
概要
このページでは、TensorFlow の複合演算を TensorFlow Lite の融合演算に変換するために必要な設計と手順について説明します。このインフラストラクチャは汎用であり、TensorFlow の複合演算を TensorFlow Lite の対応する融合演算に変換できます。
このインフラストラクチャの使用例は、こちらで詳しく説明されているように、TensorFlow RNN オペレーションの融合と TensorFlow Lite の融合です。
融合オペレーションとは

TensorFlow 演算は、tf.add などのプリミティブ演算にすることも、tf.einsum などの他のプリミティブ演算から作成することもできます。プリミティブ演算は TensorFlow グラフでは単一のノードとして表示されますが、複合演算は TensorFlow グラフではノードの集合です。複合オペレーションの実行は、その構成要素となるプリミティブ オペレーションの実行とそれぞれ同等です。
融合演算は、対応する複合演算内の各プリミティブ演算によって実行されるすべての計算を含む単一の演算を表します。
融合オペレーションのメリット
融合演算は、全体的な計算を最適化してメモリ フットプリントを削減することで、基盤となるカーネル実装のパフォーマンスを最大化するために存在します。これは、特に低レイテンシの推論ワークロードやリソースに制約のあるモバイル プラットフォームにとって非常に重要です。
融合演算は、量子化などの複雑な変換を定義するための上位レベルのインターフェースも提供します。量子化などの複雑な変換は、他の方法では実行不可能であるか、より細かいレベルで行うことは非常に困難です。
TensorFlow Lite には、上記の理由から融合演算のインスタンスが多数あります。通常、これらの融合された演算は、ソース TensorFlow プログラムの複合演算に対応します。TensorFlow Lite で単一の融合演算として実装される TensorFlow の複合演算の例としては、単方向および双方向シーケンス LSTM、畳み込み(conv2d、バイアス加算、relu)、完全接続(matmul、バイアス add、relu)などのさまざまな RNN オペレーションがあります。TensorFlow Lite では、LSTM 量子化は現在、融合 LSTM 演算にのみ実装されています。
融合された運用の課題
TensorFlow Lite では、複合オペレーションを TensorFlow から融合オペレーションに変換することは難しい問題です。理由は次のとおりです。
複合演算は、明確に定義された境界のない、一連のプリミティブ演算として TensorFlow グラフに表現されます。このような複合演算に対応するサブグラフを特定することは(パターン マッチングなどによって)非常に困難な場合があります。
融合された TensorFlow Lite オペレーションをターゲットとする TensorFlow 実装が複数ある場合もあります。たとえば、TensorFlow には多くの LSTM 実装(Keras、Babelfish、lingvo など)があり、それぞれが異なるプリミティブ演算で構成されていますが、それらはすべて TensorFlow Lite で同じ融合 LSTM 演算に変換できます。
そのため、融合演算の変換は非常に困難であることが証明されています。
複合オペレーションから TFLite カスタム オペレーションへの変換(推奨)
複合オペレーションを tf.function でラップする
多くの場合、モデルの一部は TFLite の 1 つのオペレーションにマッピングできます。これにより、特定のオペレーション用に最適化された実装を記述する際のパフォーマンスが向上します。TFLite で融合演算を作成できるようにするには、融合演算を表すグラフ内の部分を特定し、それを tf.function でラップします。その際、tf.function の属性値 tfl_fusable_op と値 true を持つ「experimental_implementations」属性を指定します。カスタム オペレーションが属性を受け取る場合は、同じ「experimental_Implements」の一部として渡します。
例,
def get_implements_signature():
implements_signature = [
# 'name' will be used as a name for the operation.
'name: "my_custom_fused_op"',
# attr "tfl_fusable_op" is required to be set with true value.
'attr {key: "tfl_fusable_op" value { b: true } }',
# Example attribute "example_option" that the op accepts.
'attr {key: "example_option" value { i: %d } }' % 10
]
return ' '.join(implements_signature)
@tf.function(experimental_implements=get_implements_signature())
def my_custom_fused_op(input_1, input_2):
# An empty function that represents pre/post processing example that
# is not represented as part of the Tensorflow graph.
output_1 = tf.constant(0.0, dtype=tf.float32, name='first_output')
output_2 = tf.constant(0.0, dtype=tf.float32, name='second_output')
return output_1, output_2
class TestModel(tf.Module):
def __init__(self):
super(TestModel, self).__init__()
self.conv_1 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
self.conv_2 = tf.keras.layers.Conv2D(filters=1, kernel_size=(3, 3))
@tf.function(input_signature=[
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
tf.TensorSpec(shape=[1, 28, 28, 3], dtype=tf.float32),
])
def simple_eval(self, input_a, input_b):
return my_custom_fused_op(self.conv_1(input_a), self.conv_2(input_b))
なお、コンバータで allow_custom_ops を設定する必要はありません。tfl_fusable_op 属性によってすでに設定されているためです。
カスタム演算を実装して TFLite インタープリタに登録する
融合されたオペレーションを TFLite カスタム オペレーションとして実装します。詳しくは、instructionsをご覧ください。
演算を登録する名前は、 implements シグネチャの name 属性で指定した名前と同様である必要があります。
この例の op は、
TfLiteRegistration reg = {};
// This name must match the name specified in the implements signature.
