
बेंचमार्क टूल
TensorFlow Lite के मानदंड टूल, फ़िलहाल नीचे दी गई ज़रूरी परफ़ॉर्मेंस मेट्रिक के आंकड़ों को मापते हैं और उनका हिसाब लगाते हैं:
- शुरू करने का समय
- वॉर्मअप की स्थिति का अनुमान
- स्थिर स्थिति का अनुमान समय
- शुरू करने के दौरान मेमोरी का इस्तेमाल
- कुल मेमोरी का इस्तेमाल
मानदंड टूल, Android और iOS के लिए बेंचमार्क ऐप्लिकेशन के तौर पर और नेटिव कमांड-लाइन बाइनरी के तौर पर उपलब्ध हैं. साथ ही, ये सभी परफ़ॉर्मेंस को मापने का एक ही सिद्धांत शेयर करते हैं. ध्यान दें कि रनटाइम एनवायरमेंट में अंतर की वजह से, उपलब्ध विकल्प और आउटपुट फ़ॉर्मैट थोड़े अलग होते हैं.
Android का मानदंड ऐप्लिकेशन
Android के साथ मानदंड टूल का इस्तेमाल करने के दो विकल्प हैं. इनमें से एक नेटिव मानदंड बाइनरी है और दूसरी, Android मानक बाइनरी है. इससे, इस बात का बेहतर अंदाज़ा लगाया जा सकता है कि ऐप्लिकेशन में मॉडल कैसा परफ़ॉर्म करेगा. दोनों में से किसी भी तरह, मानक ऐप्लिकेशन में मॉडल के साथ अनुमान चलाने पर, मानदंड टूल की संख्या थोड़ी अलग होगी.
इस Android मानदंड ऐप्लिकेशन में कोई यूज़र इंटरफ़ेस (यूआई) नहीं है. adb कमांड का इस्तेमाल करके, इसे इंस्टॉल करें और चलाएं. इसके बाद, adb logcat कमांड का इस्तेमाल करके नतीजे पाएं.
ऐप्लिकेशन डाउनलोड करना या बनाना
नीचे दिए गए लिंक का उपयोग करके हर रात पहले से बने Android मानदंड ऐप्लिकेशन डाउनलोड करें:
जो Android मानदंड ऐप्लिकेशन, Flex डेलिगेट के ज़रिए TF ops पर काम करते हैं उनके लिए नीचे दिए गए लिंक इस्तेमाल करें:
इन instructions का पालन करके भी ऐप्लिकेशन को सोर्स से बनाया जा सकता है.
मानदंड तैयार करें
मानदंड ऐप्लिकेशन चलाने से पहले, ऐप्लिकेशन इंस्टॉल करें और मॉडल फ़ाइल को नीचे बताए गए तरीके से डिवाइस में पुश करें:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
मानदंड चलाएं
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph एक ज़रूरी पैरामीटर है.
graph:string
TFLite मॉडल फ़ाइल का पाथ.
मानदंड चलाने के लिए, कुछ और वैकल्पिक पैरामीटर तय किए जा सकते हैं.
num_threads:int(डिफ़ॉल्ट=1)
TFLite अनुवादक चलाने के लिए इस्तेमाल किए जाने वाले थ्रेड की संख्या.use_gpu:bool(default=false)
GPU प्रतिनिधि का इस्तेमाल करें.use_xnnpack:bool(डिफ़ॉल्ट=false)
XNNPACK डेलिगेट का इस्तेमाल करें.
आपके इस्तेमाल किए जा रहे डिवाइस के आधार पर, हो सकता है कि इनमें से कुछ विकल्प उपलब्ध न हों या उनका कोई असर न हो. परफ़ॉर्मेंस से जुड़े ऐसे और पैरामीटर जानने के लिए, पैरामीटर देखें जिन्हें मानदंड ऐप्लिकेशन से चलाया जा सकता है.
logcat निर्देश का इस्तेमाल करके, नतीजे देखें:
adb logcat | grep "Inference timings"
मानदंड के नतीजे इस तरह रिपोर्ट किए जाते हैं:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
स्थानीय मानदंड बाइनरी
मानदंड टूल, नेटिव बाइनरी benchmark_model के तौर पर भी दिया जाता है. Linux, Mac, एम्बेड किए गए डिवाइसों, और Android डिवाइसों पर शेल कमांड लाइन से इस टूल को चलाया जा सकता है.
