
Nov 7, 2024
Potencia los asistentes de programación con IA con el contexto extenso de los modelos de Gemini

Una de las fronteras más emocionantes en la aplicación de ventanas de contexto largo es la generación y comprensión de código. Las bases de código grandes requieren una comprensión profunda de las relaciones y dependencias complejas, algo que los modelos de IA tradicionales tienen dificultades para comprender. Si expandimos la cantidad de código con ventanas de contexto grandes, podemos alcanzar un nuevo nivel de precisión y utilidad en la generación y comprensión de código.
Nos asociamos con Sourcegraph, los creadores del asistente de programación con IA Cody, que admite LLM como Gemini 1.5 Pro y Flash, para explorar el potencial de las ventanas de contexto largas en situaciones de programación del mundo real. El enfoque de Sourcegraph en la integración de la búsqueda y la inteligencia de código en la generación de código con IA, y la implementación exitosa de Cody en empresas con bases de código grandes y complejas, como Palo Alto Networks y Leidos, lo convirtieron en el socio ideal para esta exploración.
Enfoque y resultados de Sourcegraph
Sourcegraph comparó el rendimiento de Cody con una ventana de contexto de 1 millón de tokens (con Gemini 1.5 Flash de Google) con su versión de producción. Esta comparación directa les permitió aislar los beneficios del contexto expandido. Se enfocaron en responder preguntas técnicas, una tarea fundamental para los desarrolladores que trabajan con grandes bases de código. Usaron un conjunto de datos de preguntas difíciles que requerían una comprensión profunda del código.