static constexpr char kOpName[] = "my_custom_fused_op";
reg.custom_name = kOpName;
reg.prepare = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.invoke = [](TfLiteContext* context, TfLiteNode* node) -> TfLiteStatus {
// Add your code.
return kTfLiteOk;
};
reg.builtin_code = kTfLiteCustom;
resolver->AddCustom(kOpName, ®);
複合オペレーションから融合オペレーションへの変換(Advanced)
TensorFlow 複合オペレーションを TensorFlow Lite 融合オペレーションに変換するための全体的なアーキテクチャは次のとおりです。
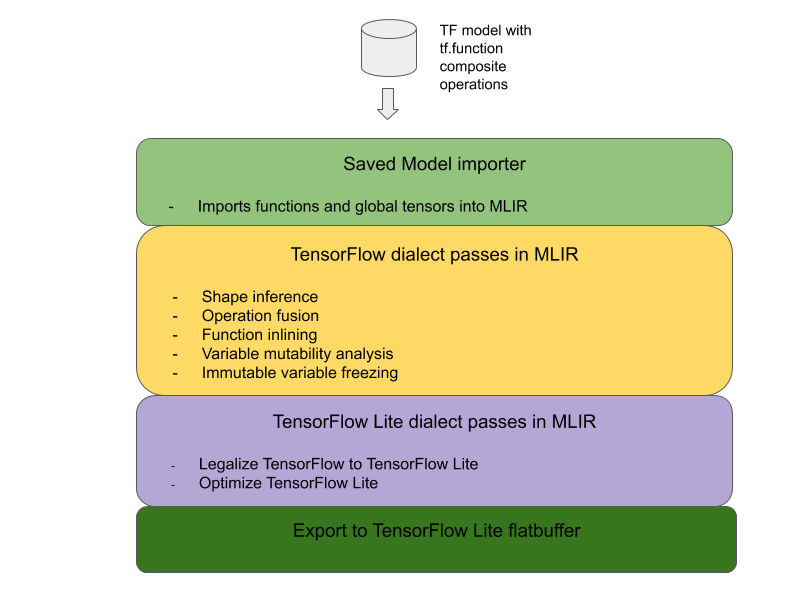
複合オペレーションを tf.function でラップする
TensorFlow モデルのソースコードで、experimental_implements 関数アノテーションを使用して、複合オペレーションを特定して tf.function に抽象化します。ルックアップの埋め込みの例をご覧ください。この関数はインターフェースを定義します。その引数を使用して変換ロジックを実装する必要があります。
コンバージョン コードを記述する
変換コードは、関数のインターフェースごとに implements アノテーションを付けて記述します。ルックアップの埋め込みの融合の例をご覧ください。概念的には、この変換コードにより、このインターフェースの複合実装が融合された実装に置き換えられます。
prepare-複合関数パスで、コンバージョン コードにプラグインを追加します。
より高度な使用例では、複合演算のオペランドを複雑な変換を実装して、融合演算のオペランドを導出できます。例として、Keras LSTM 変換コードをご覧ください。
TensorFlow Lite に変換する
TensorFlow Lite に変換するには、TFLiteConverter.from_saved_model API を使用します。
仕組み
ここでは、TensorFlow Lite の融合演算への変換における全体的な設計の概要を説明します。
TensorFlow でのオペレーションの作成
tf.function を experimental_implements 関数属性とともに使用すると、ユーザーは TensorFlow プリミティブ オペレーションを使用して新しいオペレーションを明示的に作成し、結果として得られる複合オペレーションが実装するインターフェースを指定できます。これは次の機能を備えており、非常に便利です。
- 基盤となる TensorFlow グラフの複合オペレーションの明確に定義された境界。
- この演算で実装するインターフェースを明示的に指定します。tf.function の引数は、このインターフェースの引数に対応しています。
例として、エンベディング ルックアップを実装するために定義された複合演算について考えてみましょう。これは TensorFlow Lite の融合演算にマッピングされます。
@tf.function(
experimental_implements="embedding_lookup")
def EmbFprop(embs, ids_vec):
"""Embedding forward prop.