बाइनरी बनाएं या डाउनलोड करें
हर रात पहले से बनी नेटिव कमांड लाइन बाइनरी डाउनलोड करें. इसके लिए, यहां दिए गए लिंक पर जाएं:
रात में पहले से बनी ऐसी बाइनरी जो Flex प्रतिनिधि की मदद से TF ops के साथ काम करती हैं, उनके लिए नीचे दिए गए लिंक का इस्तेमाल करें:
साथ ही, अपने कंप्यूटर पर सोर्स से नेटिव मानदंड बाइनरी भी बनाई जा सकती है.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Android NDK टूलचेन की मदद से बिल्ड करने के लिए, आपको सबसे पहले इस गाइड में दिए गए निर्देशों का पालन करके बिल्ड एनवायरमेंट सेट अप करना होगा या इस गाइड में बताए गए तरीके से डॉकर इमेज का इस्तेमाल करना होगा.
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
मानदंड चलाएं
अपने कंप्यूटर पर मानदंड चलाने के लिए, बाइनरी को शेल से एक्ज़ीक्यूट करें.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
जैसा कि ऊपर बताया गया है, नेटिव कमांड लाइन बाइनरी के साथ, पैरामीटर के उसी सेट का इस्तेमाल किया जा सकता है.
प्रोफ़ाइलिंग मॉडल ऑपरेशन
मानदंड मॉडल बाइनरी की मदद से, आपको मॉडल ऑपरेशन की प्रोफ़ाइल बनाने और हर ऑपरेटर के लागू होने में लगने वाले समय की जानकारी पाने की सुविधा भी मिलती है. ऐसा करने के लिए, शुरू करने के दौरान
--enable_op_profiling=true फ़्लैग को benchmark_model को पास करें. इससे जुड़ी जानकारी यहां दी गई है.
एक ही बार में कई परफ़ॉर्मेंस के विकल्पों के लिए नेटिव मानदंड बाइनरी
एक ही बार में परफ़ॉर्मेंस के कई विकल्पों के मानदंड तय करने के लिए, एक आसान और आसान C++ बाइनरी भी दी जाती है. यह बाइनरी ऊपर बताए गए मानदंड टूल के आधार पर बनाई गई है. यह टूल एक बार में सिर्फ़ एक ही परफ़ॉर्मेंस विकल्प को बेंचमार्क कर सकता है. उनकी बिल्ड/इंस्टॉल/रन प्रोसेस एक ही होती है, लेकिन इस बाइनरी का BUILD टारगेट नाम
benchmark_model_performance_options है. इसके लिए कुछ अतिरिक्त पैरामीटर की ज़रूरत होती है.
इस बाइनरी के लिए एक अहम पैरामीटर यह है:
perf_options_list: string (default='all')
मानदंड के लिए TFLite से जुड़े परफ़ॉर्मेंस विकल्पों की कॉमा-सेपरेटेड लिस्ट.
इस टूल के लिए, हर रात पहले से बनी बाइनरी मिल सकती हैं, जैसा कि यहां बताया गया है:
iOS मानदंड ऐप्लिकेशन
iOS डिवाइस पर मानदंड चलाने के लिए, आपको सोर्स से ऐप्लिकेशन बनाना होगा.
TensorFlow Lite मॉडल फ़ाइल को सोर्स ट्री की benchmark_data डायरेक्ट्री में रखें और benchmark_params.json फ़ाइल में बदलाव करें. उन फ़ाइलों को ऐप्लिकेशन में पैकेज किया जाता है और ऐप्लिकेशन, डायरेक्ट्री से डेटा को पढ़ता है. ज़्यादा जानकारी के लिए,
iOS मानदंड ऐप्लिकेशन
पर जाएं.
