
Edge-Geräte haben oft nur begrenzten Speicher oder begrenzte Rechenleistung. Es gibt verschiedene Optimierungen, die auf Modelle angewendet werden können, damit sie innerhalb dieser Einschränkungen ausgeführt werden können. Außerdem ermöglichen einige Optimierungen die Verwendung spezieller Hardware für eine beschleunigte Inferenz.
LiteRT und das TensorFlow Model Optimization Toolkit bieten Tools, mit denen sich die Komplexität der Optimierung der Inferenz minimieren lässt.
Es wird empfohlen, die Modelloptimierung während der Entwicklung Ihrer Anwendung zu berücksichtigen. In diesem Dokument werden einige Best Practices für die Optimierung von TensorFlow-Modellen für die Bereitstellung auf Edge-Hardware beschrieben.
Warum sollten Modelle optimiert werden?
Die Modelloptimierung kann auf verschiedene Weise bei der Anwendungsentwicklung helfen.
Größenreduzierung
Einige Formen der Optimierung können verwendet werden, um die Größe eines Modells zu verringern. Kleinere Modelle bieten folgende Vorteile:
- Geringere Speichergröße:Kleinere Modelle belegen weniger Speicherplatz auf den Geräten Ihrer Nutzer. Eine Android-App, die ein kleineres Modell verwendet, benötigt beispielsweise weniger Speicherplatz auf dem Mobilgerät eines Nutzers.
- Geringere Downloadgröße:Kleinere Modelle benötigen weniger Zeit und Bandbreite, um auf die Geräte der Nutzer heruntergeladen zu werden.
- Geringere Speichernutzung:Kleinere Modelle benötigen weniger RAM, wenn sie ausgeführt werden. Dadurch wird Speicher für andere Teile Ihrer Anwendung freigegeben, was zu einer besseren Leistung und Stabilität führen kann.
Die Quantisierung kann die Größe eines Modells in all diesen Fällen reduzieren, möglicherweise auf Kosten der Genauigkeit. Durch das Beschneiden und Clustern kann die Größe eines Modells für den Download reduziert werden, da es sich leichter komprimieren lässt.
Reduzierung der Latenz
Die Latenz ist die Zeit, die für die Ausführung einer einzelnen Inferenz mit einem bestimmten Modell benötigt wird. Durch bestimmte Optimierungsformen kann die für die Ausführung der Inferenz mit einem Modell erforderliche Rechenleistung reduziert werden, was zu einer geringeren Latenz führt. Die Latenz kann sich auch auf den Stromverbrauch auswirken.
Derzeit kann die Quantisierung verwendet werden, um die Latenz zu verringern, indem die Berechnungen vereinfacht werden, die während der Inferenz ausgeführt werden. Dies kann jedoch auf Kosten der Genauigkeit gehen.
Kompatibilität mit Beschleunigern
Einige Hardwarebeschleuniger wie die Edge TPU können die Inferenz mit korrekt optimierten Modellen extrem schnell ausführen.
Im Allgemeinen muss für diese Gerätetypen eine bestimmte Quantisierung der Modelle erfolgen. Weitere Informationen zu den Anforderungen der einzelnen Hardwarebeschleuniger finden Sie in der jeweiligen Dokumentation.
Vor- und Nachteile
Optimierungen können sich auf die Modellgenauigkeit auswirken. Dies muss bei der Entwicklung von Anwendungen berücksichtigt werden.
Die Änderungen der Genauigkeit hängen vom jeweiligen Modell ab, das optimiert wird, und lassen sich nur schwer vorhersagen. Im Allgemeinen verlieren Modelle, die für Größe oder Latenz optimiert sind, einen geringen Teil ihrer Genauigkeit. Je nach Anwendung kann sich dies auf die Nutzer auswirken. In seltenen Fällen kann die Genauigkeit bestimmter Modelle durch den Optimierungsprozess verbessert werden.
Optimierungsarten
LiteRT unterstützt derzeit die Optimierung durch Quantisierung, Beschneidung und Clustering.
Diese sind Teil des TensorFlow Model Optimization Toolkit, das Ressourcen für Modelloptimierungstechniken bietet, die mit TensorFlow Lite kompatibel sind.
Quantisierung
Bei der Quantisierung wird die Genauigkeit der Zahlen reduziert, die zur Darstellung der Parameter eines Modells verwendet werden. Standardmäßig sind das 32-Bit-Gleitkommazahlen. Das führt zu einer kleineren Modellgröße und schnelleren Berechnungen.