Effectively, it computes:
num = size of ids_vec
rets = zeros([num, embedding dim])
for i in range(num):
rets[i, :] = embs[ids_vec[i], :]
return rets
Args:
embs: The embedding matrix.
ids_vec: A vector of int32 embedding ids.
Returns:
The result of embedding lookups. A matrix of shape
[num ids in ids_vec, embedding dims].
"""
num = tf.shape(ids_vec)[0]
rets = inplace_ops.empty([num] + emb_shape_suf, py_utils.FPropDtype(p))
def EmbFpropLoop(i, embs, ids_vec, rets):
# row_id = ids_vec[i]
row_id = tf.gather(ids_vec, i)
# row = embs[row_id]
row = tf.reshape(tf.gather(embs, row_id), [1] + emb_shape_suf)
# rets[i] = row
rets = inplace_ops.alias_inplace_update(rets, [i], row)
return embs, ids_vec, rets
_, _, rets = functional_ops.For(
start=0,
limit=num,
delta=1,
inputs=[embs, ids_vec, rets],
body=EmbFpropLoop,
rewrite_with_while=compiled)
if len(weight_shape) > 2:
rets = tf.reshape(rets, [num, symbolic.ToStatic(p.embedding_dim)])
return rets
上に示したように、モデルで tf.function を介した複合演算を使用することで、このような演算を識別して変換し、融合された TensorFlow Lite 演算にするための一般的なインフラストラクチャを構築できるようになります。
TensorFlow Lite コンバータの拡張
今年初めにリリースされた TensorFlow Lite コンバータでは、すべての変数が対応する定数値に置き換えられたグラフとして TensorFlow モデルをインポートすることのみがサポートされています。これは演算融合では機能しません。このようなグラフではすべての関数がインライン化され、変数を定数に変換できるためです。
変換プロセス中に experimental_implements 機能とともに tf.function を活用するには、変換プロセスの後半まで関数を保持する必要があります。
そのため、コンポジット オペレーションの融合のユースケースをサポートするため、コンバータで TensorFlow モデルをインポートおよび変換する新しいワークフローを実装しました。具体的には、次のような新機能が追加されます。
- TensorFlow の保存済みモデルを MLIR にインポートする
- 複合オペレーションを融合
- 変数可変性分析
- すべての読み取り専用変数を
これにより、関数のインライン化と変数の凍結の前に、複合オペレーションを表す関数を使用してオペレーションの融合を実行できます。
オペレーション フュージョンの実装
オペレーション フュージョン パスについて詳しく見ていきましょう。このパスは次の処理を行います。
- MLIR モジュール内のすべての関数をループ処理します。
- 関数に tf._Implements 属性がある場合は、属性値に基づいて、適切なオペレーション フュージョン ユーティリティを呼び出します。
- 演算フュージョン ユーティリティは、関数のオペランドと属性(変換のインターフェースとして機能します)を操作し、関数の本文を、融合された演算を含む同等の関数本体に置き換えます。
- 多くの場合、置換された本文には、融合されたオペレーション以外のオペレーションが含まれます。これらは、融合演算のオペランドを取得するための、関数のオペランドに対するいくつかの静的変換に対応しています。これらの計算はすべて一定に折りたたまれる可能性があるため、融合された演算のみが存在するエクスポートされたフラットバッファには存在しません。
メイン ワークフローを示すパスのコード スニペットは次のとおりです。
void PrepareCompositeFunctionsPass::ConvertTFImplements(FuncOp func,
StringAttr attr) {
if (attr.getValue() == "embedding_lookup") {
func.eraseBody();
func.addEntryBlock();
// Convert the composite embedding_lookup function body to a
// TFLite fused embedding_lookup op.
ConvertEmbeddedLookupFunc convert_embedded_lookup(func);
if (failed(convert_embedded_lookup.VerifySignature())) {
return signalPassFailure();
}
convert_embedded_lookup.RewriteFunc();
} else if (attr.getValue() == mlir::TFL::kKerasLstm) {
func.eraseBody();
func.addEntryBlock();
OpBuilder builder(func.getBody());
if (failed(ConvertKerasLSTMLayer(func, &builder))) {
return signalPassFailure();
}
} else if (.....) /* Other fusions can plug in here */
}
次のコード スニペットは、この複合演算を、この関数を変換インターフェースとして使用する TensorFlow Lite の融合演算にマッピングする方法を示しています。
void RewriteFunc() {
Value lookup = func_.getArgument(1);
Value value = func_.getArgument(0);
auto output_type = func_.getType().getResult(0);
OpBuilder builder(func_.getBody());
auto op = builder.create<mlir::TFL::EmbeddingLookupOp>(
func_.getLoc(), output_type, lookup, value);
builder.create<mlir::ReturnOp>(func_.getLoc(), op.getResult());
}