जाने-माने मॉडल की परफ़ॉर्मेंस के मानदंड
इस सेक्शन में, कुछ Android और iOS डिवाइसों पर जाने-माने मॉडल चलाते समय, TensorFlow Lite की परफ़ॉर्मेंस से जुड़े मानदंड दिए गए हैं.
Android की परफ़ॉर्मेंस के मानदंड
परफ़ॉर्मेंस के ये मानदंड, नेटिव मानक बाइनरी से जनरेट किए गए थे.
Android मानदंड के लिए, सीपीयू अफ़िनिटी को डिवाइस पर बड़े कोर का इस्तेमाल करने के लिए सेट किया गया है, ताकि फ़र्क़ कम हो सके (जानकारी देखें).
यह मान लिया जाता है कि मॉडल को डाउनलोड करके, /data/local/tmp/tflite_models डायरेक्ट्री में अनज़िप किया गया था. मानदंड बाइनरी को इन निर्देशों का इस्तेमाल करके बनाया गया है. साथ ही, यह माना जाता है कि यह /data/local/tmp डायरेक्ट्री में मौजूद है.
मानदंड चलाने के लिए:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
जीपीयू डेलिगेट के साथ चलाने के लिए, --use_gpu=true सेट करें.
नीचे दी गई परफ़ॉर्मेंस वैल्यू, Android 10 पर मेज़र की गई हैं.
| मॉडल का नाम | डिवाइस | सीपीयू (CPU), 4 थ्रेड | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 मि॰से॰ | 6.45 मि॰से॰ |
| Pixel 4 | 14.0 मि॰से॰ | 9.0 मि॰से॰ | |
| Mobilenet_1.0_224 (क्वांट) | Pixel 3 | 13.4 मि॰से॰ | --- |
| Pixel 4 | 5.0 मि॰से॰ | --- | |
| NASNet मोबाइल | Pixel 3 | 56 मि॰से॰ | --- |
| Pixel 4 | 34.5 मि॰से॰ | --- | |
| SqueezeNet | Pixel 3 | 35.8 मि॰से॰ | 9.5 मि॰से॰ |
| Pixel 4 | 23.9 मि॰से॰ | 11.1 मि॰से॰ | |
| Inception_ResNet_V2 | Pixel 3 | 422 मि॰से॰ | 99.8 मि॰से॰ |
| Pixel 4 | 272.6 मि॰से॰ | 87.2 मि॰से॰ | |
| Inception_V4 | Pixel 3 | 486 मि॰से॰ | 93 मि॰से॰ |
| Pixel 4 | 324.1 मि॰से॰ | 97.6 मि॰से॰ |
iOS की परफ़ॉर्मेंस के मानदंड
परफ़ॉर्मेंस के ये मानदंड नंबर iOS मानदंड ऐप्लिकेशन से जनरेट किए गए थे.
iOS मानदंड चलाने के लिए, मानदंड ऐप्लिकेशन में बदलाव किया गया था, ताकि उसमें सही मॉडल शामिल किया जा सके. साथ ही, benchmark_params.json को बदलकर, num_threads को 2 पर सेट किया गया हो. जीपीयू डेलिगेट का इस्तेमाल करने के लिए, "use_gpu" : "1" और "gpu_wait_type" : "aggressive" विकल्प भी benchmark_params.json में जोड़े गए हैं.
