
توفّر بيانات LiteRT الوصفية معيارًا لأوصاف النماذج. تشكّل البيانات الوصفية مصدرًا مهمًا للمعلومات حول وظيفة النموذج ومعلومات الإدخال والإخراج. تتألف بيانات التعريف من
- أجزاء قابلة للقراءة من قِبل الإنسان تنقل أفضل الممارسات عند استخدام النموذج،
- أجزاء قابلة للقراءة آليًا يمكن الاستفادة منها في أدوات إنشاء الرموز البرمجية، مثل أداة إنشاء الرموز البرمجية لنظام التشغيل Android في LiteRT وميزة ربط تعلُّم الآلة في "استوديو Android".
تمت إضافة بيانات وصفية إلى جميع نماذج الصور المنشورة على Kaggle Models.
نموذج بتنسيق البيانات الوصفية
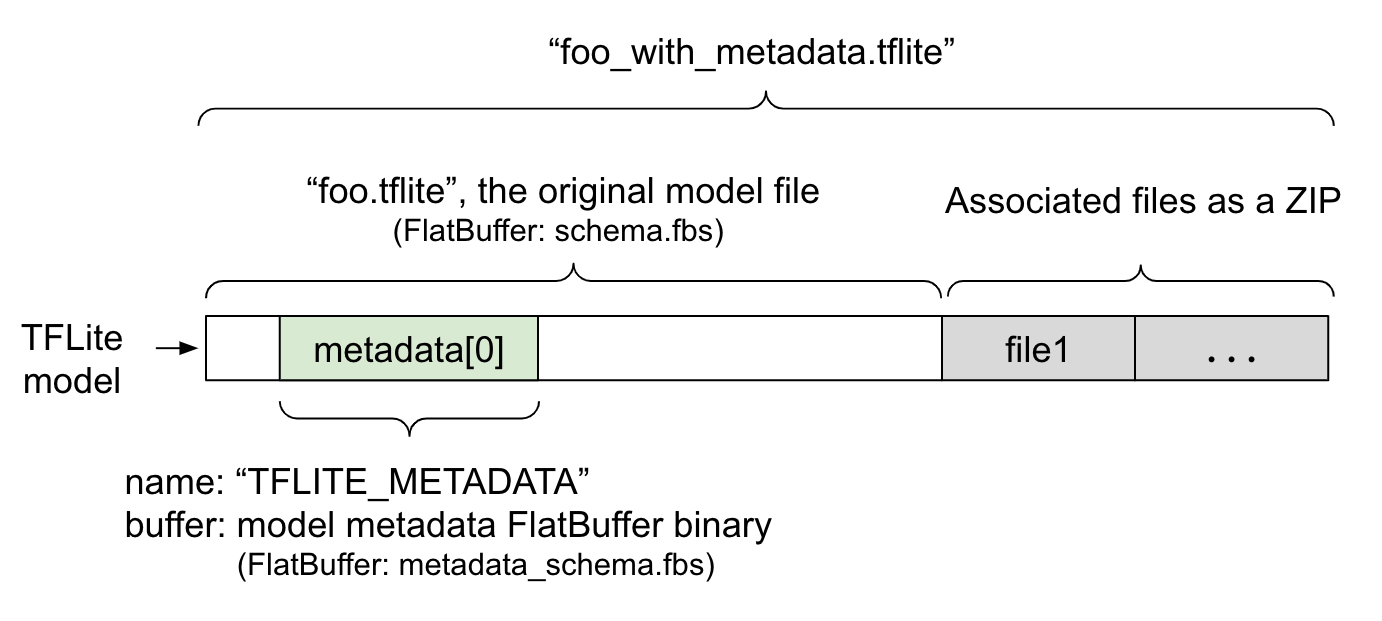
يتم تحديد البيانات الوصفية للنموذج في ملف metadata_schema.fbs، وهو ملف FlatBuffer. كما هو موضّح في الشكل 1، يتم تخزينها في حقل البيانات الوصفية ضمن مخطط نموذج TFLite، تحت الاسم "TFLITE_METADATA". قد تتضمّن بعض النماذج ملفات مرتبطة بها، مثل ملفات تصنيفات.
يتم ربط هذه الملفات بنهاية ملف النموذج الأصلي كملف ZIP
باستخدام وضع "الإلحاق"
في ZipFile (وضع 'a'). يمكن أن يستهلك TFLite
Interpreter تنسيق الملف الجديد بالطريقة نفسها كما كان من قبل. اطّلِع على حزم الملفات المرتبطة للحصول على مزيد من المعلومات.
