
המטא-נתונים של LiteRT מספקים תקן לתיאורי מודלים. המטא-נתונים הם מקור חשוב למידע על הפעולות שהמודל מבצע ועל נתוני הקלט והפלט שלו. המטא-נתונים מורכבים גם מ
- חלקים שקלים לקריאה ומעבירים את השיטה המומלצת לשימוש במודל, ו
- חלקים שניתנים לקריאה על ידי מכונה, שאפשר להשתמש בהם באמצעות מחוללי קודים, כמו מחולל הקודים LiteRT Android והתכונה Android Studio ML Binding.
כל מודלי התמונות שפורסמו ב-Kaggle Models כוללים מטא נתונים.
מודל עם פורמט מטא-נתונים
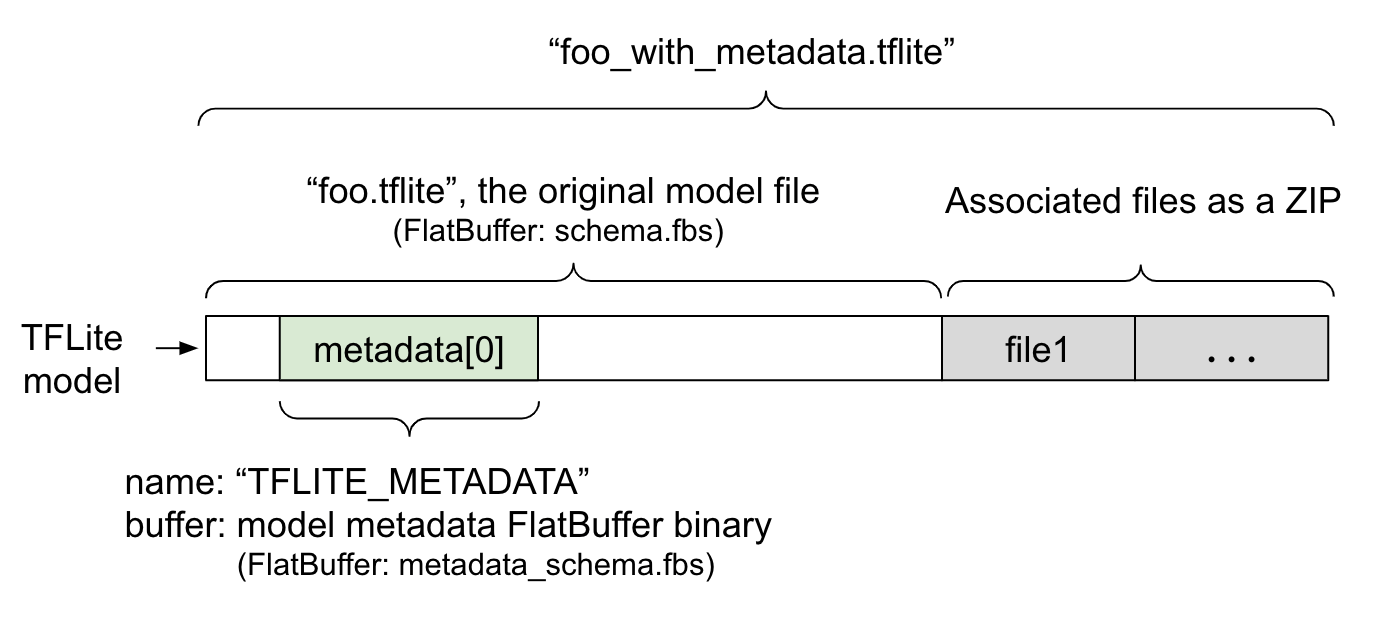
המטא-נתונים של המודל מוגדרים בקובץ metadata_schema.fbs, שהוא קובץ FlatBuffer. כפי שמוצג באיור 1, הוא מאוחסן בשדה metadata של סכימת מודל TFLite, בשם "TFLITE_METADATA". יכול להיות שחלק מהמודלים יגיעו עם קבצים משויכים, כמו קבצים של תוויות סיווג.
הקבצים האלה מצורפים לסוף קובץ המודל המקורי כקובץ ZIP באמצעות מצב append ('a') של ZipFile. ה-Interpreter של TFLite יכול לעבד את פורמט הקובץ החדש באותו אופן כמו קודם. מידע נוסף זמין במאמר בנושא אריזת הקבצים המשויכים.
