
Ferramentas de comparativo de mercado
Atualmente, as ferramentas de referência do TensorFlow Lite medem e calculam estatísticas para as seguintes métricas de desempenho importantes:
- Tempo de inicialização
- Tempo de inferência do estado de aquecimento
- Tempo de inferência do estado estável
- Uso da memória durante a inicialização
- Uso geral da memória
As ferramentas estão disponíveis como apps comparativos para Android e iOS e como binários de linha de comando nativos. Todas elas compartilham a mesma lógica principal de medição de desempenho. As opções disponíveis e os formatos de saída são um pouco diferentes devido às diferenças no ambiente de execução.
App Android para comparativos de mercado
Há duas opções de usar a ferramenta de comparação com o Android. Um deles é um binário nativo de comparação, e o outro é um app de comparação do Android, que é um indicador melhor do desempenho do modelo no app. De qualquer maneira, os números da ferramenta de comparação ainda serão um pouco diferentes daqueles executados na inferência com o modelo no app real.
Este app para Android comparativo não tem interface. Instale e execute-o usando o comando adb e recupere os resultados usando o comando adb logcat.
Fazer o download ou criar o app
Faça o download dos apps noturnos de comparação pré-criados para Android usando os links abaixo:
Quanto aos apps Android de comparação com suporte a operações do TF via delegate Flex, use os links abaixo:
Você também pode criar o app a partir da fonte seguindo estas instructions.
Preparar comparativo de mercado
Antes de executar o app de comparação, instale-o e envie o arquivo de modelo para o dispositivo da seguinte maneira:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Executar comparação
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph é um parâmetro obrigatório.
graph:string
é o caminho para o arquivo de modelo do TFLite.
É possível especificar mais parâmetros opcionais para executar a comparação.
num_threads:int(padrão=1)
O número de linhas de execução a serem usadas para executar o intérprete do TFLite.use_gpu:bool(default=false)
Use o delegado da GPU.use_xnnpack:bool(padrão=false)
Use delegado XNNPACK.
Dependendo do dispositivo que você estiver usando, algumas dessas opções podem não estar disponíveis ou não ter efeito. Consulte Parâmetros para conferir mais parâmetros de desempenho que podem ser executados com o app de comparação.
Use o comando logcat para conferir os resultados:
adb logcat | grep "Inference timings"
Os resultados do comparativo de mercado são informados como:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Binário nativo de comparativo de mercado
A ferramenta de comparação também é fornecida como um benchmark_model binário nativo. É possível
executar essa ferramenta em uma linha de comando do shell em Linux, Mac, dispositivos incorporados e
dispositivos Android.
Fazer o download ou criar o binário
Faça o download dos binários de linha de comando nativos pré-criados noturnos seguindo os links abaixo:
- linux_x86-64 (em inglês)
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
Quanto aos binários pré-criados noturnos compatíveis com operações do TF via delegado Flex, use os links abaixo:
- linux_x86-64 (em inglês)
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
Você também pode criar o binário de comparação nativo a partir da origem no seu computador.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Para criar com o conjunto de ferramentas do Android NDK, é necessário configurar o ambiente de build primeiro seguindo este guia ou usar a imagem docker, conforme descrito neste guia.
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
Executar comparação
Para fazer comparações no computador, execute o binário no shell.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
Você pode usar o mesmo conjunto de parâmetros mencionado acima com o binário de linha de comando nativo.
Como criar o perfil de operações do modelo
O binário do modelo de comparação também permite criar o perfil das operações do modelo e conferir os
tempos de execução de cada operador. Para fazer isso, transmita a flag
--enable_op_profiling=true para benchmark_model durante a invocação. Confira os detalhes aqui.
Binário nativo de comparação para várias opções de desempenho em uma única execução
Um binário C++ conveniente e simples também é fornecido para
comparar várias opções de desempenho
em uma única execução. Esse binário é criado com base na ferramenta de comparação mencionada
acima, que só pode comparar uma opção de desempenho por vez. Eles compartilham o
mesmo processo de build/instalação/execução, mas o nome de destino BUILD desse binário é
benchmark_model_performance_options e exige alguns parâmetros adicionais.
Um parâmetro importante para esse binário é:
perf_options_list: string (default='all')
Uma lista separada por vírgulas de opções de desempenho do TFLite para comparação.
