
LiteRT 메타데이터는 모델 설명의 표준을 제공합니다. 메타데이터는 모델의 기능과 입력 / 출력 정보에 관한 중요한 지식 소스입니다. 메타데이터는
- 모델 사용 시 권장사항을 전달하는 사람이 읽을 수 있는 부분
- LiteRT Android 코드 생성기 및 Android 스튜디오 ML 결합 기능과 같은 코드 생성기에서 활용할 수 있는 머신 판독 가능 부분
Kaggle 모델에 게시된 모든 이미지 모델은 메타데이터로 채워져 있습니다.
메타데이터 형식이 있는 모델
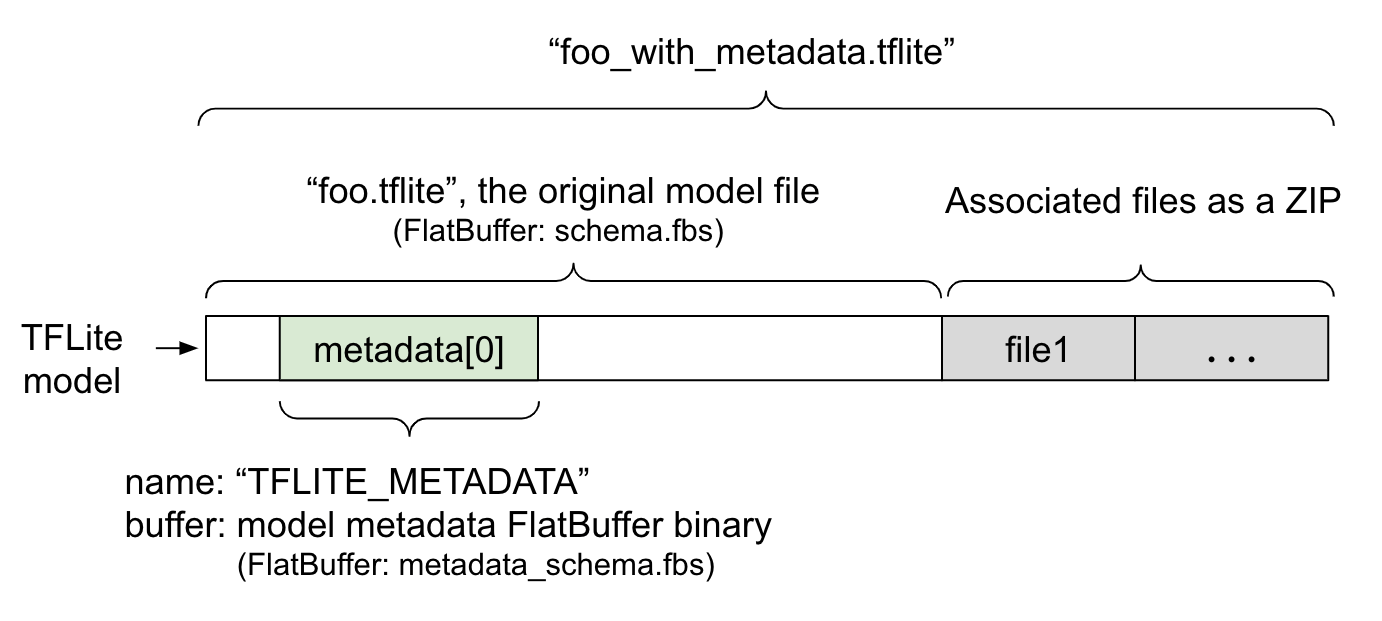
모델 메타데이터는 FlatBuffer 파일인 metadata_schema.fbs에 정의되어 있습니다. 그림 1에 표시된 것처럼 "TFLITE_METADATA"이라는 이름으로 TFLite 모델 스키마의 메타데이터 필드에 저장됩니다. 일부 모델에는 분류 라벨 파일과 같은 연결된 파일이 함께 제공될 수 있습니다.
