラインの任意の場所をクリックします。
CPU プロファイリング モードの中から [Trace System Calls] を選択します。
![[システムコールをトレース] を選択してください](https://ai.google.dev/edge/lite/images/models/as_select_profiling_mode.png?authuser=2&hl=ja)
[録画] ボタンを押します。
[停止] ボタンを押します。
トレース結果を調べます。
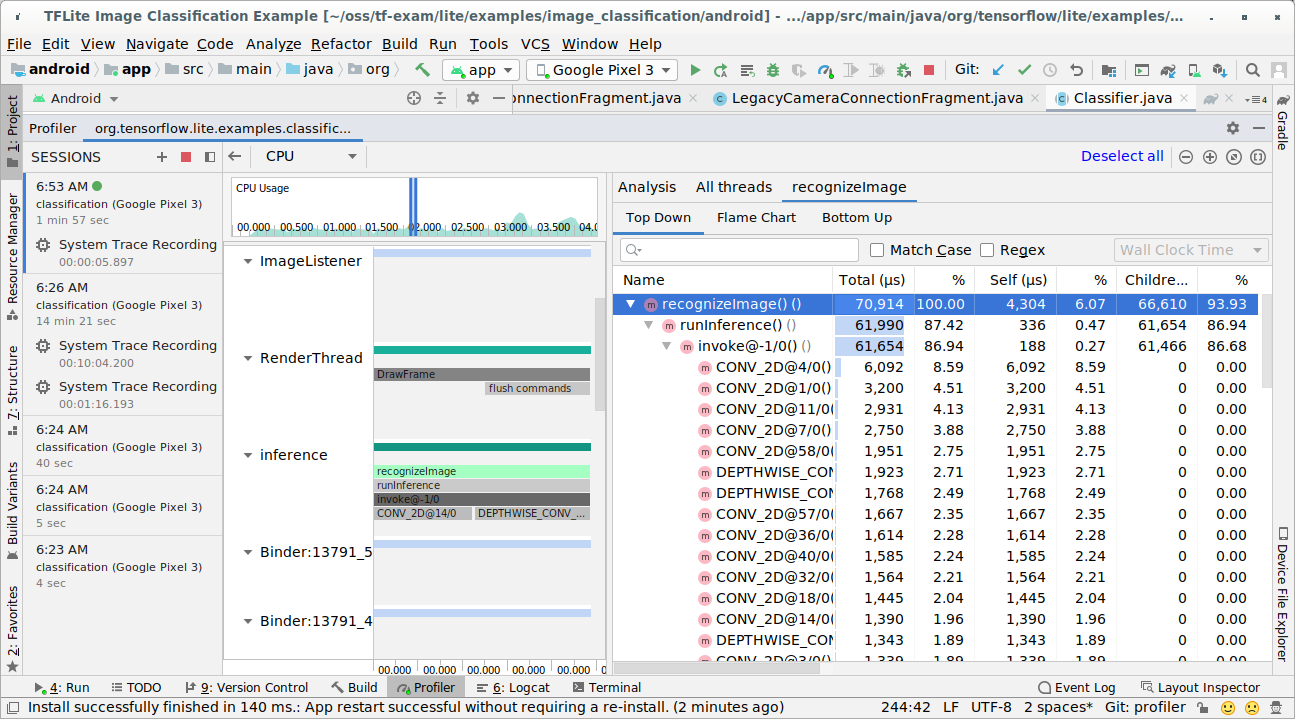
この例では、スレッド内のイベントの階層と各演算子の時間の統計情報を表示し、スレッド間のアプリ全体のデータフローを確認できます。
System Tracing アプリ
System Tracing アプリで説明されている手順に沿って、Android Studio を使用せずにトレースをキャプチャします。