É possível obter binários pré-criados noturnos para essa ferramenta conforme listado abaixo:
- linux_x86-64 (em inglês)
- linux_aarch64
- linux_arm
- android_aarch64
- android_arm
App iOS para comparativo de mercado
Para executar comparações no dispositivo iOS, é necessário criar o app com base na
origem.
Coloque o arquivo de modelo do TensorFlow Lite no diretório
benchmark_data
da árvore de origem e modifique o arquivo benchmark_params.json. Esses
arquivos são empacotados no aplicativo, que lê os dados do diretório. Acesse
o
app de comparativo de mercado do iOS
para instruções detalhadas.
Comparativos de mercado de desempenho para modelos conhecidos
Esta seção lista os comparativos de mercado de desempenho do TensorFlow Lite ao executar modelos conhecidos em alguns dispositivos Android e iOS.
Comparativos de mercado de desempenho do Android
Esses números do comparativo de mercado de desempenho foram gerados com o binário de comparação nativo.
Em comparações do Android, a afinidade da CPU é configurada para usar núcleos grandes no dispositivo para reduzir a variação. Consulte os detalhes.
Ele pressupõe que os modelos foram transferidos por download e descompactados no
diretório /data/local/tmp/tflite_models. O binário de comparação é criado usando
estas instruções
e está no diretório /data/local/tmp.
Para executar a comparação:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Para executar com o delegado da GPU, defina --use_gpu=true.
Os valores de desempenho abaixo são medidos no Android 10.
| Nome do modelo | Dispositivo | CPU, 4 linhas de execução | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1,0_224 (quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5 ms | --- | |
| NASNet móvel (em inglês) | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
Comparativos de mercado de desempenho do iOS
Esses números foram gerados com o app de comparativo de mercado do iOS.
Para executar comparações do iOS, o app foi modificado para incluir o modelo
adequado, e benchmark_params.json foi definido para definir num_threads como 2. Para usar
o delegado da GPU, as opções "use_gpu" : "1" e "gpu_wait_type" : "aggressive"
também foram adicionadas a benchmark_params.json.
| Nome do modelo | Dispositivo | CPU, 2 linhas de execução | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1,0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet móvel (em inglês) | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
Rastrear os componentes internos do TensorFlow Lite
Rastrear os componentes internos do TensorFlow Lite no Android
Eventos internos do intérprete do TensorFlow Lite de um app Android podem ser capturados pelas ferramentas de rastreamento do Android. Eles são os mesmos eventos que a API Trace do Android, então os eventos capturados do código Java/Kotlin são vistos com os eventos internos do TensorFlow Lite.
Alguns exemplos de eventos são:
- Invocação do operador
- Modificação de gráfico por delegado
- Alocação de tensor
Entre as diferentes opções para a captura de rastros, este guia aborda o CPU Profiler do Android Studio e o app Rastreamento do sistema. Consulte a ferramenta de linha de comando Perfetto ou a ferramenta de linha de comando Systrace para ver outras opções.
Como adicionar eventos de rastreamento no código Java
Este é um snippet de código do app de exemplo
Image Classification. O intérprete do TensorFlow Lite é executado na
seção recognizeImage/runInference. Essa etapa é opcional, mas ajuda a perceber onde a chamada de inferência é feita.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Ativar o rastreamento do TensorFlow Lite
Para ativar o rastreamento do TensorFlow Lite, defina a propriedade do sistema Android
debug.tflite.trace como 1 antes de iniciar o app Android.
adb shell setprop debug.tflite.trace 1
Se essa propriedade tiver sido definida quando o intérprete do TensorFlow Lite for inicializado, os eventos de teclas (por exemplo, invocação do operador) do intérprete serão rastreados.
Depois de capturar todos os rastros, desative o rastreamento definindo o valor da propriedade como 0.
adb shell setprop debug.tflite.trace 0
CPU Profiler do Android Studio
Capture rastros com o CPU Profiler do Android Studio seguindo as etapas abaixo:
Selecione Run > Profile 'app' nos menus superiores.
Clique em qualquer lugar na linha do tempo da CPU quando a janela do Profiler for exibida.
Selecione "Trace System Calls" entre os modos de criação de perfil da CPU.
Pressione o botão "Gravar".
Pressione o botão "Parar".
Investigue o resultado do trace.