| मॉडल का नाम | डिवाइस | सीपीयू (CPU), 2 थ्रेड | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 मि॰से॰ | 3.4 मि॰से॰ |
| Mobilenet_1.0_224 (क्वांट) | iPhone XS | 11 मि॰से॰ | --- |
| NASNet मोबाइल | iPhone XS | 30.4 मि॰से॰ | --- |
| SqueezeNet | iPhone XS | 21.1 मि॰से॰ | 15.5 मि॰से॰ |
| Inception_ResNet_V2 | iPhone XS | 261.1 मि॰से॰ | 45.7 मि॰से॰ |
| Inception_V4 | iPhone XS | 309 मि॰से॰ | 54.4 मि॰से॰ |
TensorFlow Lite के इंटरनल डेटा को ट्रेस करें
Android में TensorFlow Lite की इंटर्नल ट्रेस करें
Android ट्रेसिंग टूल की मदद से, किसी Android ऐप्लिकेशन के TensorFlow Lite अनुवादक के इंटरनल इवेंट कैप्चर किए जा सकते हैं. ये Android Trace API के साथ ही इवेंट होते हैं. इसलिए, Java/Kotlin कोड से कैप्चर किए गए इवेंट, TensorFlow Lite के इंटरनल इवेंट के साथ देखे जाते हैं.
इवेंट के कुछ उदाहरण:
- ऑपरेटर को शुरू करने की प्रक्रिया
- प्रतिनिधि के ज़रिए ग्राफ़ में बदलाव करना
- टेन्सर का आवंटन
ट्रेस कैप्चर करने के अलग-अलग विकल्पों में से, इस गाइड में Android Studio CPU प्रोफ़ाइलर और System Tracing ऐप्लिकेशन के बारे में जानकारी दी गई है. दूसरे विकल्पों के लिए Perfetto कमांड-लाइन टूल या Systrace कमांड-लाइन टूल देखें.
Java कोड में ट्रेस इवेंट जोड़ना
यह कोड स्निपेट है, जो
इमेज क्लासिफ़िकेशन
उदाहरण ऐप्लिकेशन से लिया गया है. TensorFlow Lite अनुवादक,
recognizeImage/runInference सेक्शन में चलता है. यह चरण ज़रूरी नहीं है, लेकिन इससे यह जानने में मदद मिलती है
कि अनुमान कॉल कहां किया जा रहा है.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
TensorFlow Lite ट्रेस करने की सुविधा चालू करें
TensorFlow Lite ट्रेस करने की सुविधा चालू करने के लिए, Android ऐप्लिकेशन का इस्तेमाल शुरू करने से पहले Android सिस्टम प्रॉपर्टी debug.tflite.trace को 1 पर सेट करें.
adb shell setprop debug.tflite.trace 1
अगर TensorFlow Lite के अनुवाद की सुविधा शुरू होने पर इस प्रॉपर्टी को सेट किया गया है, तो अनुवादक के मुख्य इवेंट (उदाहरण के लिए, ऑपरेटर को शुरू करना) को ट्रेस किया जाएगा.
सभी ट्रेस कैप्चर करने के बाद, प्रॉपर्टी की वैल्यू को 0 पर सेट करके, ट्रेस करने की सुविधा बंद करें.
adb shell setprop debug.tflite.trace 0
Android Studio सीपीयू प्रोफ़ाइलर
Android Studio सीपीयू प्रोफ़ाइलर से ट्रेस कैप्चर करने के लिए, यह तरीका अपनाएं:
सबसे ऊपर मौजूद मेन्यू से, Run > Profile 'app' चुनें.
प्रोफ़ाइलर विंडो दिखने पर, सीपीयू टाइमलाइन में कहीं भी क्लिक करें.
सीपीयू प्रोफ़ाइलिंग मोड में से 'सिस्टम कॉल ट्रेस करें' चुनें.
'रिकॉर्ड करें' बटन दबाएं.
'बंद करें' बटन दबाएं.
ट्रेस के नतीजे की जांच करें.