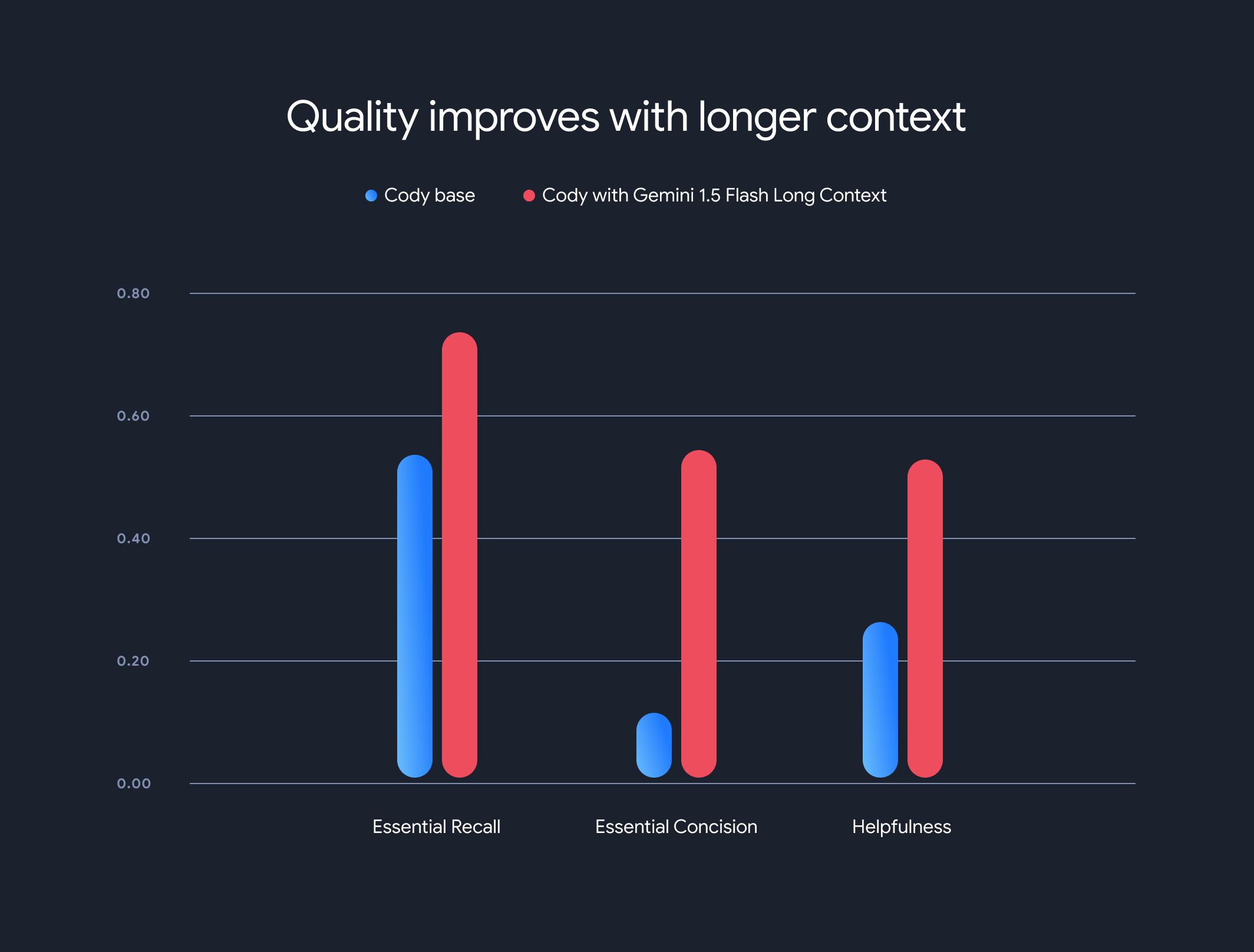
Los resultados fueron sorprendentes. Tres de los principales parámetros de referencia de Sourcegraph (recuperación esencial, concisión esencial y utilidad) demostraron mejoras significativas cuando se usó el contexto más largo.
Essential Recall: La proporción de hechos cruciales en la respuesta aumentó considerablemente.
Concisión esencial: La proporción de hechos esenciales normalizados por la longitud de la respuesta también mejoró, lo que indica respuestas más concisas y pertinentes.
Utilidad: La puntuación general de utilidad, normalizada según la longitud de la respuesta, aumentó significativamente, lo que indica una experiencia más fácil de usar.
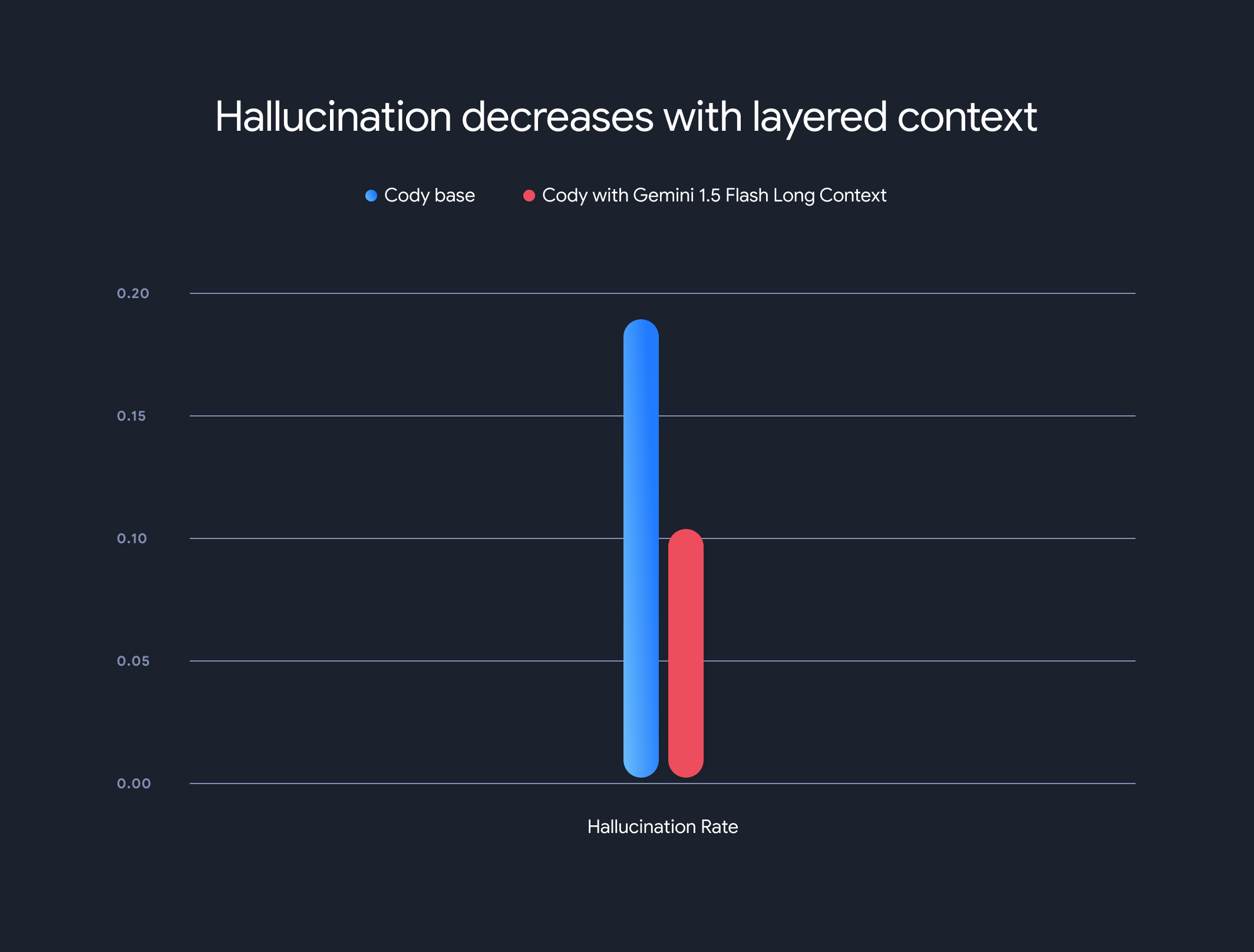
Además, el uso de modelos de contexto extenso redujo drásticamente la tasa general de alucinaciones (la generación de información factualmente incorrecta). La tasa de alucinaciones disminuyó del 18.97% al 10.48%, lo que representa una mejora significativa en la precisión y la confiabilidad.
Compensaciones y dirección futura