בהמשך מפורטות הוראות להוספה, להצגה ולקריאה של מטא-נתונים.
הגדרת כלי המטא-נתונים
לפני שמוסיפים מטא-נתונים למודל, צריך להגדיר סביבת תכנות ב-Python להרצת TensorFlow. כאן אפשר למצוא מדריך מפורט להגדרת התכונה הזו.
אחרי שמגדירים את סביבת התכנות בשפת Python, צריך להתקין כלי עזר נוספים:
pip install tflite-support
כלי המטא-נתונים של LiteRT תומכים ב-Python 3.
הוספת מטא-נתונים באמצעות Flatbuffers Python API
יש שלושה חלקים למטא-נתונים של המודל בסכימה:
- פרטי המודל – תיאור כללי של המודל ושל פריטים כמו תנאי הרישיון. ModelMetadata 2. הזנת מידע – תיאור של הקלט ושל העיבוד המקדים שנדרש, כמו נורמליזציה. מידע נוסף זמין במאמר בנושא SubGraphMetadata.input_tensor_metadata. 3. מידע על הפלט – תיאור של הפלט ושל העיבוד שלאחר מכן שנדרש, כמו מיפוי לתוויות. מידע נוסף זמין במאמר בנושא SubGraphMetadata.output_tensor_metadata.
מכיוון ש-LiteRT תומך כרגע רק בתת-גרף יחיד, מחולל הקוד של LiteRTוהתכונה Android Studio ML Bindingישתמשו ב-ModelMetadata.name וב-ModelMetadata.description במקום ב-SubGraphMetadata.name וב-SubGraphMetadata.description, כשהם מציגים מטא-נתונים ומפיקים קוד.
סוגי הקלט והפלט הנתמכים
המטא נתונים של LiteRT לקלט ולפלט לא מיועדים לסוגים ספציפיים של מודלים, אלא לסוגים של קלט ופלט. לא משנה מה הפונקציה של המודל, כל עוד סוגי הקלט והפלט כוללים את האפשרויות הבאות או שילוב שלהן, המודל נתמך על ידי מטא-נתונים של TensorFlow Lite:
- תכונה – מספרים שהם מספרים שלמים לא מסומנים או float32.
- תמונה – מטא-נתונים תומכים כרגע בתמונות RGB ובגווני אפור.
- תיבה תוחמת (bounding box) – תיבות תוחמות בצורת מלבן. הסכימה תומכת במגוון של תוכניות מספור.
אריזת הקבצים המשויכים
יכול להיות שלמודלים של LiteRT יצורפו קבצים שונים. לדוגמה, למודלים של שפה טבעית יש בדרך כלל קובצי אוצר מילים שממפים חלקי מילים למזהי מילים. למודלים של סיווג יכולים להיות קובצי תוויות שמציינים קטגוריות של אובייקטים. אם אין קבצים משויכים (אם יש כאלה), המודל לא יפעל בצורה טובה.
עכשיו אפשר לארוז את הקבצים המשויכים עם המודל באמצעות ספריית המטא-נתונים של Python. מודל LiteRT החדש הופך לקובץ ZIP שמכיל את המודל ואת הקבצים המשויכים. אפשר לפתוח אותו באמצעות כלים נפוצים לפתיחת קובצי ZIP. פורמט המודל החדש הזה ממשיך להשתמש באותה סיומת קובץ, .tflite. הוא תואם למסגרת ולמתורגמן הקיימים של TFLite. פרטים נוספים זמינים במאמר בנושא אריזת מטא-נתונים וקבצים משויכים במודל.
אפשר לתעד את פרטי הקובץ המשויך במטא-נתונים. בהתאם לסוג הקובץ ולמקום שבו הקובץ מצורף (כלומר, ModelMetadata, SubGraphMetadata ו-TensorMetadata), מחולל הקוד LiteRT Android עשוי להחיל באופן אוטומטי על האובייקט עיבוד מקדים או עיבוד שאחרי. פרטים נוספים זמינים בקטע <Codegen usage> של כל סוג קובץ משויך בסכימה.