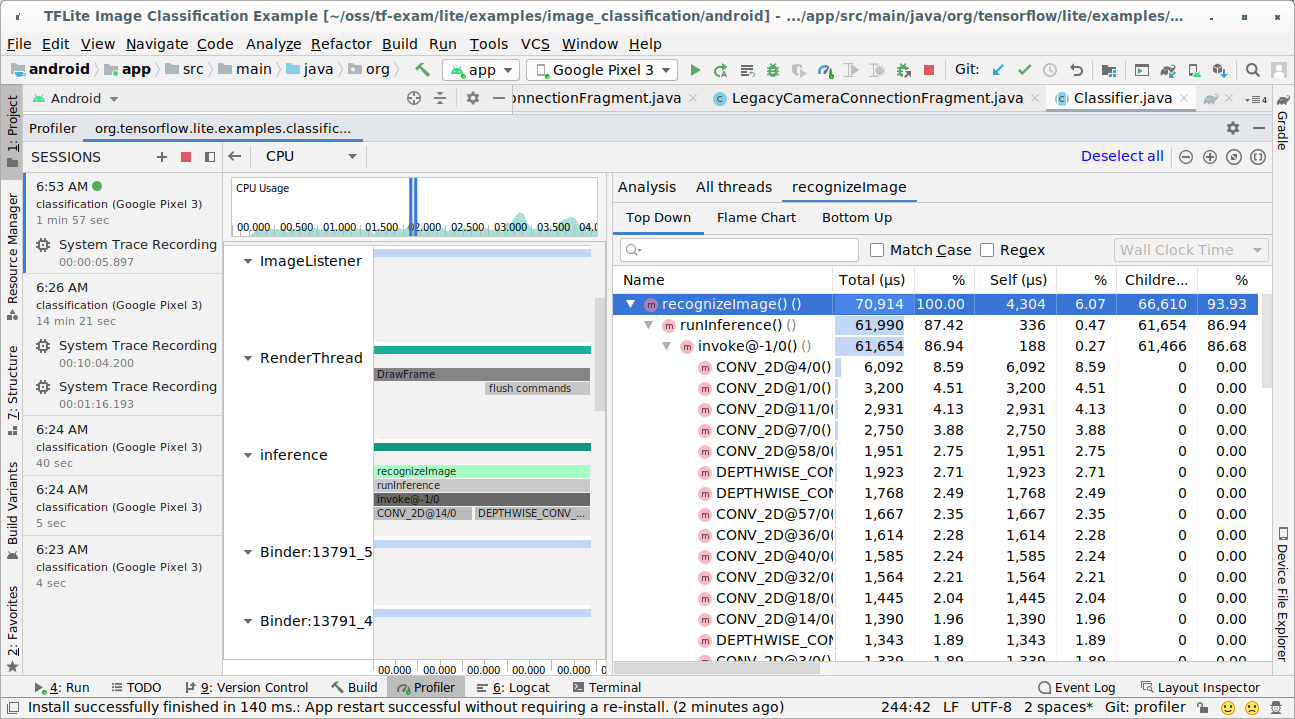
Nesse exemplo, é possível conferir a hierarquia de eventos em uma linha de execução e as estatísticas para cada tempo do operador, além do fluxo de dados de todo o app entre as linhas de execução.
App Rastreamento do sistema
Capture rastros sem o Android Studio seguindo as etapas detalhadas em App Rastreamento do sistema.
Nesse exemplo, os mesmos eventos do TFLite foram capturados e salvos no formato do Perfetto ou do Systrace, dependendo da versão do dispositivo Android. Os arquivos de rastreamento capturados podem ser abertos na interface do Perfetto (link em inglês).
