
LiteRT メタデータは、モデルの説明の標準を提供します。メタデータは、モデルの動作とその入出力情報に関する重要な知識源です。メタデータは、
- モデルを使用する際のベスト プラクティスを伝える人間が読める部分。
- LiteRT Android コード生成ツールや Android Studio ML バインディング機能などのコード生成ツールで利用できる、機械可読な部分。
Kaggle Models で公開されているすべての画像モデルにメタデータが入力されています。
メタデータ形式のモデル
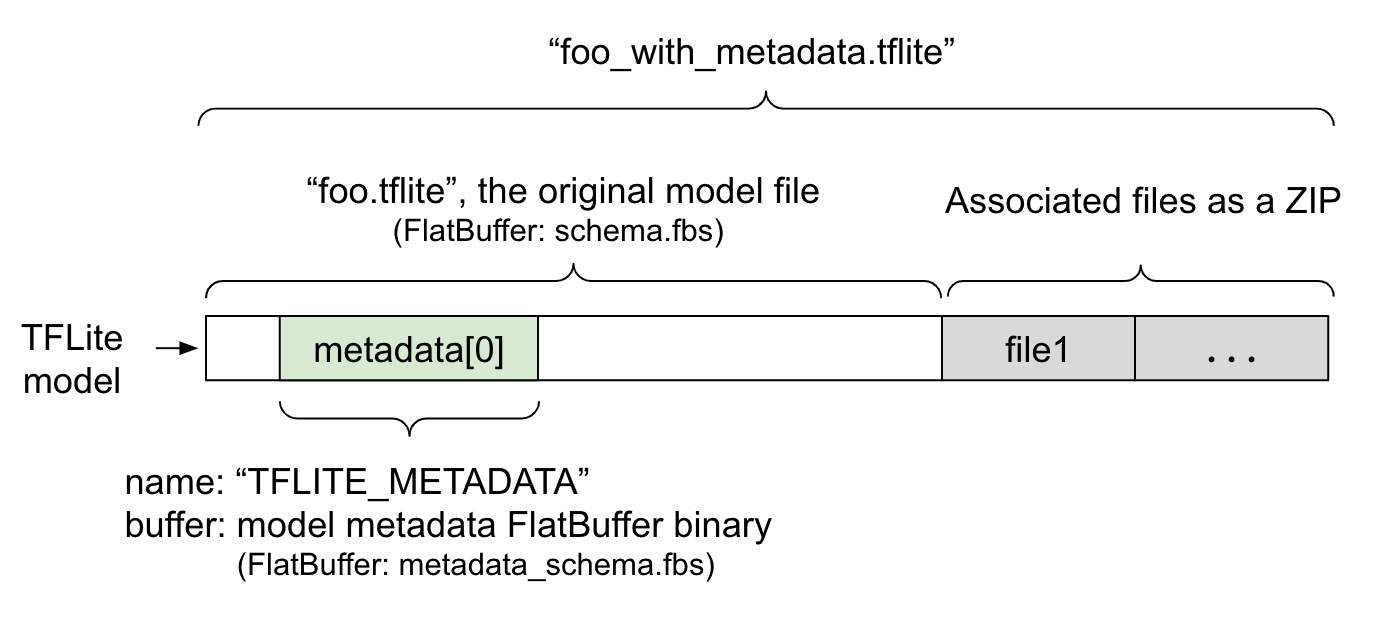
モデル メタデータは、FlatBuffer ファイルである metadata_schema.fbs で定義されます。図 1 に示すように、TFLite モデル スキーマの metadata フィールドに "TFLITE_METADATA" という名前で保存されます。モデルによっては、分類ラベルファイルなどの関連ファイルが付属している場合があります。これらのファイルは、ZipFile の「append」モード('a' モード)を使用して、ZIP として元のモデルファイルの末尾に連結されます。TFLite インタープリタは、以前と同じ方法で新しいファイル形式を使用できます。詳しくは、関連ファイルをパッケージ化するをご覧ください。
メタデータの入力、可視化、読み取り方法については、以下の手順をご覧ください。
メタデータ ツールを設定する
モデルにメタデータを追加する前に、TensorFlow を実行するための Python プログラミング環境を設定する必要があります。設定方法について詳しくは、こちらをご覧ください。
Python プログラミング環境を設定したら、追加のツールをインストールする必要があります。
pip install tflite-support
LiteRT メタデータ ツールは Python 3 をサポートしています。
Flatbuffers Python API を使用したメタデータの追加
スキーマのモデル メタデータは、次の 3 つの部分で構成されています。
- モデル情報 - モデルの概要とライセンス条項などの項目。ModelMetadata をご覧ください。2. 入力情報 - 正規化など、必要な入力と前処理の説明。SubGraphMetadata.input_tensor_metadata をご覧ください。3. 出力情報 - 出力の説明と、ラベルへのマッピングなどの必要な後処理。SubGraphMetadata.output_tensor_metadata をご覧ください。
LiteRT は現時点では単一のサブグラフのみをサポートしているため、LiteRT コード生成ツールと Android Studio ML バインディング機能は、メタデータを表示してコードを生成する際に、SubGraphMetadata.name と SubGraphMetadata.description ではなく ModelMetadata.name と ModelMetadata.description を使用します。
サポートされている入出力の型
入力と出力の LiteRT メタデータは、特定のモデルタイプではなく、入力と出力のタイプを念頭に置いて設計されています。モデルの機能は関係ありません。入力型と出力型が次のいずれか、または次の組み合わせで構成されている限り、TensorFlow Lite メタデータでサポートされます。
- 特徴 - 符号なし整数または float32 の数値。
- 画像 - メタデータは現在、RGB 画像とグレースケール画像をサポートしています。
- 境界ボックス - 長方形の境界ボックス。このスキーマは、さまざまな番号付けスキームをサポートしています。
関連ファイルをパックする
LiteRT モデルには、さまざまな関連ファイルが付属している場合があります。たとえば、自然言語モデルには通常、単語の断片を単語 ID にマッピングする語彙ファイルがあります。分類モデルには、オブジェクト カテゴリを示すラベルファイルがあります。関連ファイル(ある場合)がないと、モデルは正常に機能しません。
関連付けられたファイルは、メタデータ Python ライブラリを使用してモデルにバンドルできるようになりました。新しい LiteRT モデルは、モデルと関連ファイルの両方を含む zip ファイルになります。一般的な zip ツールで解凍できます。この新しいモデル形式では、同じファイル拡張子 .tflite が引き続き使用されます。既存の TFLite フレームワークとインタープリタと互換性があります。詳細については、メタデータと関連ファイルをモデルにパックするをご覧ください。