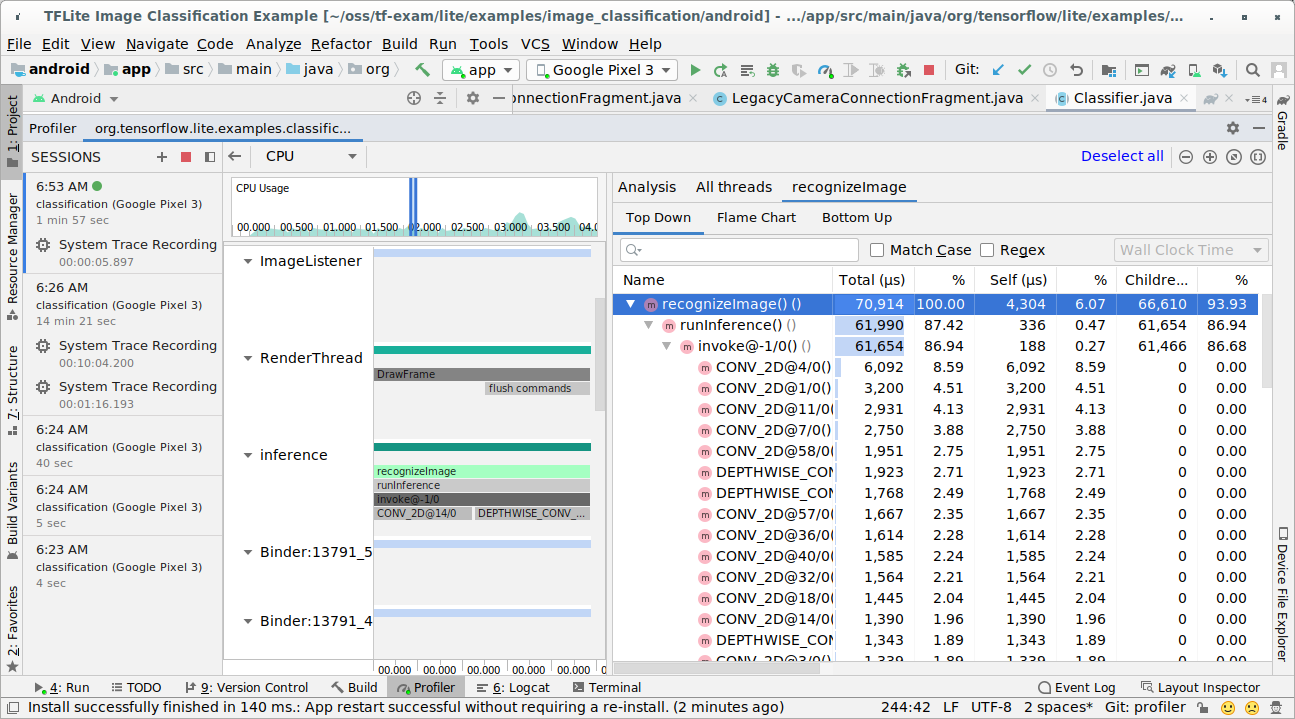
इस उदाहरण में, थ्रेड में इवेंट की हैरारकी और हर ऑपरेटर के समय के आंकड़े देखे जा सकते हैं. साथ ही, थ्रेड के बीच पूरे ऐप्लिकेशन का डेटा फ़्लो भी देखा जा सकता है.