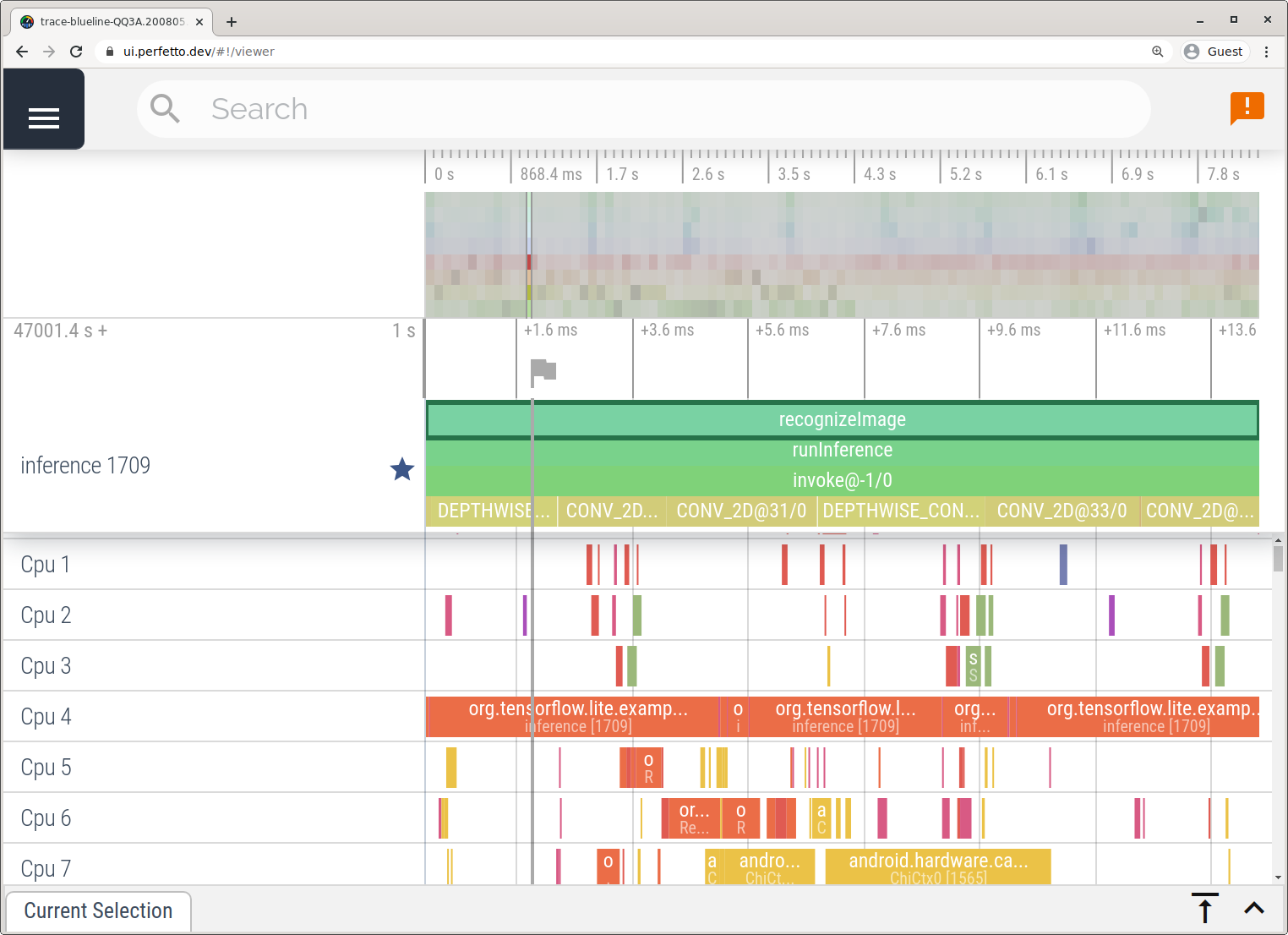
Rastrear os componentes internos do TensorFlow Lite no iOS
Eventos internos do intérprete do TensorFlow Lite de um app iOS podem ser capturados pela ferramenta Instruments incluída no Xcode. Eles são eventos de sinalização do iOS, ou seja, os eventos capturados do código Swift/Objective-C são vistos com os eventos internos do TensorFlow Lite.
Alguns exemplos de eventos são:
- Invocação do operador
- Modificação de gráfico por delegado
- Alocação de tensor
Ativar o rastreamento do TensorFlow Lite
Defina a variável de ambiente debug.tflite.trace seguindo as etapas abaixo:
Selecione Product > Scheme > Edit Scheme... nos menus superiores do Xcode.
Clique em "Perfil" no painel esquerdo.
Desmarque a caixa de seleção "Usar os argumentos e as variáveis de ambiente da ação Executar".