関連するファイル情報をメタデータに記録できます。ファイルの種類と、ファイルが添付されている場所(ModelMetadata、SubGraphMetadata、TensorMetadata など)に応じて、LiteRT Android コード生成ツールが対応する前処理/後処理をオブジェクトに自動的に適用する場合があります。詳しくは、スキーマの各関連ファイル タイプの <Codegen usage> セクションをご覧ください。
正規化と量子化のパラメータ
正規化は、ML で一般的なデータ前処理手法です。正規化の目的は、値の範囲の差を歪めることなく、値を共通のスケールに変更することです。
モデルの量子化は、ストレージと計算の両方で、重みと(必要に応じて)アクティベーションの精度を下げて表現できるようにする手法です。
前処理と後処理の観点から見ると、正規化と量子化は 2 つの独立したステップです。詳しくは以下をご覧ください。
| 正規化 | 量子化 | |
|---|---|---|
MobileNet の浮動小数点モデルと量子化モデルの入力画像のパラメータ値の例をそれぞれ示します。 |
浮動小数点モデル: - 平均: 127.5 - 標準偏差: 127.5 量子化モデル: - 平均: 127.5 - 標準偏差: 127.5 |
浮動小数点モデル: - zeroPoint: 0 - scale: 1.0 量子化モデル: - zeroPoint: 128.0 - scale:0.0078125f |
呼び出すタイミング |
入力: トレーニングで入力データが正規化されている場合、推論の入力データもそれに応じて正規化する必要があります。 出力: 出力データは一般的に正規化されません。 |
浮動小数点モデルでは量子化は不要です。 量子化モデルでは、前処理/後処理で量子化が必要になる場合と、必要にならない場合があります。入力/出力テンソルのデータ型によって異なります。 - 浮動小数点テンソル: 前処理/後処理で量子化は不要です。Quant オペレーションと dequant オペレーションはモデルグラフに組み込まれています。 - int8/uint8 テンソル: 前処理/後処理で量子化が必要です。 |
数式 |
normalized_input = (input - mean) / std |
入力の量子化:
q = f / scale + zeroPoint 出力の逆量子化: f = (q - zeroPoint) * scale |
パラメータはどこにありますか? |
モデル作成者が入力し、モデル メタデータに NormalizationOptions として保存されます。 |
TFLite コンバータによって自動的に入力され、tflite モデル ファイルに保存されます。 |
| パラメータを取得する方法 | MetadataExtractor API を使用する [2] |
TFLite Tensor API [1] または MetadataExtractor API [2] を使用 |
| float モデルと quant モデルは同じ値を共有しますか? | はい。浮動小数点モデルと量子化モデルの正規化パラメータは同じです。 | いいえ。浮動小数点モデルは量子化を必要としません。 |
| TFLite コード生成ツールまたは Android Studio ML バインディングは、データ処理で自動的に生成されますか? | はい |
はい |
[1] LiteRT Java API と LiteRT C++ API。
[2] メタデータ抽出ライブラリ
uint8 モデルの画像データを処理する場合、正規化と量子化がスキップされることがあります。ピクセル値が [0, 255] の範囲内にある場合は、この方法で問題ありません。ただし、一般的には、正規化と量子化のパラメータに従ってデータを処理する必要があります。
例
さまざまなタイプのモデルのメタデータを入力する方法の例については、こちらをご覧ください。
画像分類
こちらからスクリプトをダウンロードします。このスクリプトは、mobilenet_v1_0.75_160_quantized.tflite にメタデータを入力します。次のようにスクリプトを実行します。
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
他の画像分類モデルのメタデータを入力するには、こちらのようにモデル仕様をスクリプトに追加します。このガイドの残りの部分では、画像分類の例の重要なセクションをいくつか取り上げて、重要な要素を説明します。
画像分類の例の詳細
モデル情報
メタデータは、新しいモデル情報の作成から始まります。
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