이러한 파일은 ZipFile 'append' 모드 ('a' 모드)를 사용하여 ZIP으로 원래 모델 파일의 끝에 연결됩니다. TFLite 인터프리터는 이전과 동일한 방식으로 새 파일 형식을 사용할 수 있습니다. 자세한 내용은 연결된 파일 패키징을 참고하세요.
메타데이터를 채우고 시각화하고 읽는 방법에 관한 안내는 아래를 참고하세요.
메타데이터 도구 설정
모델에 메타데이터를 추가하기 전에 TensorFlow를 실행하기 위한 Python 프로그래밍 환경을 설정해야 합니다. 이 기능을 설정하는 방법에 관한 자세한 가이드는 여기에서 확인하세요.
Python 프로그래밍 환경을 설정한 후 추가 도구를 설치해야 합니다.
pip install tflite-support
LiteRT 메타데이터 도구는 Python 3을 지원합니다.
Flatbuffers Python API를 사용하여 메타데이터 추가
스키마의 모델 메타데이터는 세 부분으로 구성됩니다.
- 모델 정보 - 라이선스 약관과 같은 항목뿐만 아니라 모델에 대한 전반적인 설명입니다. ModelMetadata를 참고하세요. 2. 입력 정보 - 입력 및 정규화와 같은 필수 전처리에 관한 설명입니다. SubGraphMetadata.input_tensor_metadata를 참고하세요. 3. 출력 정보 - 출력 및 라벨에 매핑과 같은 사후 처리 필요사항에 관한 설명입니다. SubGraphMetadata.output_tensor_metadata를 참고하세요.
LiteRT는 현재 단일 하위 그래프만 지원하므로 LiteRT 코드 생성기와 Android 스튜디오 ML 결합 기능은 메타데이터를 표시하고 코드를 생성할 때 SubGraphMetadata.name 및 SubGraphMetadata.description 대신 ModelMetadata.name 및 ModelMetadata.description를 사용합니다.
지원되는 입력 / 출력 유형
입력 및 출력용 LiteRT 메타데이터는 특정 모델 유형이 아닌 입력 및 출력 유형을 염두에 두고 설계됩니다. 입력 및 출력 유형이 다음 또는 다음의 조합으로 구성되어 있는 한 모델이 기능적으로 무엇을 하는지는 중요하지 않으며 TensorFlow Lite 메타데이터에서 지원됩니다.
- 특성 - 부호 없는 정수 또는 float32인 숫자입니다.
- 이미지 - 메타데이터는 현재 RGB 및 그레이 스케일 이미지를 지원합니다.
- 경계 상자 - 직사각형 모양의 경계 상자입니다. 스키마는 다양한 번호 매기기 체계를 지원합니다.
연결된 파일 패키징
LiteRT 모델에는 연결된 파일이 다를 수 있습니다. 예를 들어 자연어 모델에는 일반적으로 단어 조각을 단어 ID에 매핑하는 어휘 파일이 있고, 분류 모델에는 객체 카테고리를 나타내는 라벨 파일이 있을 수 있습니다. 연결된 파일이 없으면 모델이 제대로 작동하지 않습니다.
이제 메타데이터 Python 라이브러리를 통해 연결된 파일을 모델과 함께 번들로 묶을 수 있습니다. 새 LiteRT 모델은 모델과 연결된 파일을 모두 포함하는 zip 파일이 됩니다. 일반적인 zip 도구로 압축을 해제할 수 있습니다. 이 새로운 모델 형식은 동일한 파일 확장자 .tflite을 계속 사용합니다. 기존 TFLite 프레임워크 및 인터프리터와 호환됩니다. 자세한 내용은 메타데이터 및 연결된 파일을 모델에 패키징을 참고하세요.
연결된 파일 정보는 메타데이터에 기록할 수 있습니다. 파일 유형과 파일이 첨부된 위치 (예: ModelMetadata, SubGraphMetadata, TensorMetadata)에 따라 LiteRT Android 코드 생성기가 객체에 해당하는 사전/사후 처리를 자동으로 적용할 수 있습니다. 자세한 내용은 스키마의 각 연결 파일 유형의 <코드 생성 사용> 섹션을 참고하세요.