この例では、同じ TFLite イベントがキャプチャされ、Android デバイスのバージョンに応じて Perfetto 形式または Systrace 形式に保存されています。キャプチャされたトレース ファイルは Perfetto UI で開くことができます。
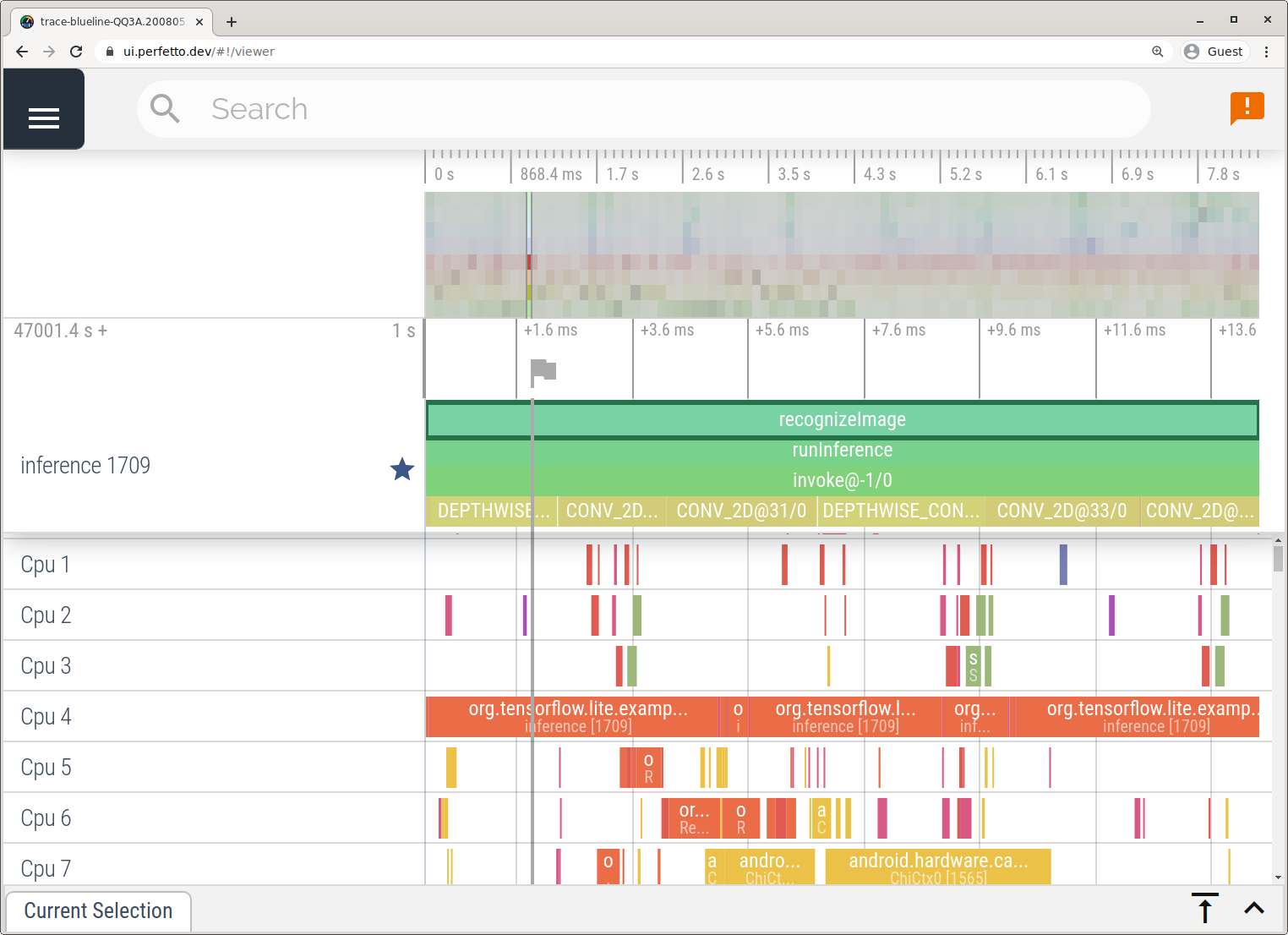
iOS で TensorFlow Lite の内部をトレースする
iOS アプリの TensorFlow Lite インタープリタからの内部イベントは、Xcode に付属する Instruments ツールでキャプチャできます。これらは iOS の signpost イベントであるため、Swift/Objective-C コードからキャプチャされたイベントは、TensorFlow Lite の内部イベントと一緒に表示されます。
イベントの例を以下に示します。
- 演算子の呼び出し
- 委譲によるグラフ変更
- テンソルの割り当て
TensorFlow Lite トレースを有効にする
次の手順に沿って環境変数 debug.tflite.trace を設定します。
Xcode のトップメニューから [Product] > [Scheeme] > [Edit Scheme...] の順に選択します。