In LiteRT sind die folgenden Arten der Quantisierung verfügbar:
| Verfahren | Datenanforderungen | Größenreduzierung | Genauigkeit | Unterstützte Hardware |
|---|---|---|---|---|
| float16-Quantisierung nach dem Training | Keine Daten | Bis zu 50% | Geringfügiger Genauigkeitsverlust | CPU, GPU |
| Quantisierung des dynamischen Bereichs nach dem Training | Keine Daten | Bis zu 75% | Geringster Genauigkeitsverlust | CPU, GPU (Android) |
| Ganzzahlquantisierung nach dem Training | Unbeschriftete repräsentative Stichprobe | Bis zu 75% | Geringer Genauigkeitsverlust | CPU, GPU (Android), EdgeTPU |
| Quantisierungsbewusstes Training | Trainingsdaten mit Labels | Bis zu 75% | Geringster Genauigkeitsverlust | CPU, GPU (Android), EdgeTPU |
Anhand des folgenden Entscheidungsbaums können Sie die Quantisierungsschemas auswählen, die Sie für Ihr Modell verwenden möchten, basierend auf der erwarteten Modellgröße und ‑genauigkeit.
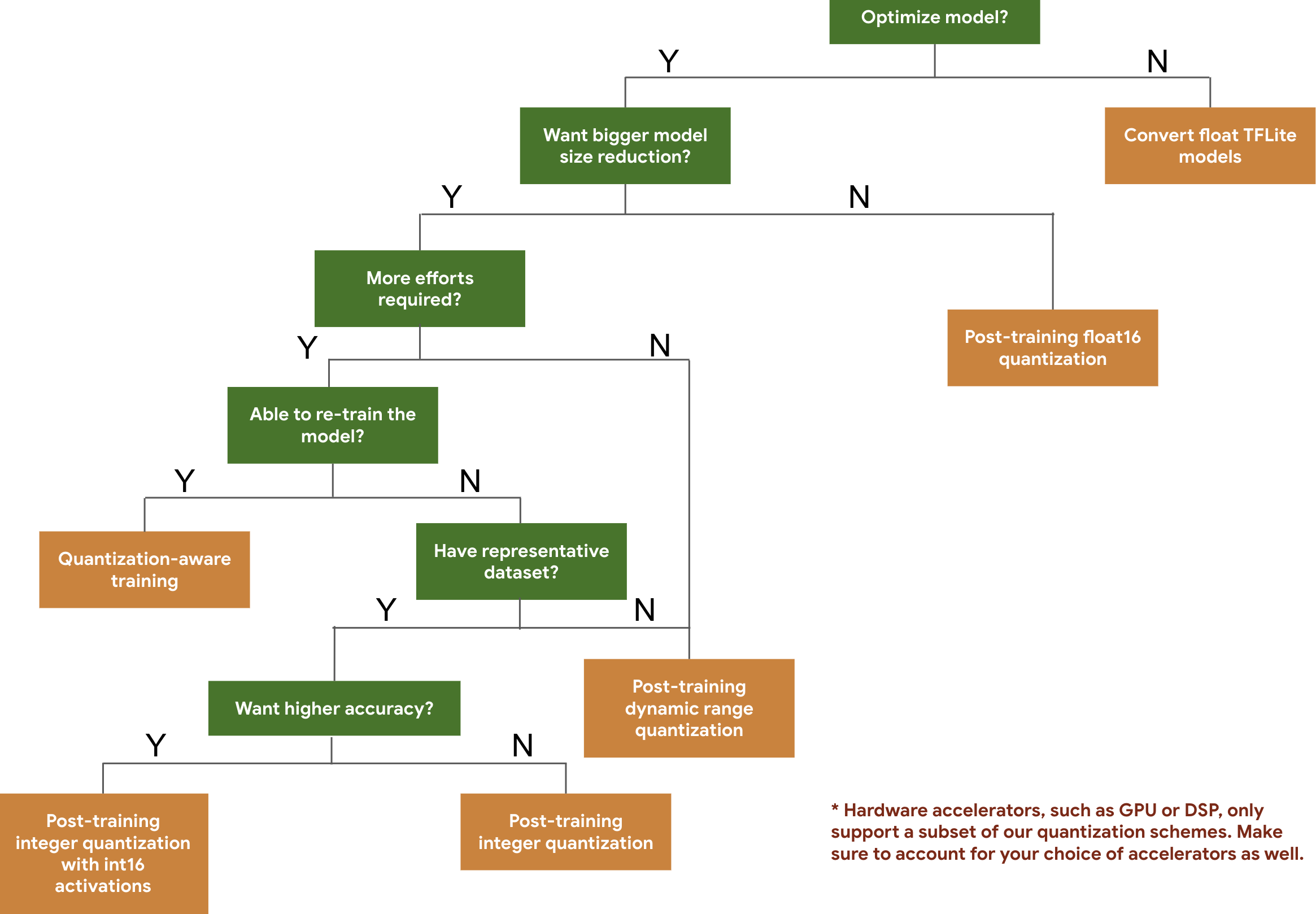
Unten sehen Sie die Latenz- und Genauigkeitsergebnisse für die Quantisierung nach dem Training und das quantisierungsbewusste Training für einige Modelle. Alle Latenzwerte werden auf Pixel 2-Geräten mit einer einzelnen Big-Core-CPU gemessen. Mit der Weiterentwicklung des Toolkits werden sich auch die Zahlen hier verbessern:
| Modell | Top-1-Genauigkeit (Original) | Top-1-Genauigkeit (quantisiert nach dem Training) | Top-1-Genauigkeit (quantisierungsbewusstes Training) | Latenz (Original) (ms) | Latenz (nach dem Training quantisiert) (ms) | Latenz (quantisierungsbewusstes Training) (ms) | Größe (Original) (MB) | Größe (optimiert) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4,3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3,6 |
| Inception_v3 | 0.78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23.9 |
| Resnet_v2_101 | 0,770 | 0,768 | – | 3973 | 2868 | – | 178.3 | 44,9 |
Vollständige Ganzzahlquantisierung mit int16-Aktivierungen und int8-Gewichtungen
Die Quantisierung mit int16-Aktivierungen ist ein vollständiges Ganzzahlquantisierungsschema mit Aktivierungen in int16 und Gewichten in int8. In diesem Modus kann die Genauigkeit des quantisierten Modells im Vergleich zur vollständigen Ganzzahlquantisierung mit sowohl Aktivierungen als auch Gewichten in int8 verbessert werden, wobei die Modellgröße ähnlich bleibt. Es wird empfohlen, wenn Aktivierungen empfindlich auf die Quantisierung reagieren.
