
학습 후 양자화는 모델 크기를 줄이고 CPU 및 하드웨어 가속기 지연 시간을 개선할 수 있으며 모델 정확도가 거의 저하되지 않는 변환 기술입니다. LiteRT 변환기를 사용하여 이미 학습된 부동 소수점 TensorFlow 모델을 LiteRT 형식으로 변환할 때 양자화할 수 있습니다.
최적화 방법
학습 후 양자화 옵션은 여러 가지가 있습니다. 다음은 선택사항과 그에 따른 이점을 요약한 표입니다.
| 기법 | 이점 | 하드웨어 |
|---|---|---|
| 동적 범위 양자화 | 4배 더 작고 2~3배 더 빠름 | CPU |
| 전체 정수 양자화 | 4배 더 작고 3배 이상 빨라짐 | CPU, Edge TPU, 마이크로컨트롤러 |
| Float16 양자화 | 크기 2배 감소, GPU 가속 | CPU, GPU |
다음 결정 트리는 사용 사례에 가장 적합한 학습 후 양자화 방법을 결정하는 데 도움이 됩니다.
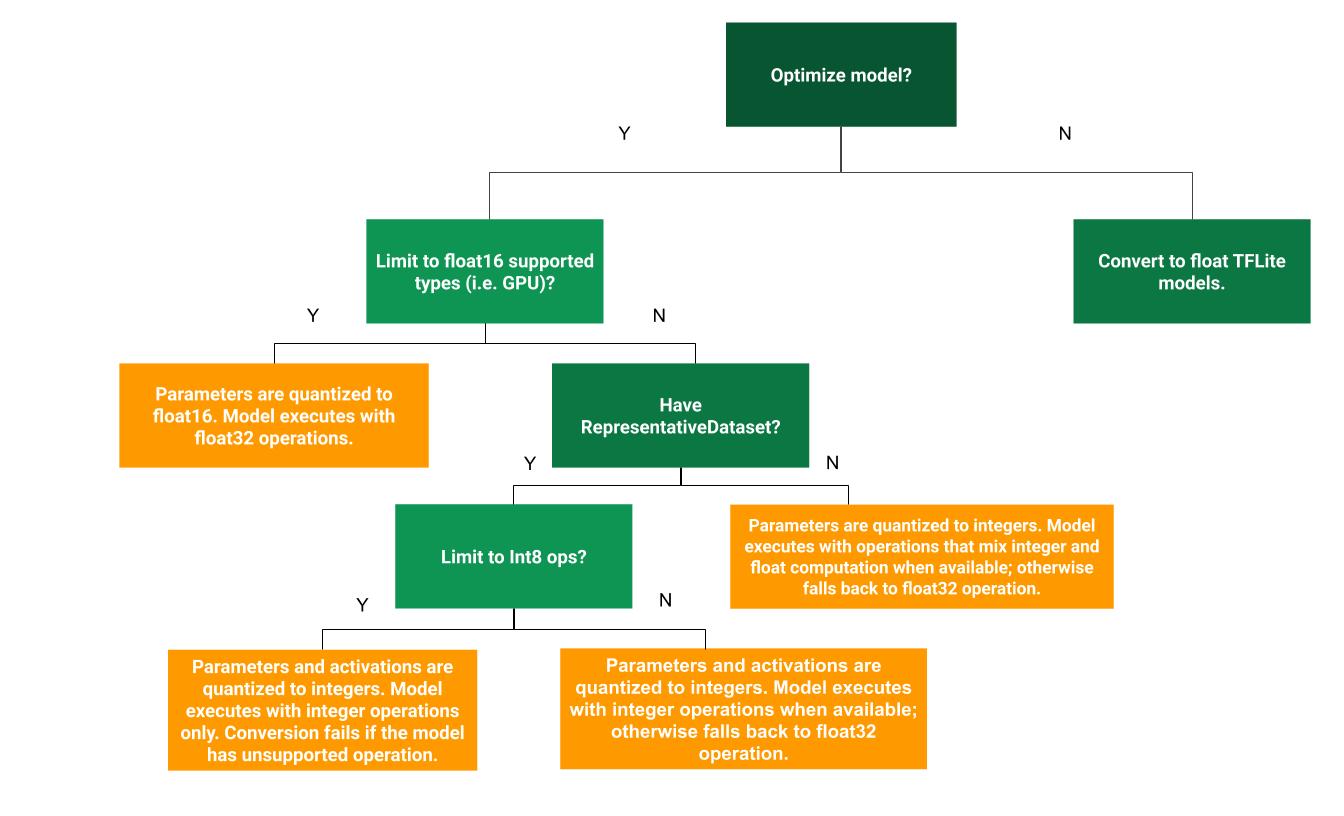
양자화 없음
양자화 없이 TFLite 모델로 변환하는 것이 권장되는 시작점입니다. 그러면 부동 소수점 TFLite 모델이 생성됩니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
원래 TF 모델의 연산자가 TFLite와 호환되는지 확인하는 초기 단계로 이 작업을 수행하는 것이 좋습니다. 또한 이 작업을 통해 후속 학습 후 양자화 방법으로 인해 발생하는 양자화 오류를 디버그하는 기준선으로 사용할 수 있습니다. 예를 들어 양자화된 TFLite 모델에서 예상치 못한 결과가 생성되지만 부동 소수점 TFLite 모델은 정확한 경우, TFLite 연산자의 양자화된 버전에서 도입된 오류로 문제를 좁힐 수 있습니다.