左側のペインの [プロファイル] をクリックします。
[Run アクションの引数と環境変数を使用する] チェックボックスをオフにします。
[環境変数] セクションに
debug.tflite.traceを追加します。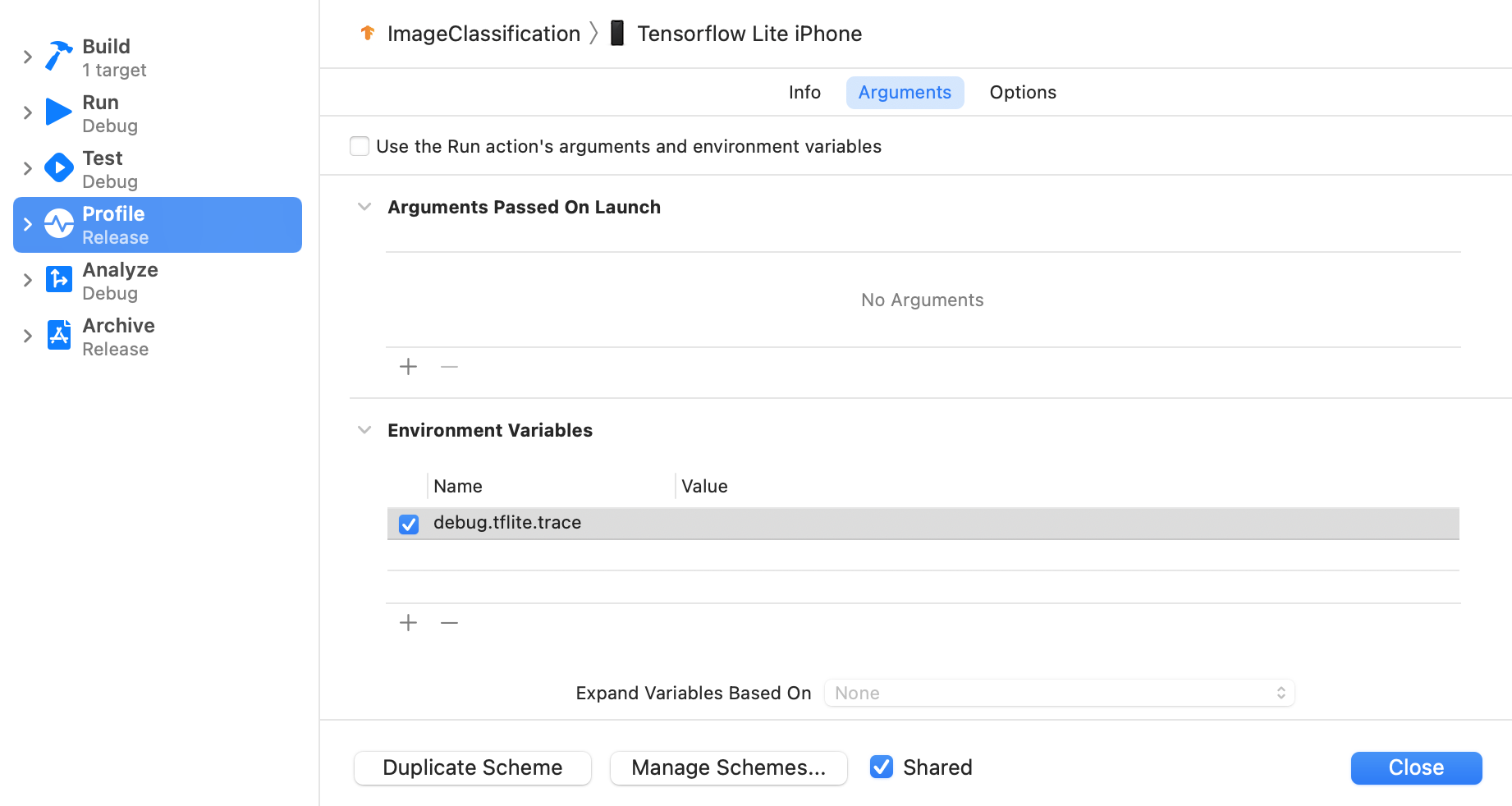
iOS アプリのプロファイリング時に TensorFlow Lite イベントを除外する場合は、環境変数を削除してトレースを無効にします。
XCode インストゥルメント
トレースをキャプチャする手順は次のとおりです。
Xcode のトップメニューから [Product] > [Profile] を選択します。
Instruments ツールが起動したら、プロファイリング テンプレートの [Logging] をクリックします。
[開始] ボタンを押します。
[停止] ボタンを押します。
[os_signpost] をクリックして、OS Logging のサブシステム アイテムを展開します。
