
Nov 7, 2024
Supercharging AI Coding Assistants with Gemini Models' Long Context

One of the most exciting frontiers in the application of long-context windows is code generation and understanding. Large codebases require a deep understanding of complex relationships and dependencies, something traditional AI models struggle to grasp. By expanding the amount of code with large context windows, we can unlock a new level of accuracy and usefulness in code generation and understanding.
We partnered with Sourcegraph, the creators of the Cody AI coding assistant that supports LLMs like Gemini 1.5 Pro and Flash, to explore the potential of long context windows in real-world coding scenarios. Sourcegraph's focus on integrating code search and intelligence into AI code generation, and successful deployment of Cody to enterprises with large, complex codebases such as Palo Alto Networks and Leidos, made them the ideal partner for this exploration.
Sourcegraph's Approach and Results
Sourcegraph compared Cody's performance with a 1M token context window (using Google's Gemini 1.5 Flash) against its production version. This direct comparison allowed them to isolate the benefits of expanded context. They focused on technical question answering, a crucial task for developers working with large codebases. They used a dataset of challenging questions that required deep code understanding.
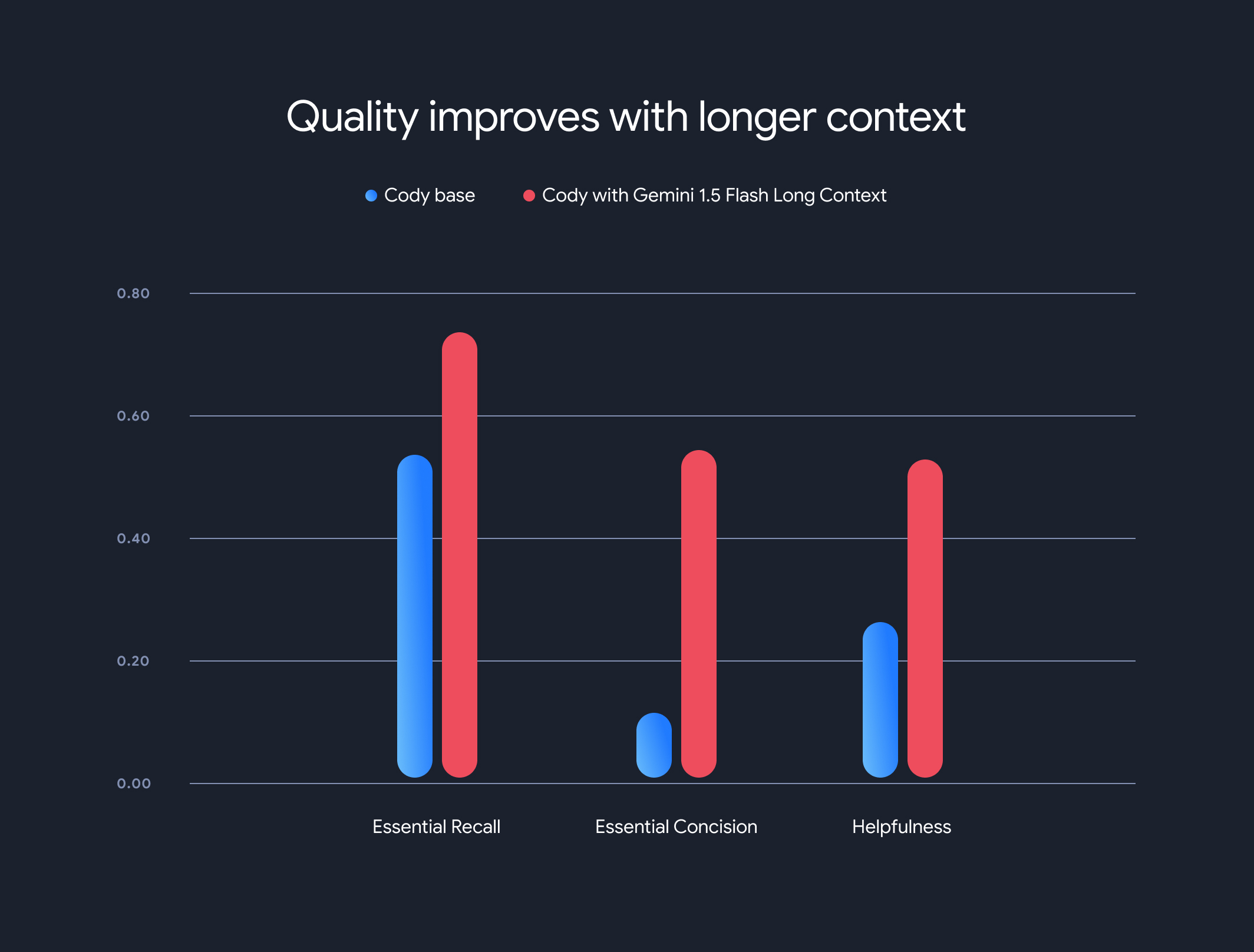
The results were striking. Three of Sourcegraph's key benchmarks—Essential Recall, Essential Concision, and Helpfulness—demonstrated significant improvements when using the longer context.
Essential Recall: The proportion of crucial facts in the response increased substantially.
Essential Concision: The proportion of essential facts normalized by response length also improved, indicating more concise and relevant answers.