सिस्टम ट्रेस करने वाला ऐप्लिकेशन
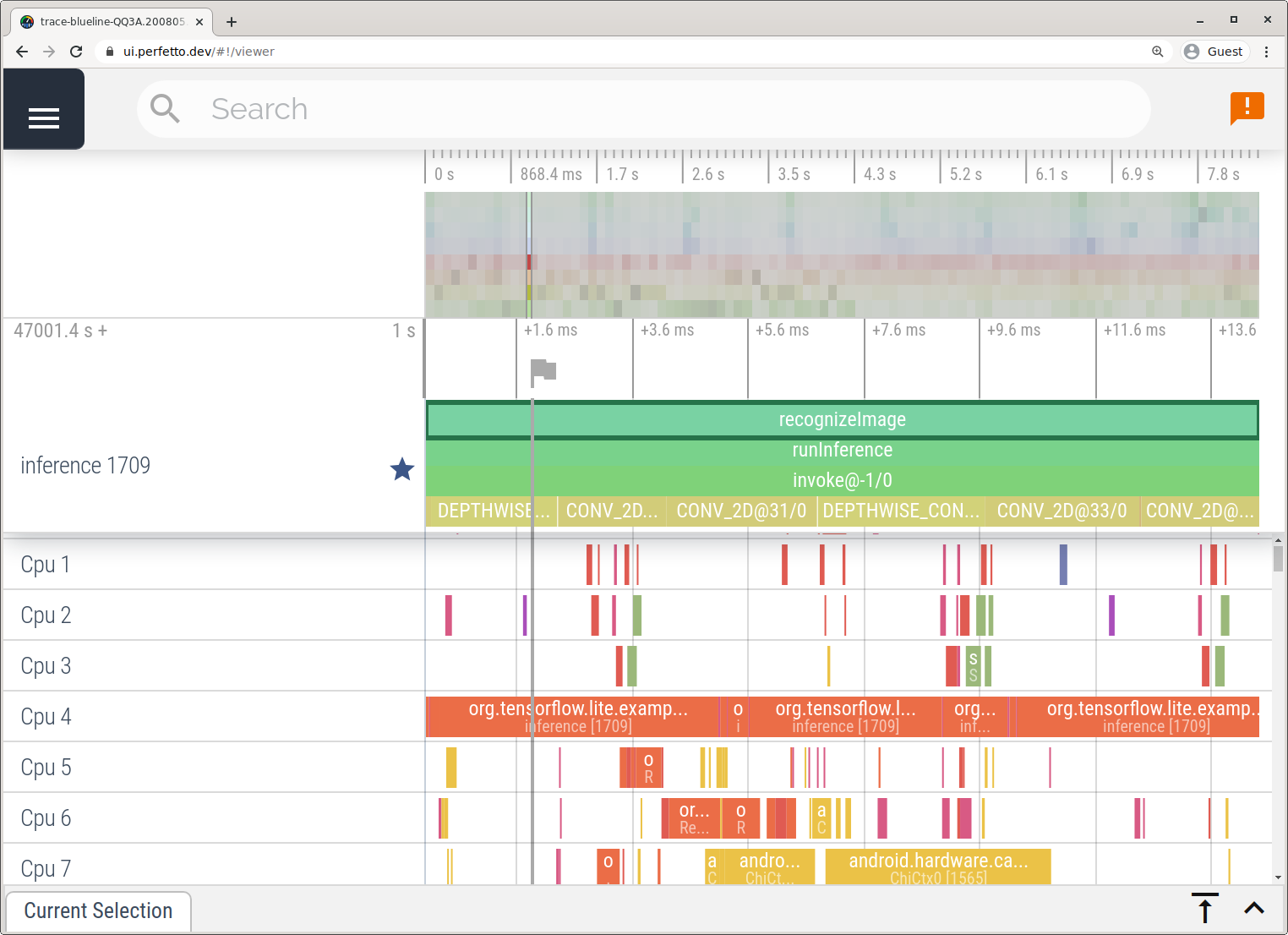
Android Studio के बिना ट्रेस कैप्चर करें. इसके लिए, सिस्टम ट्रेसिंग ऐप्लिकेशन में दिया गया तरीका अपनाएं.
इस उदाहरण में, Android डिवाइस के वर्शन के आधार पर वही TFLite इवेंट कैप्चर किए और सेव किए गए थे. साथ ही, उन्हें Perfetto या Systrace के फ़ॉर्मैट में सेव किया गया था. कैप्चर की गई ट्रेस फ़ाइलें Perfetto यूज़र इंटरफ़ेस (यूआई) में खोली जा सकती हैं.
iOS में TensorFlow Lite की इंटर्नल ट्रेस करें
किसी iOS ऐप्लिकेशन के TensorFlow Lite अनुवादक के इंटरनल इवेंट, Xcode के साथ वाले इंस्ट्रुमेंट टूल से कैप्चर किए जा सकते हैं. ये iOS signpost इवेंट हैं. इसलिए, Swift/Objective-C कोड से कैप्चर किए गए इवेंट, TensorFlow Lite के इंटरनल इवेंट के साथ एक साथ दिखते हैं.