اطّلِع على التعليمات أدناه حول كيفية ملء البيانات الوصفية وعرضها وقراءتها.
إعداد أدوات البيانات الوصفية
قبل إضافة البيانات الوصفية إلى النموذج، عليك إعداد بيئة برمجة بلغة Python لتشغيل TensorFlow. يتوفّر دليل مفصّل حول كيفية إعداد هذه الميزة هنا.
بعد إعداد بيئة برمجة Python، عليك تثبيت أدوات إضافية:
pip install tflite-support
تتوافق أدوات البيانات الوصفية في LiteRT مع Python 3.
إضافة البيانات الوصفية باستخدام واجهة برمجة التطبيقات Flatbuffers Python
تتضمّن البيانات الوصفية للنموذج في المخطط ثلاثة أجزاء:
- معلومات النموذج: وصف عام للنموذج بالإضافة إلى عناصر مثل بنود الترخيص راجِع ModelMetadata. 2. معلومات الإدخال: وصف للمدخلات والمعالجة المسبقة المطلوبة، مثل التسوية راجِع SubGraphMetadata.input_tensor_metadata. 3- معلومات حول الناتج: وصف للناتج والمعالجة اللاحقة المطلوبة، مثل الربط بالتصنيفات. راجِع SubGraphMetadata.output_tensor_metadata.
بما أنّ LiteRT لا يتيح سوى رسم بياني فرعي واحد في الوقت الحالي، سيستخدم مولّد رموز LiteRT وميزة ربط تعلُّم الآلة في Android Studio الرمزين ModelMetadata.name وModelMetadata.description بدلاً من SubGraphMetadata.name وSubGraphMetadata.description عند عرض البيانات الوصفية وإنشاء الرموز.
أنواع الإدخال والإخراج المتوافقة
لم يتم تصميم البيانات الوصفية لـ LiteRT الخاصة بالمدخلات والمخرجات مع أخذ أنواع نماذج معيّنة في الاعتبار، بل تم تصميمها مع أخذ أنواع المدخلات والمخرجات في الاعتبار. لا يهمّ ما تفعله الدالة النموذجية من الناحية الوظيفية، طالما أنّ أنواع الإدخال والإخراج تتضمّن ما يلي أو مزيجًا مما يلي، فإنّ بيانات TensorFlow Lite الوصفية تتيح ذلك:
- الميزة - الأرقام التي هي أعداد صحيحة غير سالبة أو float32
- الصور - تتوافق البيانات الوصفية حاليًا مع صور RGB والصور ذات التدرّج الرمادي.
- مربّع الحدود: مربّعات حدودية مستطيلة الشكل يتيح المخطط مجموعة متنوعة من أنظمة الترقيم.
تجميع الملفات المرتبطة
قد تتضمّن نماذج LiteRT ملفات مرتبطة مختلفة. على سبيل المثال، تحتوي نماذج اللغة الطبيعية عادةً على ملفات مفردات تربط أجزاء الكلمات بمعرّفات الكلمات، وقد تحتوي نماذج التصنيف على ملفات تصنيفات تشير إلى فئات العناصر. بدون الملفات المرتبطة (إذا كانت متوفرة)، لن يعمل النموذج بشكل جيد.
يمكن الآن تجميع الملفات المرتبطة مع النموذج من خلال مكتبة Python الخاصة بالبيانات الوصفية. يصبح نموذج LiteRT الجديد ملف ZIP يحتوي على النموذج والملفات المرتبطة به. ويمكن فك حزمته باستخدام أدوات zip الشائعة. سيظل هذا التنسيق الجديد للنماذج يستخدم امتداد الملف نفسه، وهو .tflite. وهي متوافقة مع إطار عمل TFLite وInterpreter الحاليين. لمزيد من التفاصيل، يُرجى الاطّلاع على مقالة تضمين البيانات الوصفية للحزمة والملفات المرتبطة بها في النموذج.
يمكن تسجيل معلومات الملف المرتبط في البيانات الوصفية. استنادًا إلى نوع الملف والمكان الذي تم إرفاق الملف به (أي ModelMetadata وSubGraphMetadata وTensorMetadata)، قد يطبّق مولّد رمز LiteRT لنظام التشغيل Android المعالجة المسبقة/اللاحقة المناسبة تلقائيًا على العنصر. راجِع قسم <استخدام إنشاء الرموز> في كل نوع من أنواع ملفات العناصر المرتبطة في المخطط للحصول على مزيد من التفاصيل.
مَعلمات التسوية والتقسيم إلى فئات
التسوية هي إحدى تقنيات المعالجة المسبقة الشائعة للبيانات في تعلُّم الآلة. والهدف من التسوية هو تغيير القيم إلى مقياس مشترك، بدون تشويه الاختلافات في نطاقات القيم.