פרמטרים של נורמליזציה וקוונטיזציה
נרמול הוא טכניקה נפוצה לעיבוד מקדים של נתונים בלמידת מכונה. המטרה של הנרמול היא לשנות את הערכים לסולם משותף, בלי לעוות את ההבדלים בטווחים של הערכים.
קוונטיזציה של מודלים היא טכניקה שמאפשרת ייצוגים של משקלים ופעולות הפעלה (אופציונלי) עם דיוק מופחת, לצורך אחסון וחישוב.
מבחינת עיבוד מראש ועיבוד אחרי, נורמליזציה וקוונטיזציה הם שני שלבים נפרדים. הנה הפרטים.
| נירמול | קוונטיזציה | |
|---|---|---|
דוגמה לערכי הפרמטרים של תמונת הקלט ב-MobileNet עבור מודלים של float ו-quant, בהתאמה. |
מודל float: - mean: 127.5 - std: 127.5 מודל quant: - mean: 127.5 - std: 127.5 |
מודל float: - zeroPoint: 0 - scale: 1.0 מודל quant: - zeroPoint: 128.0 - scale:0.0078125f |
מתי להפעיל את הפונקציה? |
נתוני קלט: אם נתוני הקלט מנורמלים בתהליך האימון, נתוני הקלט של ההסקה צריכים להיות מנורמלים בהתאם. פלט: נתוני הפלט לא יעברו נורמליזציה באופן כללי. |
מודלים של מספרים ממשיים לא צריכים כימות. מודל שעבר קוונטיזציה עשוי לדרוש קוונטיזציה בעיבוד המקדים או בעיבוד שלאחר מכן, או שלא לדרוש קוונטיזציה בכלל. הוא תלוי בסוג הנתונים של טנסורים של קלט/פלט. - טנסורים של מספרים ממשיים: לא נדרשת קוונטיזציה בעיבוד המקדים או בעיבוד שאחרי. פעולות Quant ו-dequant מוטמעות בגרף המודל. - טנסורים מסוג int8/uint8: צריך לבצע קוונטיזציה בעיבוד המקדים או בעיבוד שלאחר מכן. |
נוסחה |
normalized_input = (input - mean) / std |
Quantize for inputs:
q = f / scale + zeroPoint Dequantize for outputs: f = (q - zeroPoint) * scale |
איפה נמצאים הפרמטרים |
הערך הזה נקבע על ידי יוצר המודל ונשמר במטא-נתונים של המודל, בתור NormalizationOptions |
השדה הזה מתמלא אוטומטית על ידי כלי ההמרה של TFLite, והוא מאוחסן בקובץ המודל של TFLite. |
| איך מקבלים את הפרמטרים? | באמצעות MetadataExtractor API
[2]
|
באמצעות TFLite
Tensor API [1] או
באמצעות
MetadataExtractor API
[2] |
| האם למודלים של float ו-quant יש אותו ערך? | כן, למודלים של float ולמודלים של quant יש אותם פרמטרים של Normalization | לא, אין צורך בקוונטיזציה של מודל float. |
| האם מחולל הקוד של TFLite או הקישור של Android Studio ML יוצרים אותו באופן אוטומטי בעיבוד הנתונים? | כן |
כן |
[1] LiteRT Java API ו-LiteRT C++ API.
[2] ספריית חילוץ המטא-נתונים
כשמעבדים נתוני תמונות למודלים מסוג uint8, לפעמים מדלגים על נורמליזציה וקוונטיזציה. אפשר לעשות את זה אם ערכי הפיקסלים הם בטווח [0, 255]. אבל באופן כללי, תמיד צריך לעבד את הנתונים בהתאם לפרמטרים של הנורמליזציה והכימות, כשזה רלוונטי.
דוגמאות
כאן אפשר לראות דוגמאות לאופן שבו צריך לאכלס את המטא-נתונים עבור סוגים שונים של מודלים:
סיווג תמונות
מורידים את הסקריפט כאן, שמאכלס מטא-נתונים ב-mobilenet_v1_0.75_160_quantized.tflite. מריצים את הסקריפט כך:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
כדי לאכלס מטא-נתונים עבור מודלים אחרים לסיווג תמונות, מוסיפים את מפרטי המודל כמו כאן לסקריפט. בהמשך המדריך הזה נדגיש כמה מהקטעים העיקריים בדוגמה של סיווג תמונות, כדי להמחיש את האלמנטים העיקריים.