इवेंट के कुछ उदाहरण:
- ऑपरेटर को शुरू करने की प्रक्रिया
- प्रतिनिधि के ज़रिए ग्राफ़ में बदलाव करना
- टेन्सर का आवंटन
TensorFlow Lite ट्रेस करने की सुविधा चालू करें
एनवायरमेंट वैरिएबल debug.tflite.trace को सेट करने के लिए, यह तरीका अपनाएं:
Xcode के सबसे ऊपर दिए मेन्यू से, प्रॉडक्ट > स्कीम > स्कीम में बदलाव करें... चुनें.
बाएं पैनल में 'प्रोफ़ाइल' पर क्लिक करें.
'रन ऐक्शन के आर्ग्युमेंट और एनवायरमेंट वैरिएबल का इस्तेमाल करें' चेकबॉक्स से चुने हुए का निशान हटाएं.
'एनवायरमेंट वैरिएबल' सेक्शन में जाकर,
debug.tflite.traceजोड़ें.
अगर iOS ऐप्लिकेशन की प्रोफ़ाइल बनाते समय TensorFlow Lite इवेंट को बाहर रखना है, तो एनवायरमेंट वैरिएबल को हटाकर, ट्रेस करने की सुविधा को बंद करें.
XCode इंस्ट्रुमेंट
ट्रेस कैप्चर करने के लिए, नीचे दिया गया तरीका अपनाएं:
Xcode के सबसे ऊपर मौजूद मेन्यू से, प्रॉडक्ट > प्रोफ़ाइल चुनें.
इंस्ट्रुमेंट टूल लॉन्च होने पर, प्रोफ़ाइलिंग टेंप्लेट में लॉग करना पर क्लिक करें.
'शुरू करें' बटन दबाएं.
'बंद करें' बटन दबाएं.
ओएस लॉगिंग सबसिस्टम आइटम को बड़ा करने के लिए 'os_signpost' पर क्लिक करें.