Si bien los beneficios del contexto largo son significativos, también hay desventajas. El tiempo hasta el primer token aumenta de forma lineal con la longitud del contexto. Para mitigar este problema, Sourcegraph implementó un mecanismo de recuperación previa y una arquitectura de modelo de contexto en capas para el almacenamiento en caché del estado de ejecución del modelo. Con los modelos de contexto extenso Gemini 1.5 Flash y Pro, se optimizó el tiempo hasta el primer token de 30 a 40 segundos a alrededor de 5 segundos para contextos de 1 MB, lo que representa una mejora considerable para la generación de código en tiempo real y la asistencia técnica.
Esta colaboración muestra el potencial transformador de los modelos de contexto extenso para revolucionar la comprensión y la generación de código. Nos complace asociarnos con empresas como Sourcegraph para seguir desbloqueando aplicaciones y paradigmas aún más innovadores con ventanas de contexto grandes.
Para obtener más información sobre las metodologías de evaluación, las comparativas y el análisis detallados de Sourcegraph, incluidos ejemplos ilustrativos, no te pierdas su entrada de blog detallada.
Casos de éxito relacionados

AgentOps
Explora cómo AgentOps proporciona una observabilidad de agentes potenciados por LLM potente y rentable para las empresas que usan la API de Gemini.

Subcapa
Descubre cómo el framework de agentes de IA basado en Ruby permite que los equipos de desarrolladores sean más productivos con el poder de los modelos de Gemini.

Habitaciones
Interacciones más enriquecidas con avatares gracias a las capacidades de texto y audio de Gemini 2.0