Adicione
debug.tflite.tracena seção "Variáveis de ambiente".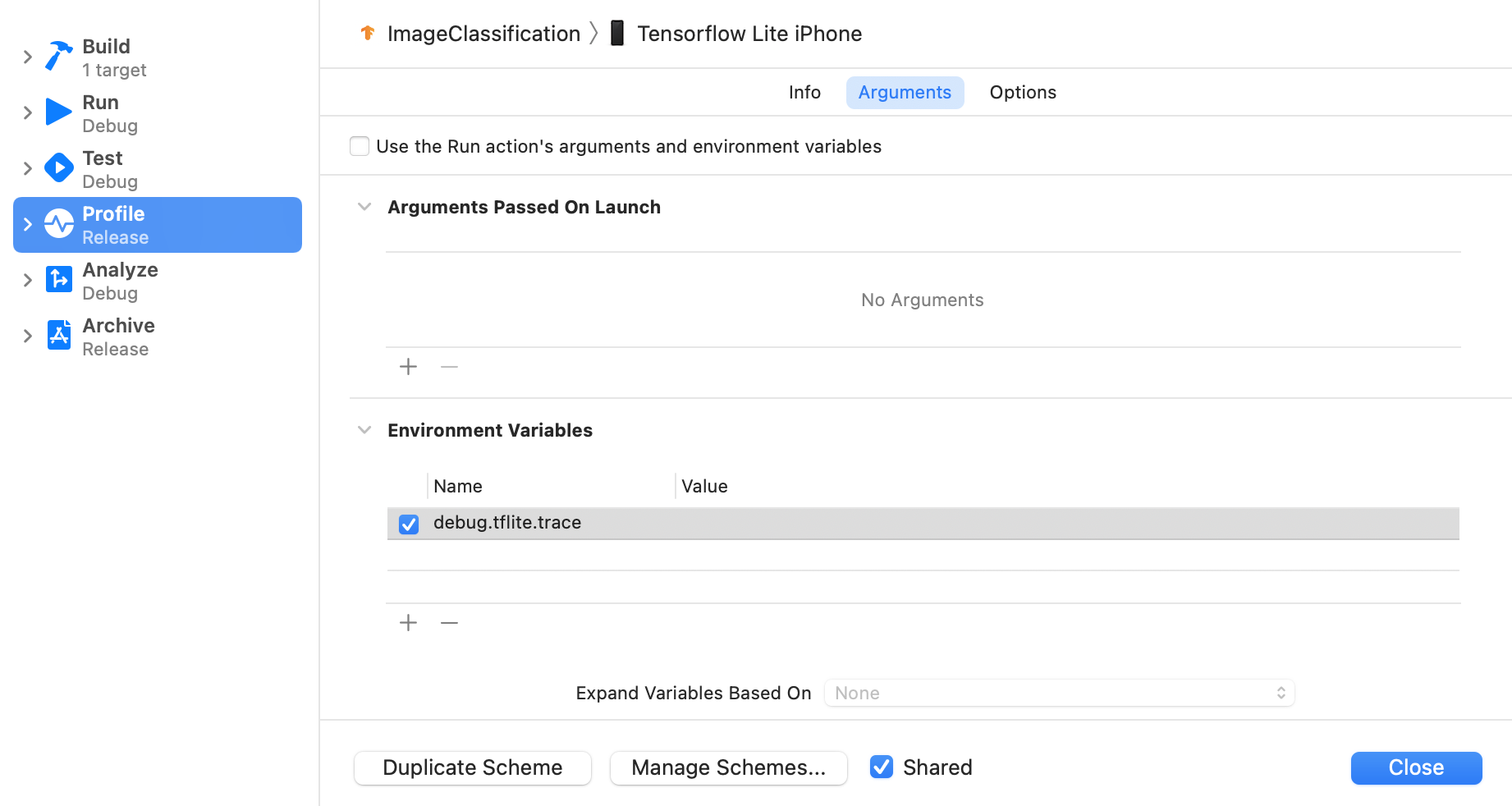
Se você quiser excluir eventos do TensorFlow Lite ao criar o perfil do app iOS, desative o rastreamento removendo a variável de ambiente.
Instrumentos de XCode
Siga as etapas abaixo para capturar rastros:
Selecione Product > Profile nos menus superiores do Xcode.
Clique em Logging entre os modelos de criação de perfil quando a ferramenta Instruments for iniciada.
Pressione o botão "Iniciar".
Pressione o botão "Parar".
Clique em "os_signpost" para expandir os itens de subsistema do OS Logging.
Clique no subsistema do SO Logging "org.tensorflow.lite".
Investigue o resultado do trace.