'org.tenorflow.lite' ओएस लॉगिंग सबसिस्टम पर क्लिक करें.
ट्रेस के नतीजे की जांच करें.
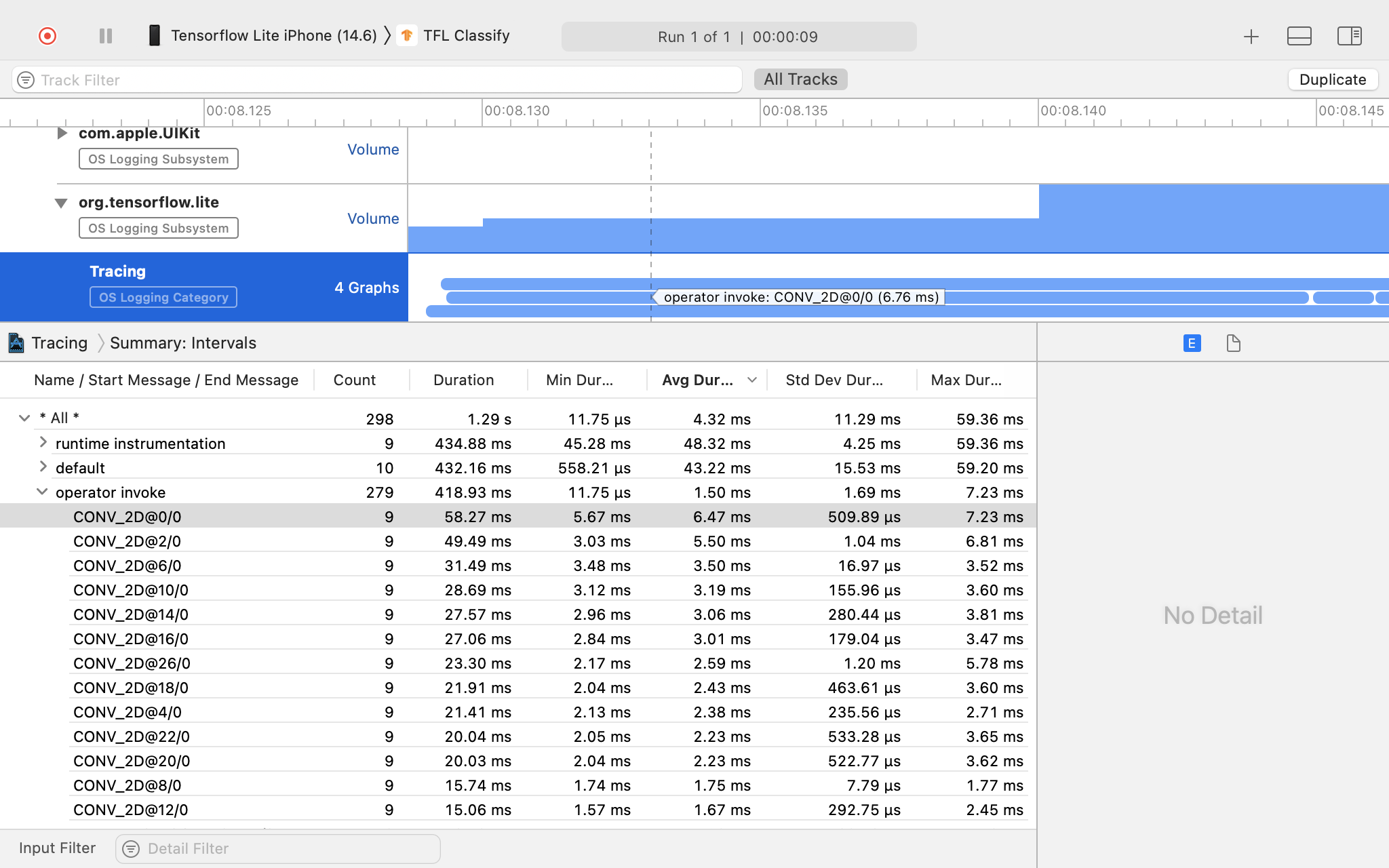
इस उदाहरण में, आप हर एक ऑपरेटर के समय के इवेंट और आंकड़ों की हैरारकी देख सकते हैं.
ट्रेस करने वाले डेटा का इस्तेमाल करना
ट्रेसिंग डेटा की मदद से, परफ़ॉर्मेंस में आ रही रुकावटों की पहचान की जा सकती है.
यहां पर प्रोफ़ाइलर से मिलने वाली जानकारी के कुछ उदाहरण और प्रदर्शन सुधारने के संभावित समाधान दिए गए हैं:
- अगर उपलब्ध सीपीयू (CPU) कोर की संख्या, अनुमान थ्रेड की संख्या से कम है, तो सीपीयू शेड्यूलिंग ओवरहेड की वजह से परफ़ॉर्मेंस खराब हो सकती है. अपने ऐप्लिकेशन में सीपीयू के दूसरे इंटेंसिव टास्क को फिर से शेड्यूल किया जा सकता है, ताकि अपने मॉडल के अनुमान के साथ ओवरलैप होने से बचा जा सके या अनुवादक थ्रेड की संख्या में बदलाव किया जा सके.
- अगर ऑपरेटर को पूरी तरह से ऐक्सेस नहीं दिया जाता है, तो मॉडल ग्राफ़ के कुछ हिस्से, उम्मीद के मुताबिक हार्डवेयर ऐक्सेलरेटर के बजाय सीपीयू पर चलाए जाते हैं. काम न करने वाले ऑपरेटर को, काम करने वाले मिलते-जुलते ऑपरेटर से बदला जा सकता है.