정규화 및 양자화 매개변수
정규화는 머신러닝의 일반적인 데이터 전처리 기법입니다. 정규화의 목표는 값의 범위 차이를 왜곡하지 않고 값을 공통된 스케일로 변경하는 것입니다.
모델 양자화는 저장 및 계산을 위해 가중치와 활성화(선택사항)의 정밀도를 줄여 표현할 수 있는 기법입니다.
전처리 및 후처리 측면에서 정규화와 양자화는 두 개의 독립적인 단계입니다. 세부정보는 다음과 같습니다.
| 정규화 | 양자화 | |
|---|---|---|
부동 소수점 및 양자화 모델의 MobileNet에 있는 입력 이미지의 매개변수 값의 예입니다. |
부동 소수점 모델: - 평균: 127.5 - 표준 편차: 127.5 양자화 모델: - 평균: 127.5 - 표준 편차: 127.5 |
부동 소수점 모델: - zeroPoint: 0 - scale: 1.0 양자화 모델: - zeroPoint: 128.0 - scale:0.0078125f |
언제 호출해야 하나요? |
입력: 학습에서 입력 데이터가 정규화된 경우 추론의 입력 데이터도 그에 따라 정규화해야 합니다. 출력: 출력 데이터는 일반적으로 정규화되지 않습니다. |
부동 소수점 모델에는 양자화가 필요하지 않습니다. 양자화된 모델은 사전/사후 처리에서 양자화가 필요할 수도 있고 필요하지 않을 수도 있습니다. 입력/출력 텐서의 데이터 유형에 따라 달라집니다. - 부동 소수점 텐서: 사전/사후 처리에서 양자화가 필요하지 않습니다. 양자화 작업과 역양자화 작업은 모델 그래프에 포함됩니다. - int8/uint8 텐서: 사전/사후 처리에서 양자화가 필요합니다. |
수식 |
normalized_input = (input - mean) / std |
입력 양자화:
q = f / scale + zeroPoint 출력 역양자화: f = (q - zeroPoint) * scale |
매개변수는 어디에 있나요? |
모델 생성자가 입력하고 모델 메타데이터에 NormalizationOptions로 저장됩니다. |
TFLite 변환기에 의해 자동으로 채워지고 tflite 모델 파일에 저장됩니다. |
| 매개변수를 가져오는 방법 | MetadataExtractor API를 통해 [2]
|
TFLite Tensor API [1] 또는 MetadataExtractor API [2]를 통해 |
| 부동 소수점 모델과 양자화 모델이 동일한 값을 공유하나요? | 예, 부동 소수점 및 양자화 모델에는 동일한 정규화 매개변수가 있습니다. | 아니요, 부동 소수점 모델은 양자화가 필요하지 않습니다. |
| TFLite 코드 생성기 또는 Android 스튜디오 ML 바인딩이 데이터 처리에서 자동으로 생성하나요? | 예 |
예 |
[1] LiteRT Java API 및 LiteRT C++ API
[2] 메타데이터 추출기 라이브러리
uint8 모델의 이미지 데이터를 처리할 때는 정규화와 양자화가 생략되는 경우가 있습니다. 픽셀 값이 [0, 255] 범위에 있는 경우 이렇게 해도 됩니다. 하지만 일반적으로 해당하는 경우 항상 정규화 및 양자화 매개변수에 따라 데이터를 처리해야 합니다.
예
다양한 유형의 모델에 메타데이터를 입력하는 방법의 예는 여기에서 확인할 수 있습니다.
이미지 분류
여기에서 mobilenet_v1_0.75_160_quantized.tflite에 메타데이터를 채우는 스크립트를 다운로드합니다. 다음과 같이 스크립트를 실행합니다.
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
다른 이미지 분류 모델의 메타데이터를 채우려면 이와 같은 모델 사양을 스크립트에 추가합니다. 이 가이드의 나머지 부분에서는 이미지 분류 예의 주요 섹션을 강조하여 핵심 요소를 설명합니다.