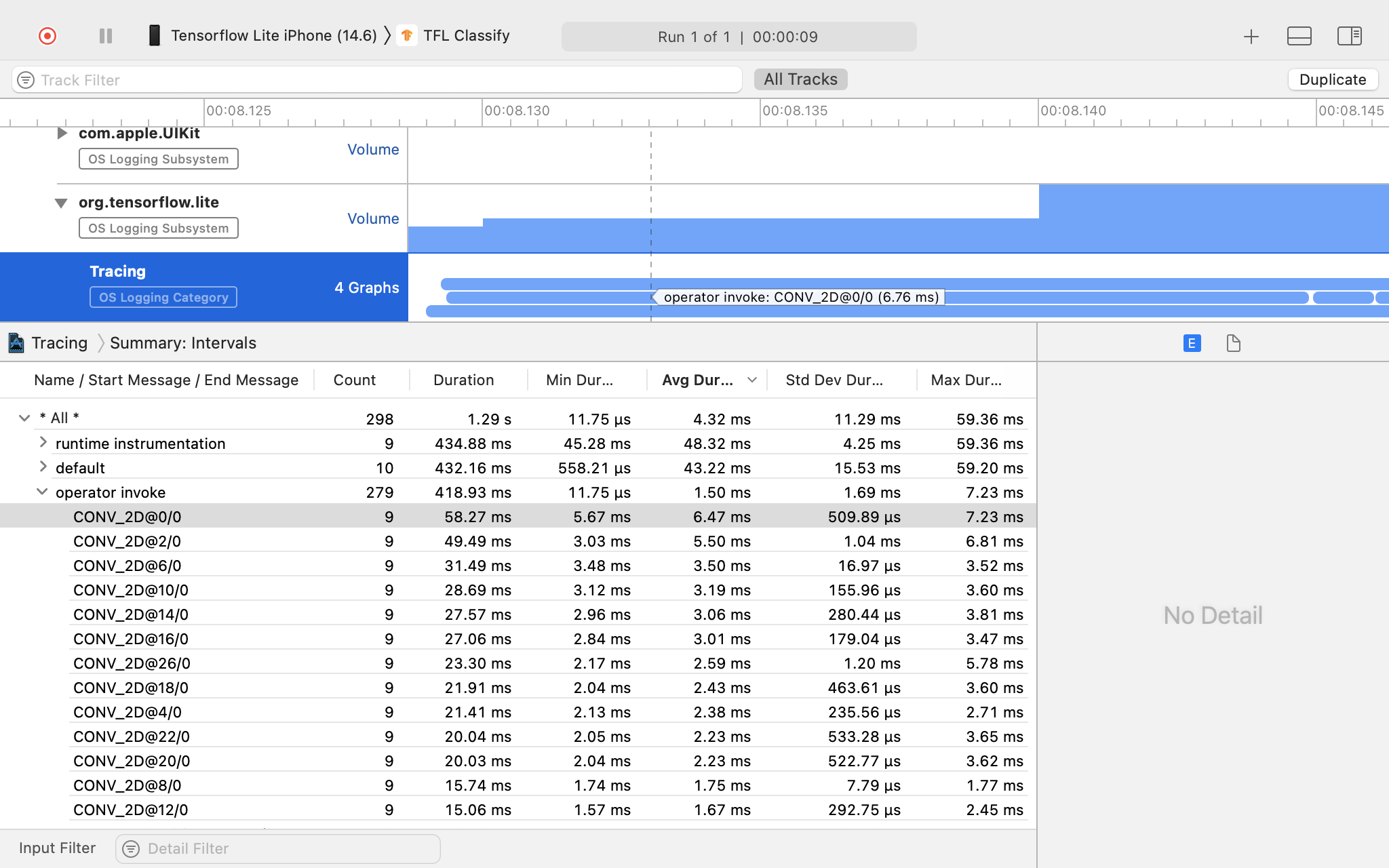
Neste exemplo, é possível conferir a hierarquia de eventos e estatísticas do horário de cada operador.
Como usar os dados de rastreamento
Os dados de rastreamento permitem identificar gargalos de desempenho.
Confira alguns exemplos de insights que o criador de perfil pode extrair e possíveis soluções para melhorar o desempenho:
- Se o número de núcleos de CPU disponíveis for menor que o número de linhas de execução de inferência, a sobrecarga de programação da CPU poderá prejudicar o desempenho. É possível reprogramar outras tarefas com uso intensivo da CPU no aplicativo para evitar a sobreposição com a inferência de modelo ou ajustar o número de linhas de execução do intérprete.
- Se os operadores não forem totalmente delegados, algumas partes do gráfico do modelo serão executadas na CPU em vez do acelerador de hardware esperado. É possível substituir os operadores sem suporte por operadores compatíveis semelhantes.