入出力情報
このセクションでは、モデルの入力シグネチャと出力シグネチャを記述する方法について説明します。このメタデータは、自動コード生成ツールで前処理コードと後処理コードを作成するために使用されることがあります。テンソルの入力情報または出力情報を作成するには:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
画像入力
画像は、ML の一般的な入力タイプです。LiteRT メタデータは、色空間などの情報や、正規化などの前処理情報をサポートしています。画像のディメンションは入力テンソルの形状によってすでに提供されており、自動的に推論できるため、手動で指定する必要はありません。
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
ラベル出力
ラベルは、TENSOR_AXIS_LABELS を使用して関連付けられたファイルを介して出力テンソルにマッピングできます。
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
メタデータ Flatbuffers を作成する
次のコードは、モデル情報を入力情報と出力情報に結合します。
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
メタデータと関連ファイルをモデルにパックする
メタデータ Flatbuffers が作成されると、メタデータとラベルファイルは populate メソッドを介して TFLite ファイルに書き込まれます。
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
load_associated_files を使用して、必要な数の関連ファイルをモデルにパックできます。ただし、メタデータに記載されているファイルは少なくともパッケージ化する必要があります。この例では、ラベル ファイルのパッキングは必須です。
メタデータを可視化する
Netron を使用してメタデータを可視化するか、MetadataDisplayer を使用して LiteRT モデルから json 形式でメタデータを読み取ることができます。
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio は、Android Studio ML バインディング機能によるメタデータの表示もサポートしています。
メタデータのバージョン管理
メタデータ スキーマは、スキーマ ファイルの変更を追跡するセマンティック バージョニング番号と、実際のバージョン互換性を示す Flatbuffers ファイル識別子の両方でバージョン管理されます。
セマンティック バージョニング番号
メタデータ スキーマは、MAJOR.MINOR.PATCH などのセマンティック バージョニング番号でバージョン管理されます。こちらのルールに従ってスキーマの変更を追跡します。バージョン 1.0.0 以降に追加されたフィールドの履歴をご覧ください。
Flatbuffers ファイルの識別
セマンティック バージョニングは、ルールに従っていれば互換性を保証しますが、真の非互換性を意味するものではありません。MAJOR 番号を増やすことは、必ずしも下位互換性が損なわれることを意味するわけではありません。そのため、Flatbuffers ファイル識別子 file_identifier を使用して、メタデータ スキーマの真の互換性を示します。ファイル識別子は 4 文字です。特定のメタデータ スキーマに固定されており、ユーザーが変更することはできません。なんらかの理由でメタデータ スキーマの下位互換性を破る必要がある場合、file_identifier は「M001」から「M002」のように増加します。file_identifier は、metadata_version よりも変更頻度がはるかに少ないことが想定されています。
必要な最小のメタデータ パーサー バージョン
必要な最小メタデータ パーサー バージョンは、メタデータ Flatbuffers を完全に読み取ることができるメタデータ パーサー(Flatbuffers 生成コード)の最小バージョンです。このバージョンは、入力されたすべてのフィールドのバージョンの中で最も大きいバージョン番号と、ファイル識別子で示される互換性のある最も小さいバージョン番号のうち、大きい方のバージョン番号になります。メタデータが TFLite モデルに入力されると、MetadataPopulator によって必要な最小のメタデータ パーサー バージョンが自動的に入力されます。必要な最小メタデータ パーサー バージョンの使用方法について詳しくは、メタデータ抽出ツールをご覧ください。