OS Logging サブシステム「org.tensorflow.lite」をクリックします。
トレース結果を調べます。
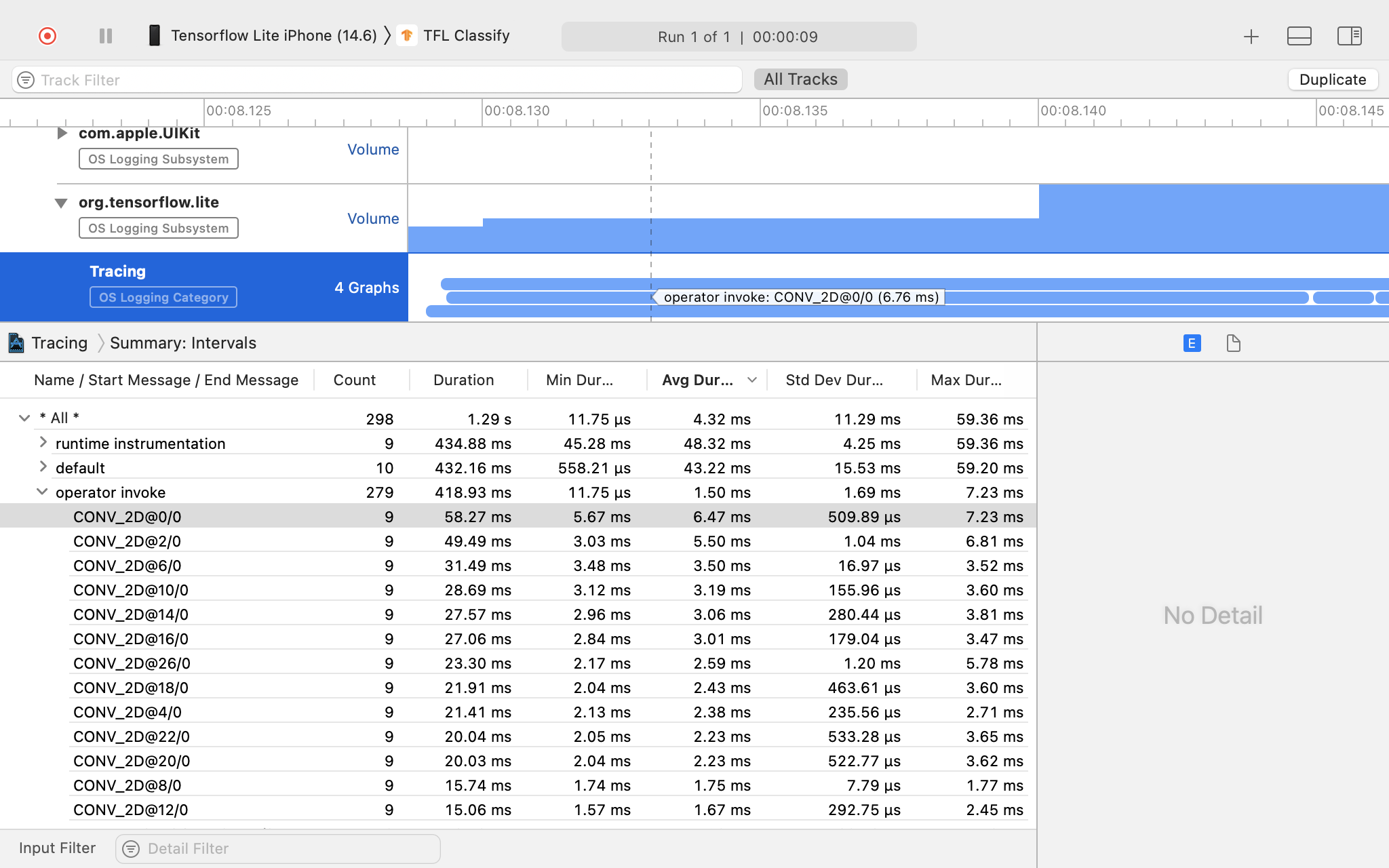
この例では、演算子の時間ごとにイベントと統計情報の階層を確認できます。
トレースデータの使用
トレースデータを使用すると、パフォーマンスのボトルネックを特定できます。
プロファイラから得られる分析情報の例と、パフォーマンス向上のための解決策を次に示します。
- 使用可能な CPU コアの数が推論スレッドの数よりも少ない場合、CPU スケジューリングのオーバーヘッドによって、パフォーマンスが平均を下回る可能性があります。アプリケーションで他の CPU 負荷の高いタスクのスケジュールを変更して、モデル推論との重複を回避したり、インタープリタのスレッド数を調整したりできます。
- 演算子が完全に委任されていない場合、モデルグラフの一部は、想定されるハードウェア アクセラレータではなく CPU で実行されます。サポートされていない演算子は、サポートされている同様の演算子に置き換えることができます。