تكميم النموذج هو أسلوب يسمح بتمثيلات منخفضة الدقة للأوزان، ويمكن أيضًا استخدامه مع عمليات التنشيط لأغراض التخزين والحساب.
في ما يتعلق بالمعالجة المسبقة واللاحقة، فإنّ التسوية والتقسيم إلى كميات هما خطوتان مستقلتان. في ما يلي التفاصيل.
| التسوية | التكميم | |
|---|---|---|
مثال على قيم المَعلمات لصورة الإدخال في MobileNet بالنسبة إلى نماذج الأعداد العشرية ونماذج الكمية، على التوالي. |
نموذج الأعداد العشرية: - mean: 127.5 - std: 127.5 نموذج التكميم: - mean: 127.5 - std: 127.5 |
نموذج الأعداد العشرية: - zeroPoint: 0 - scale: 1.0 نموذج الأعداد الكمية: - zeroPoint: 128.0 - scale:0.0078125f |
حالات الاستخدام |
المدخلات: إذا تم تنميط بيانات الإدخال في التدريب، يجب تنميط بيانات الإدخال الخاصة بالاستدلال وفقًا لذلك. النتائج: لن يتم بشكل عام تسوية بيانات النتائج. |
لا تحتاج نماذج الأعداد العشرية إلى تحديد الكمية. قد يحتاج النموذج الكمّي إلى تكميم في مرحلة المعالجة المسبقة أو اللاحقة، أو قد لا يحتاج إليه. يعتمد ذلك على نوع بيانات موترات الإدخال/الإخراج. - موترات الأعداد العشرية: لا حاجة إلى تحديد الكمية في المعالجة المسبقة أو اللاحقة. يتم تضمين عمليتَي التكميم وإزالة التكميم في الرسم البياني للنموذج. - موترات int8/uint8: يجب إجراء التكميم في المعالجة المسبقة/اللاحقة. |
الصيغة |
normalized_input = (input - mean) / std |
التقسيم إلى شرائح للقيم المدخلة:
q = f / scale + zeroPoint إلغاء التقسيم إلى شرائح للقيم الناتجة: f = (q - zeroPoint) * scale |
أين تظهر المَعلمات؟ |
يملأها منشئ النموذج
ويتم تخزينها في
البيانات الوصفية للنموذج،
على النحو التالي:
NormalizationOptions |
يتم ملء هذا الحقل تلقائيًا بواسطة محوّل TFLite، ويتم تخزينه في ملف نموذج tflite. |
| كيف يمكن الحصول على المَعلمات؟ | من خلال واجهة برمجة التطبيقات
MetadataExtractor
[2]
|
من خلال واجهة برمجة التطبيقات TFLite
Tensor [1] أو
من خلال واجهة برمجة التطبيقات
MetadataExtractor [2] |
| هل تتشارك نماذج float وquant القيمة نفسها؟ | نعم، تتضمّن نماذج الأعداد العشرية ونماذج التكميم معلمات التطبيع نفسها. | لا، لا يحتاج نموذج النقطة العائمة إلى تحديد الكمية. |
| هل تنشئ أداة إنشاء الرموز البرمجية في TFLite أو أداة ربط تعلُّم الآلة في "استوديو Android" تلقائيًا في معالجة البيانات؟ | نعم |
نعم |
[1] LiteRT Java API وLiteRT C++ API
[2] مكتبة استخراج البيانات الوصفية
عند معالجة بيانات الصور لنماذج uint8، يتم أحيانًا تخطّي التسوية والتكميم. لا بأس في ذلك عندما تكون قيم البكسل ضمن النطاق [0, 255]. ولكن بشكل عام، يجب دائمًا معالجة البيانات وفقًا لمعلَمات التسوية والتقسيم إلى فئات عند الاقتضاء.
أمثلة
يمكنك العثور هنا على أمثلة حول كيفية تعبئة بيانات التعريف لأنواع مختلفة من النماذج:
تصنيف الصور
نزِّل النص البرمجي هنا الذي يملأ البيانات الوصفية في mobilenet_v1_0.75_160_quantized.tflite. شغِّل النص البرمجي على النحو التالي:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
لملء البيانات الوصفية لنماذج تصنيف الصور الأخرى، أضِف مواصفات النموذج مثل هذا إلى النص البرمجي. سيسلّط بقية هذا الدليل الضوء على بعض الأقسام الرئيسية في مثال تصنيف الصور لتوضيح العناصر الأساسية.