동적 범위 양자화
동적 범위 양자화는 보정을 위한 대표 데이터 세트를 제공하지 않아도 메모리 사용량을 줄이고 계산 속도를 높입니다. 이 유형의 양자화는 변환 시 부동 소수점에서 정수로 가중치만 정적으로 양자화하여 8비트의 정밀도를 제공합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
추론 중 지연 시간을 더욱 줄이기 위해 '동적 범위' 연산자는 범위를 기반으로 활성화를 8비트로 동적으로 양자화하고 8비트 가중치와 활성화로 계산을 실행합니다. 이 최적화는 완전히 고정 소수점 추론에 가까운 지연 시간을 제공합니다. 하지만 출력은 여전히 부동 소수점을 사용하여 저장되므로 동적 범위 작업의 속도 증가는 전체 고정 소수점 계산보다 적습니다.
전체 정수 양자화
모든 모델 수학이 정수로 양자화되도록 하면 지연 시간을 더욱 개선하고, 최대 메모리 사용량을 줄이며, 정수 전용 하드웨어 기기 또는 가속기와의 호환성을 확보할 수 있습니다.
전체 정수 양자화의 경우 범위를 보정하거나 추정해야 합니다. 즉, 모델에 있는 모든 부동 소수점 텐서의 (최소, 최대)입니다. 가중치 및 편향과 같은 상수 텐서와 달리 모델 입력, 활성화 (중간 레이어의 출력), 모델 출력과 같은 변수 텐서는 추론 주기를 몇 번 실행하지 않는 한 보정할 수 없습니다. 따라서 변환기에는 이를 보정하기 위한 대표 데이터 세트가 필요합니다. 이 데이터 세트는 학습 또는 검증 데이터의 작은 하위 집합 (약 100~500개 샘플)일 수 있습니다. 아래의 representative_dataset() 함수를 참고하세요.
TensorFlow 2.7 버전부터는 다음 예와 같이 서명을 통해 대표 데이터 세트를 지정할 수 있습니다.
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
지정된 TensorFlow 모델에 서명이 두 개 이상 있는 경우 서명 키를 지정하여 여러 데이터 세트를 지정할 수 있습니다.
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
입력 텐서 목록을 제공하여 대표 데이터 세트를 생성할 수 있습니다.
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 버전부터는 입력 텐서 순서가 쉽게 뒤집힐 수 있으므로 입력 텐서 목록 기반 접근 방식보다 서명 기반 접근 방식을 사용하는 것이 좋습니다.
테스트 목적으로 다음과 같이 더미 데이터 세트를 사용할 수 있습니다.
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
부동 소수점 대체가 있는 정수 (기본 부동 소수점 입력/출력 사용)
모델을 완전히 정수 양자화하되 정수 구현이 없는 경우 변환이 원활하게 이루어지도록 부동 소수점 연산자를 사용하려면 다음 단계를 따르세요.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
정수만
정수 전용 모델을 만드는 것은 마이크로컨트롤러용 LiteRT 및 Coral Edge TPU의 일반적인 사용 사례입니다.