ניתוח מעמיק של הדוגמה לסיווג תמונות
פרטי דגם
כדי ליצור מטא-נתונים, קודם צריך ליצור מידע על מודל חדש:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
מידע על קלט ופלט
בקטע הזה מוסבר איך לתאר את חתימת הקלט והפלט של המודל. יכול להיות שגנרטורים אוטומטיים של קוד ישתמשו במטא נתונים האלה כדי ליצור קוד לעיבוד לפני ואחרי. כדי ליצור מידע על טנסור כקלט או כפלט:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
קלט של תמונה
תמונה היא סוג קלט נפוץ ללמידת מכונה. מטא-נתונים של LiteRT תומכים במידע כמו מרחב צבעים ומידע על עיבוד מקדים כמו נורמליזציה. אין צורך לציין את המימד של התמונה באופן ידני, כי הוא כבר מסופק על ידי הצורה של טנסור הקלט ואפשר להסיק אותו באופן אוטומטי.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
פלט התווית
אפשר למפות את התווית לטנסור פלט באמצעות קובץ משויך באמצעות TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
יצירת מטא נתונים של Flatbuffers
בדוגמה הבאה אפשר לראות איך משלבים את פרטי המודל עם פרטי הקלט והפלט:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
המודל מקבל מטא-נתונים של חבילות וקבצים משויכים
אחרי שיוצרים את המטא-נתונים של Flatbuffers, המטא-נתונים וקובץ התוויות נכתבים בקובץ TFLite באמצעות השיטה populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
אפשר להוסיף למודל כמה קבצים משויכים שרוצים באמצעות load_associated_files. עם זאת, חובה לארוז לפחות את הקבצים שמפורטים במטא-נתונים. בדוגמה הזו, חובה לארוז את קובץ התוויות.
המחשה של המטא-נתונים
אפשר להשתמש ב-Netron כדי להציג את המטא-נתונים באופן חזותי, או לקרוא את המטא-נתונים ממודל LiteRT לפורמט JSON באמצעות MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
ב-Android Studio יש גם תמיכה בהצגת מטא-נתונים באמצעות התכונה Android Studio ML Binding.
ניהול גרסאות של מטא-נתונים
סכימת המטא-נתונים מנוהלת בגרסאות גם לפי מספר הגרסה הסמנטית, שמתעד את השינויים בקובץ הסכימה, וגם לפי זיהוי הקובץ של Flatbuffers, שמציין את התאימות האמיתית של הגרסה.
מספר הגרסה הסמנטית
הגרסה של סכימת המטא-נתונים מצוינת על ידי מספר הגרסה הסמנטי, כמו MAJOR.MINOR.PATCH. הוא עוקב אחרי שינויים בסכימה בהתאם לכללים שמפורטים כאן.
היסטוריית השדות שנוספו אחרי גרסה 1.0.0.
זיהוי קובץ Flatbuffers
אם פועלים לפי הכללים, גרסה סמנטית מבטיחה תאימות, אבל היא לא מרמזת על חוסר תאימות אמיתי. כשמעלים את המספר MAJOR, זה לא בהכרח אומר שהתאימות לאחור נשברה. לכן, אנחנו משתמשים בזיהוי של קובץ Flatbuffers, file_identifier, כדי לציין את התאימות האמיתית של סכימת המטא-נתונים. מזהה הקובץ הוא באורך של 4 תווים בדיוק. הוא קבוע לסכימת מטא-נתונים מסוימת, והמשתמשים לא יכולים לשנות אותו. אם מסיבה כלשהי צריך לשבור את התאימות לאחור של סכימת המטא-נתונים, הערך של file_identifier יגדל, למשל מ-M001 ל-M002. צפוי שהערך של file_identifier ישתנה בתדירות נמוכה בהרבה מזו של metadata_version.
הגרסה המינימלית הנדרשת של כלי לניתוח מטא-נתונים
הגרסה המינימלית של מנתח המטא-נתונים היא הגרסה המינימלית של מנתח המטא-נתונים (הקוד שנוצר על ידי Flatbuffers) שיכול לקרוא את מטא-נתוני Flatbuffers במלואם. הגרסה היא למעשה מספר הגרסה הגדול ביותר מבין הגרסאות של כל השדות שאוכלסו, ומספר הגרסה התואמת הקטן ביותר שמצוין על ידי מזהה הקובץ. הגרסה המינימלית של מנתח המטא-נתונים מאוכלסת אוטומטית על ידי MetadataPopulator כשהמטא-נתונים מאוכלסים במודל TFLite. מידע נוסף על השימוש בגרסה המינימלית הנדרשת של מנתח המטא-נתונים זמין במאמר בנושא כלי לחילוץ מטא-נתונים.