نظرة معمّقة على مثال تصنيف الصور
معلومات الطراز
تبدأ البيانات الوصفية بإنشاء معلومات نموذج جديدة:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
معلومات الإدخال / الإخراج
يوضّح لك هذا القسم كيفية وصف توقيع الإدخال والإخراج للنموذج. وقد تستخدم مولّدات الرموز التلقائية هذه البيانات الوصفية لإنشاء رموز برمجية للمعالجة المسبقة واللاحقة. لإنشاء معلومات إدخال أو إخراج حول موتر:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
صورة
الصورة هي نوع إدخال شائع لتعلُّم الآلة. تتيح البيانات الوصفية بتنسيق LiteRT معلومات مثل مساحة الألوان ومعلومات المعالجة المسبقة، مثل التسوية. لا يتطلّب بُعد الصورة تحديدًا يدويًا، لأنّه يتم توفيره مسبقًا من خلال شكل موتر الإدخال ويمكن استنتاجه تلقائيًا.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
ناتج التصنيف
يمكن ربط التصنيف بموتر إخراج من خلال ملف مرتبط باستخدام
TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
إنشاء Flatbuffers للبيانات الوصفية
يجمع الرمز التالي معلومات النموذج مع معلومات الإدخال والإخراج:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
تجميع البيانات الوصفية والحزم والملفات المرتبطة في النموذج
بعد إنشاء Flatbuffers للبيانات الوصفية، تتم كتابة البيانات الوصفية وملف التصنيف في ملف TFLite باستخدام الطريقة populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
يمكنك تضمين أي عدد تريده من الملفات المرتبطة في النموذج من خلال
load_associated_files. ومع ذلك، يجب تضمين الملفات المذكورة في البيانات الوصفية على الأقل. في هذا المثال، يجب حزم ملف التصنيف.
تصوُّر البيانات الوصفية
يمكنك استخدام Netron لتصوّر البيانات الوصفية، أو يمكنك قراءة البيانات الوصفية من نموذج LiteRT إلى تنسيق json باستخدام MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
يتيح "استوديو Android" أيضًا عرض البيانات الوصفية من خلال ميزة ربط تعلُّم الآلة في "استوديو Android".
تحديد إصدارات البيانات الوصفية
يتم تحديد إصدار مخطط البيانات الوصفية باستخدام رقم الإصدار الدلالي الذي يتتبّع التغييرات في ملف المخطط، وباستخدام تعريف ملف Flatbuffers الذي يشير إلى توافق الإصدار الفعلي.
رقم الإصدار الدلالي
يتم تحديد إصدار مخطط البيانات الوصفية باستخدام رقم الإصدار الدلالي، مثل MAJOR.MINOR.PATCH. يتتبّع هذا التقرير تغييرات المخطط وفقًا للقواعد الموضّحة هنا.
اطّلِع على سجلّ الحقول التي تمت إضافتها بعد الإصدار 1.0.0.
معرّف ملف Flatbuffers
يضمن نظام تحديد الإصدارات الدلالي التوافق في حال اتّباع القواعد، ولكنّه لا يشير إلى عدم التوافق الفعلي. عند زيادة الرقم MAJOR، لا يعني ذلك بالضرورة أنّ التوافق مع الإصدارات السابقة قد توقّف. لذلك، نستخدم تعريف ملف Flatbuffers، file_identifier، للإشارة إلى التوافق الفعلي لمخطط البيانات الوصفية. يجب أن يتألف معرّف الملف من 4 أحرف بالضبط. ويتم تثبيته على مخطط بيانات وصفية معيّن ولا يمكن للمستخدمين تغييره. إذا كان يجب إيقاف التوافق مع الإصدارات السابقة لمخطط البيانات الوصفية لسبب ما، سيتم رفع رقم تعريف الملف، مثلاً من M001 إلى M002. ومن المتوقّع أن يتم تغيير رقم تعريف الملف بمعدّل أقل بكثير من معدّل تغيير إصدار البيانات الوصفية.
الحد الأدنى للإصدار المطلوب من محلّل البيانات الوصفية
الحد الأدنى لإصدار محلّل البيانات الوصفية اللازم هو الحد الأدنى لإصدار محلّل البيانات الوصفية (الرمز الذي تم إنشاؤه باستخدام Flatbuffers) الذي يمكنه قراءة البيانات الوصفية بالكامل باستخدام Flatbuffers. الإصدار هو في الواقع أكبر رقم إصدار بين إصدارات جميع الحقول التي تم ملؤها وأصغر إصدار متوافق يحدده معرّف الملف. يتم تلقائيًا ملء الحد الأدنى من إصدار محلّل البيانات الوصفية الضروري بواسطة MetadataPopulator عند ملء البيانات الوصفية في نموذج TFLite. راجِع أداة استخراج البيانات الوصفية للحصول على مزيد من المعلومات حول كيفية استخدام الحد الأدنى من إصدار محلّل البيانات الوصفية اللازمة.
