
Operatory systemów uczących się używane w modelu mogą mieć wpływ na proces konwersji modelu TensorFlow do formatu LiteRT. Konwerter LiteRT obsługuje ograniczoną liczbę operacji TensorFlow używanych w popularnych modelach wnioskowania, co oznacza, że nie każdy model można przekonwertować bezpośrednio. Narzędzie do konwersji umożliwia uwzględnianie dodatkowych operatorów, ale konwersja modelu w ten sposób wymaga też zmodyfikowania środowiska wykonawczego LiteRT, którego używasz do wykonywania modelu, co może ograniczyć możliwość korzystania ze standardowych opcji wdrażania środowiska wykonawczego, takich jak Usługi Google Play.
Konwerter LiteRT analizuje strukturę modelu i stosuje optymalizacje, aby zapewnić jego zgodność z bezpośrednio obsługiwanymi operatorami. Na przykład w zależności od operatorów ML w modelu konwerter może pomijać lub łączyć te operatory, aby przypisać je do odpowiedników w LiteRT.
Nawet w przypadku obsługiwanych operacji ze względu na wydajność czasami oczekiwane są określone wzorce użycia. Aby dowiedzieć się, jak utworzyć model TensorFlow, którego można używać z LiteRT, należy dokładnie rozważyć, jak operacje są konwertowane i optymalizowane, a także jakie ograniczenia są nakładane przez ten proces.
Obsługiwane operatory
Wbudowane operatory LiteRT to podzbiór operatorów, które są częścią podstawowej biblioteki TensorFlow. Model TensorFlow może też zawierać niestandardowe operatory w postaci operatorów złożonych lub nowych operatorów zdefiniowanych przez Ciebie. Diagram poniżej przedstawia relacje między tymi operatorami.
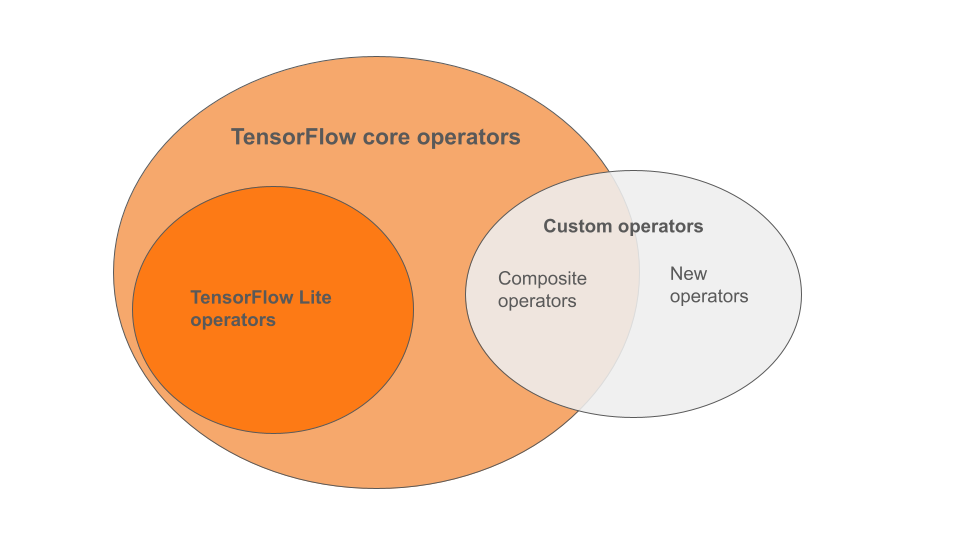
Z tego zakresu operatorów modeli ML proces konwersji obsługuje 3 typy modeli:
- Modele z wbudowanym operatorem LiteRT. (zalecane)
- Modele z wbudowanymi operatorami i wybranymi podstawowymi operatorami TensorFlow.
- Modele z wbudowanymi operatorami, operatorami podstawowymi TensorFlow lub operatorami niestandardowymi.
Jeśli model zawiera tylko operacje obsługiwane natywnie przez LiteRT, nie musisz używać żadnych dodatkowych flag, aby go przekonwertować. Jest to zalecana ścieżka, ponieważ ten typ modelu można łatwo przekonwertować, a także prościej go optymalizować i uruchamiać za pomocą domyślnego środowiska wykonawczego LiteRT. Masz też więcej opcji wdrażania modelu, np. Usługi Google Play. Możesz zacząć od przewodnika po konwerterze LiteRT. Listę wbudowanych operatorów znajdziesz na stronie LiteRT Ops.
Jeśli chcesz uwzględnić wybrane operacje TensorFlow z biblioteki podstawowej, musisz to określić podczas konwersji i upewnić się, że środowisko wykonawcze zawiera te operacje. Szczegółowe instrukcje znajdziesz w temacie Wybieranie operatorów TensorFlow.
Jeśli to możliwe, unikaj ostatniej opcji, czyli uwzględniania w przekonwertowanym modelu operatorów niestandardowych. Operatory niestandardowe to operatory utworzone przez połączenie wielu podstawowych operatorów TensorFlow Core lub zdefiniowanie zupełnie nowego operatora. Po przekonwertowaniu operatorów niestandardowych mogą one zwiększyć rozmiar całego modelu, powodując zależności poza wbudowaną biblioteką LiteRT. Operacje niestandardowe, które nie zostały utworzone specjalnie na potrzeby wdrożenia na urządzeniach mobilnych lub innych, mogą działać gorzej na urządzeniach o ograniczonych zasobach niż w środowisku serwerowym. Podobnie jak w przypadku wybranych operatorów podstawowych TensorFlow, operatory niestandardowe wymagają zmodyfikowania środowiska wykonawczego modelu, co uniemożliwia korzystanie ze standardowych usług wykonawczych, takich jak Usługi Google Play.
Typy obsługiwane
Większość operacji LiteRT jest przeznaczona do wnioskowania zmiennoprzecinkowego (float32) i skwantowanego (uint8, int8), ale wiele operacji nie jest jeszcze przeznaczonych do innych typów, takich jak tf.float16 i ciągi znaków.
Oprócz używania różnych wersji operacji inną różnicą między modelami zmiennoprzecinkowymi a skwantyzowanymi jest sposób ich konwersji. Skwantowana konwersja wymaga informacji o zakresie dynamicznym tensorów. Wymaga to „fałszywej kwantyzacji” podczas trenowania modelu, uzyskiwania informacji o zakresie za pomocą zbioru danych kalibracyjnych lub szacowania zakresu „na bieżąco”. Więcej informacji znajdziesz w sekcji kwantyzacja.
Proste konwersje, stałe składanie i łączenie
LiteRT może przetwarzać wiele operacji TensorFlow, nawet jeśli nie mają one bezpośredniego odpowiednika. Dotyczy to operacji, które można po prostu usunąć z wykresu (tf.identity), zastąpić tensorami (tf.placeholder) lub połączyć w bardziej złożone operacje (tf.nn.bias_add). Nawet niektóre obsługiwane operacje mogą czasami zostać usunięte w ramach jednego z tych procesów.
Oto niepełna lista operacji TensorFlow, które są zwykle usuwane z wykresu:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operacje eksperymentalne
Te operacje LiteRT są dostępne, ale nie są gotowe do użycia w modelach niestandardowych:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF