
I metadati LiteRT forniscono uno standard per le descrizioni dei modelli. I metadati sono una fonte importante di informazioni su cosa fa il modello e sulle informazioni di input / output. I metadati sono costituiti da
- parti leggibili che trasmettono la best practice per l'utilizzo del modello e
- parti leggibili dalla macchina che possono essere sfruttate dai generatori di codice, come il generatore di codice Android LiteRT e la funzionalità di binding ML di Android Studio.
Tutti i modelli di immagini pubblicati su Kaggle Models sono stati compilati con metadati.
Modello con formato dei metadati
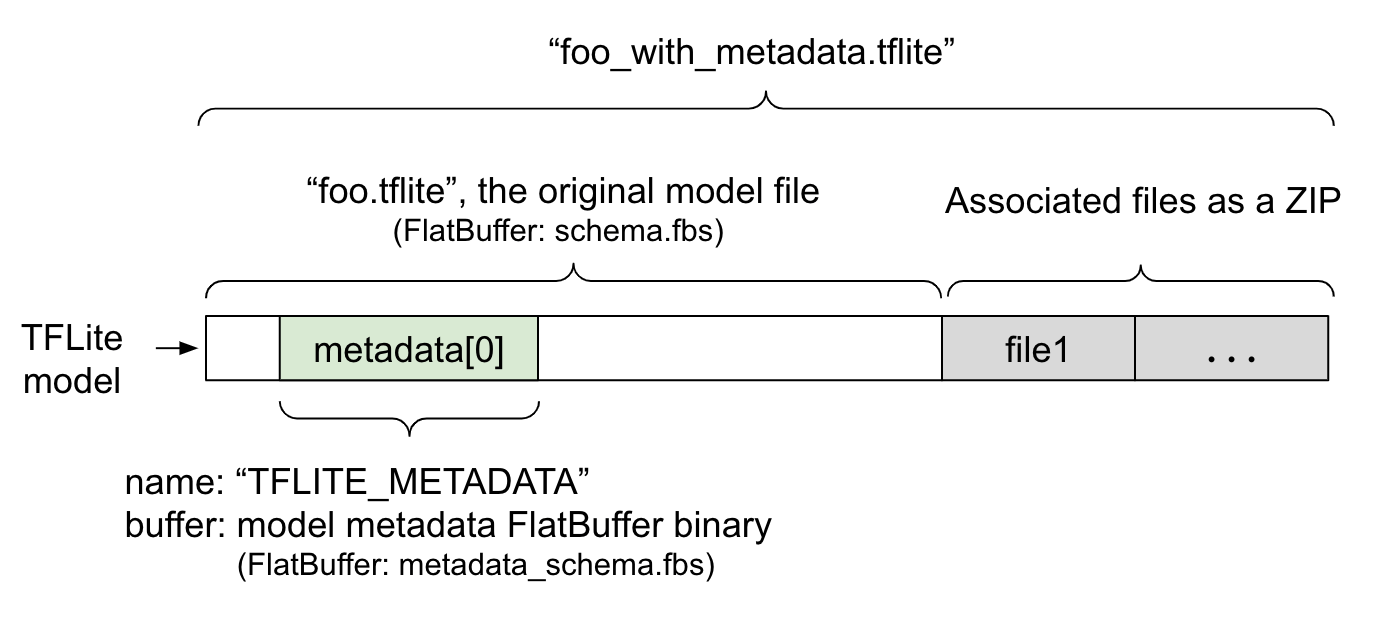
I metadati del modello sono definiti in
metadata_schema.fbs,
un file
FlatBuffer. Come mostrato nella figura 1, viene memorizzato nel campo
metadata
dello schema del modello
TFLite,
con il nome "TFLITE_METADATA". Alcuni modelli potrebbero includere file associati,
come i file di etichette di classificazione.
Questi file vengono concatenati alla fine del file del modello originale come file ZIP
utilizzando la modalità "append" (aggiungi) di ZipFile (modalità 'a'). L'interprete TFLite
può utilizzare il nuovo formato di file come in precedenza. Per ulteriori informazioni, consulta Pacchetto
dei file associati.
Consulta le istruzioni riportate di seguito su come compilare, visualizzare e leggere i metadati.
Configurare gli strumenti per i metadati
Prima di aggiungere metadati al modello, devi configurare un ambiente di programmazione Python per l'esecuzione di TensorFlow. Puoi trovare una guida dettagliata su come configurare questa opzione qui.
Dopo aver configurato l'ambiente di programmazione Python, dovrai installare strumenti aggiuntivi:
pip install tflite-support
Gli strumenti per i metadati LiteRT supportano Python 3.
Aggiunta di metadati utilizzando l'API Python Flatbuffers
I metadati del modello nello schema sono suddivisi in tre parti:
- Informazioni sul modello: descrizione generale del modello e elementi come i termini di licenza. Vedi ModelMetadata. 2. Informazioni di input: descrizione degli input e del pre-elaborazione richiesti, ad esempio la normalizzazione. Vedi SubGraphMetadata.input_tensor_metadata. 3. Informazioni sull'output: descrizione dell'output e post-elaborazione richiesta, ad esempio il mapping alle etichette. Vedi SubGraphMetadata.output_tensor_metadata.
Poiché al momento LiteRT supporta solo un singolo sottografo, il generatore di codice
LiteRT
e la funzionalità di binding ML di Android Studio
utilizzeranno ModelMetadata.name e ModelMetadata.description, anziché
SubGraphMetadata.name e SubGraphMetadata.description, durante la visualizzazione
dei metadati e la generazione del codice.
Tipi di input / output supportati
I metadati LiteRT per input e output non sono progettati pensando a tipi di modelli specifici, ma piuttosto a tipi di input e output. Non importa cosa faccia funzionalmente la funzione del modello, purché i tipi di input e output siano costituiti da quanto segue o da una combinazione di quanto segue, è supportata dai metadati di TensorFlow Lite:
- Funzionalità: numeri interi senza segno o float32.
- Immagine: i metadati attualmente supportano immagini RGB e in scala di grigi.
- Riquadro di delimitazione: riquadri di delimitazione di forma rettangolare. Lo schema supporta una varietà di schemi di numerazione.
Crea un pacchetto dei file associati
I modelli LiteRT potrebbero essere forniti con file associati diversi. Ad esempio, i modelli di linguaggio naturale di solito hanno file di vocabolario che mappano i pezzi di parole agli ID parola; i modelli di classificazione possono avere file di etichette che indicano le categorie di oggetti. Senza i file associati (se presenti), un modello non funzionerà correttamente.
Ora i file associati possono essere raggruppati con il modello tramite la libreria Python dei metadati. Il nuovo modello LiteRT diventa un file ZIP contenente sia il modello sia i file associati. Può essere decompresso con gli strumenti zip comuni. Questo
nuovo formato del modello continua a utilizzare la stessa estensione del file, .tflite. È
compatibile con il framework e l'interprete TFLite esistenti. Per ulteriori dettagli, consulta la sezione Inserire i metadati del pacchetto e i file associati nel modello.
Le informazioni sui file associati possono essere registrate nei metadati. A seconda del tipo di file e della posizione in cui è allegato (ad es. ModelMetadata, SubGraphMetadata e TensorMetadata), il generatore di codice Android LiteRT potrebbe applicare automaticamente all'oggetto la pre/post-elaborazione corrispondente. Per maggiori dettagli, consulta la sezione Utilizzo di Codegen di ciascun tipo di file associato nello schema.
Parametri di normalizzazione e quantizzazione
La normalizzazione è una tecnica comune di pre-elaborazione dei dati nel machine learning. Lo scopo della normalizzazione è modificare i valori in una scala comune, senza distorcere le differenze negli intervalli di valori.
La quantizzazione del modello è una tecnica che consente rappresentazioni a precisione ridotta di pesi e, facoltativamente, attivazioni sia per l'archiviazione che per il calcolo.
In termini di preelaborazione e post-elaborazione, la normalizzazione e la quantizzazione sono due passaggi indipendenti. Di seguito sono riportati i dettagli:
| Normalizzazione | Quantizzazione | |
|---|---|---|
Un esempio dei valori dei parametri dell'immagine di input in MobileNet per i modelli float e quant, rispettivamente. |
Modello float: - media: 127,5 - deviazione standard: 127,5 Modello quant: - media: 127,5 - deviazione standard: 127,5 |
Modello float: - zeroPoint: 0 - scale: 1.0 Modello quantizzato: - zeroPoint: 128.0 - scale:0.0078125f |
Quando richiamarlo? |
Input: se i dati di input vengono normalizzati durante l'addestramento, i dati di input dell'inferenza devono essere normalizzati di conseguenza. Output: i dati di output non verranno normalizzati in generale. |
I modelli float non
richiedono la quantizzazione. Il modello quantizzato potrebbe o meno richiedere la quantizzazione nella pre/post elaborazione. Dipende dal tipo di dati dei tensori di input/output. - tensori float: non è necessaria la quantizzazione nel pre/post elaborazione. Le operazioni Quant e dequant sono integrate nel grafico del modello. - Tensori int8/uint8: richiedono la quantizzazione nel pre/post-elaborazione. |
Formula |
normalized_input = (input - mean) / std |
Quantizzazione per gli input:
q = f / scale + zeroPoint Dequantizzazione per gli output: f = (q - zeroPoint) * scale |
Dove si trovano i parametri |
Compilato dal creatore del modello
e archiviato nei metadati
del modello, come
NormalizationOptions |
Compilato automaticamente dal convertitore TFLite e memorizzato nel file del modello TFLite. |
| Come ottenere i parametri? | Tramite l'API
MetadataExtractor
[2]
|
Tramite l'API TFLite
Tensor [1] o
tramite l'API
MetadataExtractor [2] |
| I modelli float e quant condividono lo stesso valore? | Sì, i modelli float e quant hanno gli stessi parametri di normalizzazione | No, il modello float non richiede la quantizzazione. |
| Il generatore di codice TFLite o il binding ML di Android Studio lo genera automaticamente durante l'elaborazione dei dati? | Sì |
Sì |
[1] L'API LiteRT Java e l'API LiteRT C++.
[2] La libreria di estrazione dei metadati
Quando vengono elaborati dati delle immagini per i modelli uint8, a volte la normalizzazione e la quantizzazione vengono saltate. È possibile farlo quando i valori dei pixel sono compresi nell'intervallo [0, 255]. In generale, però, devi sempre elaborare i dati in base ai parametri di normalizzazione e quantizzazione, se applicabili.
Esempi
Puoi trovare esempi su come compilare i metadati per diversi tipi di modelli qui:
Classificazione di immagini
Scarica lo script qui , che compila i metadati in mobilenet_v1_0.75_160_quantized.tflite. Esegui lo script nel seguente modo:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Per compilare i metadati per altri modelli di classificazione delle immagini, aggiungi le specifiche del modello come queste nello script. Il resto di questa guida evidenzierà alcune delle sezioni chiave dell'esempio di classificazione delle immagini per illustrare gli elementi chiave.
Analisi approfondita dell'esempio di classificazione delle immagini
Informazioni sul modello
I metadati iniziano con la creazione di nuove informazioni sul modello:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informazioni su input / output
Questa sezione mostra come descrivere la firma di input e output del modello. Questi metadati possono essere utilizzati dai generatori di codice automatici per creare codice di pre- e post-elaborazione. Per creare informazioni di input o output su un tensore:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Input immagine
L'immagine è un tipo di input comune per il machine learning. I metadati LiteRT supportano informazioni come lo spazio colore e il pretrattamento, ad esempio la normalizzazione. La dimensione dell'immagine non richiede una specifica manuale in quanto è già fornita dalla forma del tensore di input e può essere dedotta automaticamente.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Output etichetta
L'etichetta può essere mappata a un tensore di output tramite un file associato utilizzando
TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Crea i Flatbuffers dei metadati
Il seguente codice combina le informazioni del modello con quelle di input e output:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Inserire i metadati e i file associati nel modello
Una volta creato il Flatbuffers dei metadati, i metadati e il file delle etichette vengono
scritti nel file TFLite tramite il metodo populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Puoi inserire nel modello tutti i file associati che vuoi tramite
load_associated_files. Tuttavia, è necessario comprimere almeno i file
documentati nei metadati. In questo esempio, la compressione del file dell'etichetta è
obbligatoria.
Visualizzare i metadati
Puoi utilizzare Netron per visualizzare i metadati oppure puoi leggere i metadati da un modello LiteRT in formato JSON utilizzando MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio supporta anche la visualizzazione dei metadati tramite la funzionalità di binding Android Studio ML.
Controllo delle versioni dei metadati
Lo schema dei metadati è sottoposto al controllo delle versioni sia in base al numero di controllo delle versioni semantico, che tiene traccia delle modifiche al file dello schema, sia in base all'identificazione del file Flatbuffers, che indica la compatibilità effettiva delle versioni.
Il numero di controllo delle versioni semantiche
Lo schema dei metadati è versionato in base al numero di controllo delle versioni semantico, ad esempio MAJOR.MINOR.PATCH. Monitora le modifiche allo schema in base alle regole
qui.
Visualizza la cronologia dei
campi
aggiunti dopo la versione 1.0.0.
Identificazione del file Flatbuffers
Il controllo delle versioni semantiche garantisce la compatibilità se vengono seguite le regole, ma non implica la vera incompatibilità. L'incremento del numero MAJOR non implica necessariamente l'interruzione della compatibilità con le versioni precedenti. Pertanto, utilizziamo l'identificazione del file Flatbuffers, file_identifier, per indicare la vera compatibilità dello schema dei metadati. L'identificatore del file è esattamente di 4 caratteri. È associato a un determinato schema di metadati e non può essere modificato dagli utenti. Se la compatibilità con le versioni precedenti dello schema dei metadati deve essere interrotta per qualche motivo, file_identifier aumenterà, ad esempio, da "M001" a "M002". È previsto che file_identifier venga modificato con frequenza molto inferiore rispetto a metadata_version.
La versione minima necessaria del parser dei metadati
La versione minima necessaria del parser dei metadati è la versione minima del parser dei metadati (il codice generato da Flatbuffers) che può leggere i Flatbuffers dei metadati per intero. La versione è effettivamente il
numero di versione più grande tra le versioni di tutti i campi compilati e la
versione compatibile più piccola indicata dall'identificatore del file. La versione minima
necessaria del parser dei metadati viene compilata automaticamente da
MetadataPopulator quando i metadati vengono inseriti in un modello TFLite. Per saperne di più su come viene utilizzata la versione minima necessaria dell'analizzatore dei metadati, consulta
l'estrattore di metadati.
Leggere i metadati dai modelli
La libreria Metadata Extractor è uno strumento pratico per leggere i metadati e i file associati da modelli su diverse piattaforme (vedi la versione Java e la versione C++). Puoi creare il tuo strumento di estrazione dei metadati in altre lingue utilizzando la libreria Flatbuffers.
Leggere i metadati in Java
Per utilizzare la libreria Metadata Extractor nella tua app per Android, ti consigliamo di utilizzare
l'AAR dei metadati LiteRT ospitato su
MavenCentral.
Contiene la classe MetadataExtractor, nonché i binding Java di FlatBuffers per lo schema dei metadati e lo schema del modello.
Puoi specificarlo nelle dipendenze di build.gradle nel seguente modo:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Per utilizzare gli snapshot notturni, assicurati di aver aggiunto il repository snapshot Sonatype.
Puoi inizializzare un oggetto MetadataExtractor con un ByteBuffer che punta
al modello:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer deve rimanere invariato per l'intera durata dell'oggetto
MetadataExtractor. L'inizializzazione potrebbe non riuscire se l'identificatore del file Flatbuffers dei metadati del modello non corrisponde a quello del parser dei metadati. Per saperne di più, consulta la gestione delle versioni dei metadati.
Grazie agli identificatori di file corrispondenti, l'estrattore di metadati leggerà correttamente i metadati generati da tutti gli schemi passati e futuri grazie al meccanismo di compatibilità avanti e indietro di Flatbuffers. Tuttavia, i campi degli schemi futuri non possono essere estratti dagli estrattori di metadati precedenti. La versione minima necessaria del parser dei metadati indica la versione minima del parser dei metadati che può leggere i Flatbuffers per intero. Puoi utilizzare il seguente metodo per verificare se la condizione relativa alla versione minima necessaria dell'analizzatore è soddisfatta:
public final boolean isMinimumParserVersionSatisfied();
È consentito passare un modello senza metadati. Tuttavia, l'invocazione di metodi che
leggono dai metadati causerà errori di runtime. Puoi verificare se un modello
ha metadati richiamando il metodo hasMetadata:
public boolean hasMetadata();
MetadataExtractor fornisce funzioni pratiche per ottenere i metadati dei tensori di input/output. Ad esempio,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Sebbene lo schema del modello LiteRTsupporti più sottografi, l'interprete TFLite al momento supporta solo un
singolo sottografo. Pertanto, MetadataExtractor omette l'indice del sottografo come argomento di input nei suoi metodi.
Leggere i file associati dai modelli
Il modello LiteRT con metadati e file associati è essenzialmente un file ZIP che può essere decompresso con strumenti ZIP comuni per ottenere i file associati. Ad esempio, puoi decomprimere mobilenet_v1_0.75_160_quantized ed estrarre il file delle etichette nel modello nel seguente modo:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Puoi anche leggere i file associati tramite la libreria Metadata Extractor.
In Java, passa il nome del file al metodo MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Analogamente, in C++, questa operazione può essere eseguita con il metodo
ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;