قراءة البيانات الوصفية من النماذج
مكتبة Metadata Extractor هي أداة ملائمة لقراءة البيانات الوصفية والملفات المرتبطة بها من نماذج على مستوى منصات مختلفة (راجِع إصدار Java وإصدار C++). يمكنك إنشاء أداة استخراج البيانات الوصفية الخاصة بك بلغات أخرى باستخدام مكتبة Flatbuffers.
قراءة البيانات الوصفية في Java
لاستخدام مكتبة Metadata Extractor في تطبيق Android، ننصحك باستخدام ملف LiteRT Metadata AAR المستضاف على
MavenCentral.
يحتوي على الفئة MetadataExtractor، بالإضافة إلى روابط FlatBuffers Java الخاصة بمخطط البيانات الوصفية ومخطط النموذج.
يمكنك تحديد ذلك في تبعيات build.gradle على النحو التالي:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
لاستخدام اللقطات الليلية، تأكَّد من أنّك أضفت مستودع Sonatype snapshot.
يمكنك تهيئة عنصر MetadataExtractor باستخدام ByteBuffer يشير إلى النموذج:
public MetadataExtractor(ByteBuffer buffer);
يجب أن يظل ByteBuffer بدون تغيير طوال مدة بقاء الكائن MetadataExtractor. قد يتعذّر الإعداد إذا كان معرّف ملف Flatbuffers الخاص بالبيانات الوصفية للنموذج لا يتطابق مع معرّف محلّل البيانات الوصفية. يمكنك الاطّلاع على مقالة
تحديد إصدارات البيانات الوصفية لمزيد من المعلومات.
من خلال معرّفات الملفات المتطابقة، سيتمكّن برنامج استخراج البيانات الوصفية من قراءة البيانات الوصفية التي تم إنشاؤها من جميع المخططات السابقة والمستقبلية بنجاح، وذلك بفضل آلية التوافق مع الإصدارات السابقة واللاحقة من Flatbuffers. ومع ذلك، لا يمكن استخراج الحقول من المخططات المستقبلية باستخدام أدوات استخراج البيانات الوصفية القديمة. يشير الحد الأدنى من إصدار محلّل البيانات الضروري للبيانات الوصفية إلى الحد الأدنى من إصدار محلّل البيانات الوصفية الذي يمكنه قراءة البيانات الوصفية Flatbuffers بالكامل. يمكنك استخدام الطريقة التالية للتحقّق مما إذا كان الحد الأدنى من شرط إصدار المحلّل اللغوي الضروري مستوفيًا:
public final boolean isMinimumParserVersionSatisfied();
يُسمح بتمرير نموذج بدون بيانات وصفية. ومع ذلك، سيؤدي استدعاء الطرق التي تقرأ من البيانات الوصفية إلى حدوث أخطاء أثناء وقت التشغيل. يمكنك التحقّق مما إذا كان أحد النماذج يتضمّن بيانات وصفية من خلال استدعاء طريقة hasMetadata:
public boolean hasMetadata();
توفّر MetadataExtractor دوال ملائمة للحصول على البيانات الوصفية الخاصة بموترات الإدخال/الإخراج. على سبيل المثال:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
على الرغم من أنّ مخطط نموذج LiteRT يتيح استخدام عدة رسومات بيانية فرعية، لا يتيح TFLite Interpreter حاليًا سوى رسم بياني فرعي واحد. لذلك، تحذف MetadataExtractor فهرس الرسم البياني الفرعي كمعلَمة إدخال في طرقها.
قراءة الملفات المرتبطة من النماذج
إنّ نموذج LiteRT الذي يتضمّن البيانات الوصفية والملفات المرتبطة هو في الأساس ملف مضغوط يمكن فك ضغطه باستخدام أدوات الضغط الشائعة للحصول على الملفات المرتبطة. على سبيل المثال، يمكنك فك ضغط mobilenet_v1_0.75_160_quantized واستخراج ملف التصنيف في النموذج على النحو التالي:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
يمكنك أيضًا قراءة الملفات المرتبطة من خلال مكتبة Metadata Extractor.
في Java، مرِّر اسم الملف إلى طريقة MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
وبالمثل، في لغة C++، يمكن إجراء ذلك باستخدام الطريقة التالية:
ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;