HINWEIS:Derzeit sind in TFLite für dieses Quantisierungsschema nur nicht optimierte Referenzkernel-Implementierungen verfügbar. Die Leistung ist daher standardmäßig im Vergleich zu INT8-Kernels langsam. Die Vorteile dieses Modus können derzeit nur über spezielle Hardware oder benutzerdefinierte Software genutzt werden.
Unten sehen Sie die Genauigkeitsergebnisse für einige Modelle, die von diesem Modus profitieren.
| Modell | Messwerttyp für die Genauigkeit | Genauigkeit (float32-Aktivierungen) | Genauigkeit (int8-Aktivierungen) | Genauigkeit (int16-Aktivierungen) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7 % | 7,7 % | 7,2 % |
| DeepSpeech 0.5.1 (unrolled) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0.5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | Top-1-Genauigkeit | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | Top-1-Genauigkeit | 0,718 | 0,7126 | 0,7137 |
| MobileBert | F1(genaue Übereinstimmung) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Beschneiden
Beim Pruning werden Parameter in einem Modell entfernt, die nur geringe Auswirkungen auf die Vorhersagen haben. Die Größe von gekürzten Modellen auf der Festplatte und die Laufzeitlatenz sind gleich, sie lassen sich aber effektiver komprimieren. Das Beschneiden ist daher eine nützliche Methode, um die Downloadgröße von Modellen zu reduzieren.
Künftig wird LiteRT die Latenz für komprimierte Modelle verringern.
Clustering
Beim Clustering werden die Gewichte jeder Ebene in einem Modell in eine vordefinierte Anzahl von Clustern gruppiert. Anschließend werden die Zentroidwerte für die Gewichte, die zu den einzelnen Clustern gehören, gemeinsam genutzt. Dadurch wird die Anzahl der eindeutigen Gewichtungswerte in einem Modell reduziert und somit auch die Komplexität.
Daher können geclusterten Modelle effektiver komprimiert werden, was ähnliche Vorteile wie das Beschneiden bietet.
Entwicklungsworkflow
Prüfen Sie zuerst, ob die Modelle in Gehostete Modelle für Ihre Anwendung geeignet sind. Andernfalls empfehlen wir Nutzern, mit dem Tool zur Quantisierung nach dem Training zu beginnen, da es allgemein anwendbar ist und keine Trainingsdaten erfordert.
Wenn die Genauigkeits- und Latenzziele nicht erreicht werden oder die Unterstützung von Hardwarebeschleunigern wichtig ist, ist quantisierungsbewusstes Training die bessere Option. Weitere Optimierungstechniken finden Sie im TensorFlow Model Optimization Toolkit.
Wenn Sie die Modellgröße weiter reduzieren möchten, können Sie vor der Quantisierung Ihrer Modelle Pruning und/oder Clustering ausprobieren.