이미지 분류 예시 자세히 알아보기
모델 정보
메타데이터는 새 모델 정보를 만들어 시작합니다.
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
입력 / 출력 정보
이 섹션에서는 모델의 입력 및 출력 서명을 설명하는 방법을 보여줍니다. 이 메타데이터는 자동 코드 생성기에서 사전 및 사후 처리 코드를 만드는 데 사용할 수 있습니다. 텐서에 관한 입력 또는 출력 정보를 만들려면 다음을 실행하세요.
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
이미지 입력
이미지는 머신러닝의 일반적인 입력 유형입니다. LiteRT 메타데이터는 색상 공간, 정규화와 같은 사전 처리 정보와 같은 정보를 지원합니다. 이미지의 차원은 입력 텐서의 모양에 의해 이미 제공되고 자동으로 추론될 수 있으므로 수동으로 지정할 필요가 없습니다.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
라벨 출력
라벨은 TENSOR_AXIS_LABELS를 사용하여 연결된 파일을 통해 출력 텐서에 매핑될 수 있습니다.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
메타데이터 Flatbuffer 만들기
다음 코드는 모델 정보를 입력 및 출력 정보와 결합합니다.
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
메타데이터와 연결된 파일을 모델에 패킹
메타데이터 Flatbuffers가 생성되면 메타데이터와 라벨 파일이 populate 메서드를 통해 TFLite 파일에 작성됩니다.
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
load_associated_files을 통해 원하는 만큼 연결된 파일을 모델에 패키징할 수 있습니다. 하지만 메타데이터에 문서화된 파일을 하나 이상 패키징해야 합니다. 이 예에서는 라벨 파일 패키징이 필수입니다.
메타데이터 시각화
Netron을 사용하여 메타데이터를 시각화하거나 MetadataDisplayer를 사용하여 LiteRT 모델에서 json 형식으로 메타데이터를 읽을 수 있습니다.
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android 스튜디오는 Android 스튜디오 ML 바인딩 기능을 통해 메타데이터 표시도 지원합니다.
메타데이터 버전 관리
메타데이터 스키마는 스키마 파일의 변경사항을 추적하는 시맨틱 버전 관리 번호와 실제 버전 호환성을 나타내는 Flatbuffers 파일 식별자로 버전이 지정됩니다.
시맨틱 버전 관리 번호
메타데이터 스키마는 MAJOR.MINOR.PATCH와 같은 시맨틱 버전 관리 번호로 버전이 지정됩니다. 여기의 규칙에 따라 스키마 변경사항을 추적합니다.
버전 1.0.0 이후에 추가된 필드 기록을 참고하세요.
Flatbuffers 파일 식별
시맨틱 버전 관리는 규칙을 따르는 경우 호환성을 보장하지만 실제 비호환성을 의미하지는 않습니다. 주 번호를 올린다고 해서 반드시 이전 버전과의 호환성이 깨지는 것은 아닙니다. 따라서 메타데이터 스키마의 실제 호환성을 나타내기 위해 Flatbuffers 파일 식별자, file_identifier를 사용합니다. 파일 식별자는 정확히 4자(영문 기준)입니다. 특정 메타데이터 스키마로 고정되어 있으며 사용자가 변경할 수 없습니다. 어떤 이유로 메타데이터 스키마의 하위 호환성이 깨져야 하는 경우 file_identifier가 예를 들어 'M001'에서 'M002'로 올라갑니다. file_identifier는 metadata_version보다 훨씬 덜 자주 변경될 것으로 예상됩니다.
필요한 최소 메타데이터 파서 버전
최소 필수 메타데이터 파서 버전은 메타데이터 Flatbuffers를 완전히 읽을 수 있는 메타데이터 파서 (Flatbuffers 생성 코드)의 최소 버전입니다. 버전은 입력된 모든 필드의 버전 중 가장 큰 버전 번호와 파일 식별자로 표시된 가장 작은 호환 버전입니다. 필요한 최소 메타데이터 파서 버전은 메타데이터가 TFLite 모델에 채워질 때 MetadataPopulator에 의해 자동으로 채워집니다. 필요한 최소 메타데이터 파서 버전이 사용되는 방식에 관한 자세한 내용은 메타데이터 추출기를 참고하세요.