또한 정수 전용 기기 (예: 8비트 마이크로컨트롤러) 및 가속기 (예: Coral Edge TPU)와의 호환성을 보장하기 위해 다음 단계를 사용하여 입력 및 출력을 포함한 모든 작업에 대해 전체 정수 양자화를 적용할 수 있습니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 양자화
가중치를 16비트 부동 소수점 숫자의 IEEE 표준인 float16으로 양자화하여 부동 소수점 모델의 크기를 줄일 수 있습니다. 가중치의 float16 양자화를 사용 설정하려면 다음 단계를 따르세요.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 양자화의 장점은 다음과 같습니다.
- 모든 가중치가 원래 크기의 절반이 되므로 모델 크기가 최대 절반으로 줄어듭니다.
- 정확도 손실이 최소화됩니다.
- float16 데이터에서 직접 작동할 수 있는 일부 대리자 (예: GPU 대리자)를 지원하므로 float32 계산보다 실행이 더 빠릅니다.
float16 양자화의 단점은 다음과 같습니다.
- 고정 소수점 수학으로 양자화하는 것만큼 지연 시간을 줄이지는 않습니다.
- 기본적으로 float16 양자화 모델은 CPU에서 실행될 때 가중치 값을 float32로 '역양자화'합니다. GPU 대리자는 float16 데이터에서 작동할 수 있으므로 이 역양자화를 실행하지 않습니다.
정수만 해당: 8비트 가중치가 있는 16비트 활성화 (실험)
실험적 양자화 방식입니다. '정수 전용' 스킴과 유사하지만 활성화는 범위를 기반으로 16비트로 양자화되고 가중치는 8비트 정수로 양자화되며 편향은 64비트 정수로 양자화됩니다. 이를 16x8 양자화라고 합니다.
이 양자화의 주요 장점은 정확도를 크게 개선할 수 있지만 모델 크기는 약간만 늘릴 수 있다는 것입니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
모델의 일부 연산자에 16x8 양자화가 지원되지 않는 경우 모델은 여전히 양자화할 수 있지만 지원되지 않는 연산자는 부동 소수점으로 유지됩니다. 이를 허용하려면 다음 옵션을 target_spec에 추가해야 합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
이 양자화 체계로 정확도가 향상되는 사용 사례의 예는 다음과 같습니다.
- 초해상도,
- 주변 소음 제거 및 빔포밍과 같은 오디오 신호 처리
- 이미지 노이즈 제거,
- 단일 이미지에서 HDR 재구성
이 양자화의 단점은 다음과 같습니다.
- 현재 추론은 최적화된 커널 구현이 부족하여 8비트 전체 정수보다 눈에 띄게 느립니다.
- 현재 기존 하드웨어 가속 TFLite 위임자와 호환되지 않습니다.
이 양자화 모드에 관한 튜토리얼은 여기에서 확인할 수 있습니다.
모델 정확성
가중치는 학습 후에 양자화되므로 특히 소규모 네트워크의 경우 정확도가 손실될 수 있습니다. 완전히 양자화된 사전 학습 모델은 Kaggle 모델에서 특정 네트워크에 제공됩니다. 정확도 저하가 허용 범위 내에 있는지 확인하려면 양자화된 모델의 정확도를 확인하는 것이 중요합니다. LiteRT 모델 정확도를 평가하는 도구가 있습니다.
또는 정확도 감소가 너무 큰 경우 양자화 인식 학습을 사용하는 것이 좋습니다. 하지만 이렇게 하려면 모델 학습 중에 가짜 양자화 노드를 추가해야 하는 반면, 이 페이지의 학습 후 양자화 기법은 기존의 선행 학습된 모델을 사용합니다.
양자화된 텐서의 표현
8비트 양자화는 다음 공식을 사용하여 부동 소수점 값을 근사합니다.
\[real\_value = (int8\_value - zero\_point) \times scale\]
표현에는 두 가지 주요 부분이 있습니다.
축별 (채널별) 또는 텐서별 가중치는 0과 같은 제로 포인트가 있는 [-127, 127] 범위의 int8 2의 보수 값으로 표현됩니다.
범위 [-128, 127]의 0점을 사용하여 범위 [-128, 127]의 int8 2의 보수 값으로 표현되는 텐서별 활성화/입력입니다.
양자화 방식에 관한 자세한 내용은 양자화 사양을 참고하세요. TensorFlow Lite의 위임 인터페이스에 연결하려는 하드웨어 공급업체는 여기에 설명된 양자화 방식을 구현하는 것이 좋습니다.