קריאת המטא-נתונים מהמודלים
ספריית Metadata Extractor היא כלי נוח לקריאת המטא-נתונים והקבצים המשויכים ממודלים בפלטפורמות שונות (אפשר לעיין בגרסת Java ובגרסת C++). אפשר ליצור כלי משלכם לחילוץ מטא-נתונים בשפות אחרות באמצעות ספריית Flatbuffers.
קריאת המטא-נתונים ב-Java
כדי להשתמש בספריית Metadata Extractor באפליקציית Android, מומלץ להשתמש ב-LiteRT Metadata AAR שמתארח ב-MavenCentral.
היא מכילה את המחלקה MetadataExtractor, וגם את הקישורים של FlatBuffers Java לסכימת המטא-נתונים ולסכימת המודל.
אפשר לציין את זה בתלות של build.gradle באופן הבא:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
כדי להשתמש בתמונות מצב יומיות, צריך לוודא שהוספתם את Sonatype snapshot repository.
אפשר לאתחל אובייקט MetadataExtractor באמצעות ByteBuffer שמפנה למודל:
public MetadataExtractor(ByteBuffer buffer);
הערך של ByteBuffer חייב להישאר ללא שינוי למשך כל משך החיים של האובייקט MetadataExtractor. יכול להיות שההפעלה תיכשל אם מזהה קובץ ה-Flatbuffers של מטא-נתוני המודל לא תואם לזה של מנתח המטא-נתונים. מידע נוסף זמין במאמר בנושא ניהול גרסאות של מטא-נתונים.
אם מזהי הקבצים תואמים, כלי חילוץ המטא-נתונים יקרא בהצלחה את המטא-נתונים שנוצרו מכל הסכימות הקודמות והעתידיות, כי Flatbuffers תומך בתאימות קדימה ואחורה. עם זאת, אי אפשר לחלץ שדות מסכימות עתידיות באמצעות כלי חילוץ מטא-נתונים ישנים יותר. הגרסה המינימלית הנדרשת של מנתח התוכן של המטא-נתונים מציינת את הגרסה המינימלית של מנתח המטא-נתונים שיכול לקרוא את המטא-נתונים של Flatbuffers במלואם. אפשר להשתמש בשיטה הבאה כדי לוודא שהתנאי של גרסת המנתח המינימלית הנדרשת מתקיים:
public final boolean isMinimumParserVersionSatisfied();
מותר להעביר מודל ללא מטא-נתונים. עם זאת, הפעלת שיטות שקוראות מהמטא-נתונים תגרום לשגיאות בזמן הריצה. כדי לבדוק אם למודל יש מטא-נתונים, מפעילים את השיטה hasMetadata:
public boolean hasMetadata();
MetadataExtractor מספקת פונקציות נוחות לקבלת המטא-נתונים של טנסורי הקלט והפלט. לדוגמה,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
למרות שסכימת המודל LiteRT
תומכת בכמה תתי-גרפים, המפענח TFLite תומך כרגע רק בתת-גרף אחד. לכן, MetadataExtractor משמיט את אינדקס הגרף המשני כארגומנט קלט בשיטות שלו.
קריאת הקבצים המשויכים מהמודלים
מודל LiteRT עם מטא-נתונים וקבצים משויכים הוא למעשה קובץ ZIP שאפשר לפתוח באמצעות כלי ZIP נפוצים כדי לקבל את הקבצים המשויכים. לדוגמה, אפשר לפתוח את הקובץ mobilenet_v1_0.75_160_quantized ולחלץ את קובץ התוויות במודל באופן הבא:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
אפשר גם לקרוא קבצים משויכים דרך ספריית הכלי לחילוץ מטא-נתונים.
ב-Java, מעבירים את שם הקובץ לשיטה MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
באופן דומה, ב-C++, אפשר לעשות זאת באמצעות ה-method, ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;