Helpfulness: The overall helpfulness score, normalized by response length, significantly increased, indicating a more user-friendly experience.
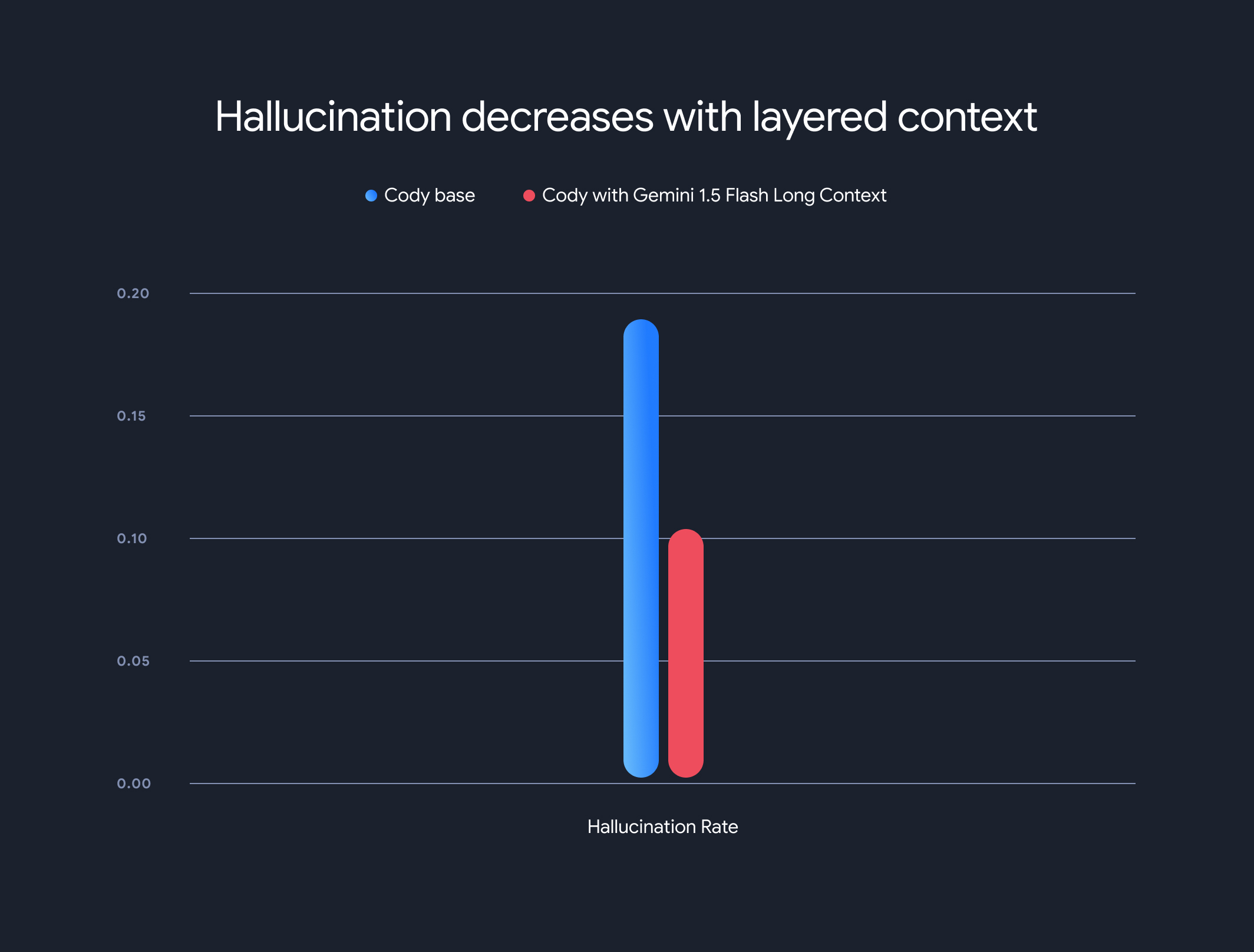
Furthermore, the use of long-context models drastically reduced the overall hallucination rate (the generation of factually incorrect information). The hallucination rate decreased from 18.97% to 10.48%, a significant improvement in accuracy and reliability.
Tradeoffs and Future Direction
While the benefits of long context are significant, there are tradeoffs. The time to first token increases linearly with the length of the context. To mitigate this, Sourcegraph implemented a prefetching mechanism and a layered context model architecture for model execution state caching. With Gemini 1.5 Flash and Pro long-context models, this optimized the time to first token from 30-40 seconds to around 5 seconds for 1MB contexts – a considerable improvement for real-time code generation and technical assistance.
This collaboration showcases the transformative potential of long-context models in revolutionizing code understanding and generation. We're excited to partner with companies like Sourcegraph to continue to unlock even more innovative applications and paradigms with large context windows.
To dive deeper into Sourcegraph's detailed evaluation methodologies, benchmarks, and analysis, including illustrative examples, don't miss their in-depth blog post.
Related case studies

AgentOps
Explore how AgentOps provides cost-effective and powerful LLM-powered agent observability for enterprises using Gemini API.

Sublayer
See how the Ruby-based AI agent framework empowers developer teams to be more productive with the power of Gemini models.

Rooms
Unlocking richer avatar interactions with Gemini 2.0 text and audio capabilities