モデルからメタデータを読み取る
Metadata Extractor ライブラリは、さまざまなプラットフォームのモデルからメタデータと関連ファイルを読み取るのに便利なツールです(Java バージョンと C++ バージョンをご覧ください)。Flatbuffers ライブラリを使用すると、他の言語で独自のメタデータ抽出ツールを構築できます。
Java でメタデータを読み取る
Android アプリで Metadata Extractor ライブラリを使用するには、MavenCentral でホストされている LiteRT Metadata AAR を使用することをおすすめします。このパッケージには、MetadataExtractor クラスと、メタデータ スキーマとモデル スキーマの FlatBuffers Java バインディングが含まれています。
これは、build.gradle の依存関係で次のように指定できます。
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
ナイトリー スナップショットを使用するには、Sonatype スナップショット リポジトリを追加していることを確認してください。
モデルを指す ByteBuffer を使用して MetadataExtractor オブジェクトを初期化できます。
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer は、MetadataExtractor オブジェクトの全期間にわたって変更されないままにする必要があります。モデル メタデータの Flatbuffers ファイル識別子がメタデータ パーサーの識別子と一致しない場合、初期化が失敗する可能性があります。詳細については、メタデータのバージョニングをご覧ください。
ファイル識別子が一致している場合、Flatbuffers の前方互換性と後方互換性のメカニズムにより、メタデータ抽出ツールは過去と将来のすべてのスキーマから生成されたメタデータを正常に読み取ります。ただし、古いメタデータ抽出ツールでは、将来のスキーマのフィールドを抽出できません。メタデータの最小限必要なパーサー バージョンは、メタデータ Flatbuffers を完全に読み取ることができるメタデータ パーサーの最小バージョンを示します。次の方法で、必要な最小パーサー バージョンの条件が満たされているかどうかを確認できます。
public final boolean isMinimumParserVersionSatisfied();
メタデータのないモデルを渡すことは許可されています。ただし、メタデータから読み取るメソッドを呼び出すと、ランタイム エラーが発生します。モデルにメタデータがあるかどうかを確認するには、hasMetadata メソッドを呼び出します。
public boolean hasMetadata();
MetadataExtractor は、入出力テンソルのメタデータを取得するための便利な関数を提供します。次に例を示します。
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
LiteRT モデルスキーマは複数のサブグラフをサポートしていますが、現在の TFLite インタープリタは 1 つのサブグラフのみをサポートしています。そのため、MetadataExtractor はメソッドの入力引数としてサブグラフ インデックスを省略します。
モデルから関連ファイルを読み取る
メタデータと関連ファイルを含む LiteRT モデルは、基本的に zip ファイルです。一般的な zip ツールで解凍して、関連ファイルを取得できます。たとえば、次のように mobilenet_v1_0.75_160_quantized を解凍して、モデル内のラベルファイルを抽出できます。
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Metadata Extractor ライブラリを使用して、関連付けられたファイルを読み取ることもできます。
Java では、ファイル名を MetadataExtractor.getAssociatedFile メソッドに渡します。
public InputStream getAssociatedFile(String fileName);
同様に、C++ では、ModelMetadataExtractor::GetAssociatedFile メソッドを使用してこれを行うことができます。
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;