모델에서 메타데이터 읽기
Metadata Extractor 라이브러리는 다양한 플랫폼의 모델에서 메타데이터와 연결된 파일을 읽는 데 유용한 도구입니다 (Java 버전 및 C++ 버전 참고). Flatbuffers 라이브러리를 사용하여 다른 언어로 자체 메타데이터 추출기 도구를 빌드할 수 있습니다.
Java에서 메타데이터 읽기
Android 앱에서 Metadata Extractor 라이브러리를 사용하려면 MavenCentral에 호스팅된 LiteRT Metadata AAR을 사용하는 것이 좋습니다.
여기에는 MetadataExtractor 클래스와 메타데이터 스키마 및 모델 스키마의 FlatBuffers Java 바인딩이 포함됩니다.
build.gradle 종속 항목에서 다음과 같이 지정할 수 있습니다.
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
야간 스냅샷을 사용하려면 Sonatype 스냅샷 저장소를 추가해야 합니다.
모델을 가리키는 ByteBuffer로 MetadataExtractor 객체를 초기화할 수 있습니다.
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer는 MetadataExtractor 객체의 전체 기간 동안 변경되지 않아야 합니다. 모델 메타데이터의 Flatbuffers 파일 식별자가 메타데이터 파서의 식별자와 일치하지 않으면 초기화가 실패할 수 있습니다. 자세한 내용은 메타데이터 버전 관리를 참고하세요.
일치하는 파일 식별자를 사용하면 메타데이터 추출기가 Flatbuffers의 순방향 및 역방향 호환성 메커니즘으로 인해 과거 및 미래의 모든 스키마에서 생성된 메타데이터를 성공적으로 읽습니다. 하지만 이전 메타데이터 추출기는 향후 스키마의 필드를 추출할 수 없습니다. 메타데이터의 최소 필수 파서 버전은 메타데이터 Flatbuffer를 완전히 읽을 수 있는 최소 메타데이터 파서 버전을 나타냅니다. 다음 방법을 사용하여 필요한 최소 파서 버전 조건이 충족되는지 확인할 수 있습니다.
public final boolean isMinimumParserVersionSatisfied();
메타데이터가 없는 모델을 전달하는 것은 허용됩니다. 하지만 메타데이터에서 읽어오는 메서드를 호출하면 런타임 오류가 발생합니다. hasMetadata 메서드를 호출하여 모델에 메타데이터가 있는지 확인할 수 있습니다.
public boolean hasMetadata();
MetadataExtractor는 입력/출력 텐서의 메타데이터를 가져오는 편리한 함수를 제공합니다. 예를 들면 다음과 같습니다.
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
LiteRT 모델 스키마는 여러 하위 그래프를 지원하지만 TFLite 인터프리터는 현재 단일 하위 그래프만 지원합니다. 따라서 MetadataExtractor는 메서드에서 하위 그래프 색인을 입력 인수로 생략합니다.
모델에서 연결된 파일 읽기
메타데이터와 관련 파일이 있는 LiteRT 모델은 기본적으로 일반적인 zip 도구로 압축을 풀어 관련 파일을 가져올 수 있는 zip 파일입니다. 예를 들어 mobilenet_v1_0.75_160_quantized의 압축을 풀고 다음과 같이 모델에서 라벨 파일을 추출할 수 있습니다.
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Metadata Extractor 라이브러리를 통해 연결된 파일을 읽을 수도 있습니다.
Java에서는 파일 이름을 MetadataExtractor.getAssociatedFile 메서드에 전달합니다.
public InputStream getAssociatedFile(String fileName);
마찬가지로 C++에서는 ModelMetadataExtractor::GetAssociatedFile 메서드를 사용하여 이를 수행할 수 있습니다.
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;