
LiteRT मेटाडेटा, मॉडल के बारे में जानकारी देने के लिए एक स्टैंडर्ड उपलब्ध कराता है. मेटाडेटा, इस बारे में जानकारी का एक अहम सोर्स है कि मॉडल क्या करता है और इसके इनपुट / आउटपुट की जानकारी क्या है. मेटाडेटा में ये दोनों शामिल होते हैं
- ऐसे हिस्से जिन्हें इंसान आसानी से पढ़ सकें. इनमें मॉडल का इस्तेमाल करते समय, सबसे सही तरीका बताया गया हो.
- मशीन के पढ़ने लायक हिस्से, जिनका इस्तेमाल कोड जनरेटर कर सकते हैं. जैसे, LiteRT Android कोड जनरेटर और Android Studio ML Binding की सुविधा.
Kaggle Models पर पब्लिश किए गए सभी इमेज मॉडल में मेटाडेटा मौजूद है.
मेटाडेटा फ़ॉर्मैट वाला मॉडल
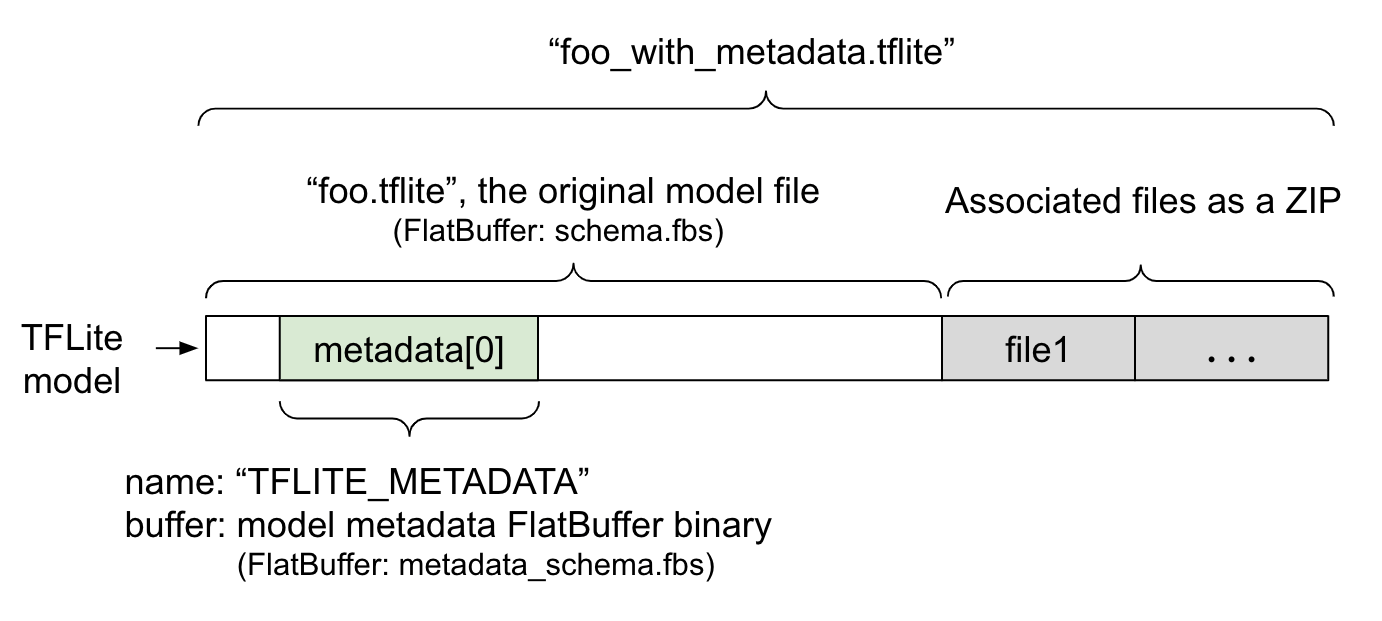
मॉडल मेटाडेटा को metadata_schema.fbs में तय किया जाता है. यह FlatBuffer फ़ाइल होती है. जैसा कि पहले फ़िगर में दिखाया गया है, इसे TFLite मॉडल स्कीमा के metadata फ़ील्ड में सेव किया जाता है. इसका नाम "TFLITE_METADATA" होता है. कुछ मॉडल के साथ उनसे जुड़ी फ़ाइलें भी मिल सकती हैं. जैसे, क्लासिफ़िकेशन लेबल वाली फ़ाइलें.
इन फ़ाइलों को, ओरिजनल मॉडल फ़ाइल के आखिर में ZIP के तौर पर जोड़ा जाता है. इसके लिए, ZipFile "append" mode ('a' mode) का इस्तेमाल किया जाता है. TFLite
Interpreter, नए फ़ाइल फ़ॉर्मैट का इस्तेमाल पहले की तरह ही कर सकता है. ज़्यादा जानकारी के लिए, मिलती-जुलती फ़ाइलों को पैक करना लेख पढ़ें.
मेटाडेटा को भरने, देखने, और पढ़ने के तरीके के बारे में जानने के लिए, यहां दिया गया निर्देश पढ़ें.
मेटाडेटा टूल सेट अप करना
अपने मॉडल में मेटाडेटा जोड़ने से पहले, आपको TensorFlow चलाने के लिए Python प्रोग्रामिंग एनवायरमेंट सेट अप करना होगा. इसे सेट अप करने के तरीके के बारे में ज़्यादा जानकारी यहां दी गई है.
Python प्रोग्रामिंग एनवायरमेंट सेट अप करने के बाद, आपको ये टूल इंस्टॉल करने होंगे:
pip install tflite-support
LiteRT मेटाडेटा टूलिंग, Python 3 के साथ काम करती है.
Flatbuffers Python API का इस्तेमाल करके मेटाडेटा जोड़ना
स्कीमा में मॉडल मेटाडेटा के तीन हिस्से होते हैं:
- मॉडल की जानकारी - मॉडल के बारे में पूरी जानकारी. साथ ही, लाइसेंस की शर्तों जैसी चीज़ों के बारे में जानकारी. ModelMetadata देखें. 2. इनपुट की जानकारी - इनपुट और प्री-प्रोसेसिंग के बारे में जानकारी. जैसे, सामान्य बनाना. SubGraphMetadata.input_tensor_metadata देखें. 3. आउटपुट की जानकारी - आउटपुट का ब्यौरा और पोस्ट-प्रोसेसिंग की ज़रूरत, जैसे कि लेबल से मैप करना. SubGraphMetadata.output_tensor_metadata देखें.
फ़िलहाल, LiteRT सिर्फ़ एक सबग्राफ़ के साथ काम करता है. इसलिए, मेटाडेटा दिखाते समय और कोड जनरेट करते समय, LiteRT कोड जनरेटर और Android Studio ML Binding की सुविधा, SubGraphMetadata.name और SubGraphMetadata.description के बजाय ModelMetadata.name और ModelMetadata.description का इस्तेमाल करेंगी.
इस्तेमाल किए जा सकने वाले इनपुट / आउटपुट टाइप
इनपुट और आउटपुट के लिए LiteRT मेटाडेटा, खास मॉडल टाइप को ध्यान में रखकर नहीं बनाया गया है. इसे इनपुट और आउटपुट टाइप को ध्यान में रखकर बनाया गया है. इससे कोई फ़र्क़ नहीं पड़ता कि मॉडल फ़ंक्शन के तौर पर क्या करता है. अगर इनपुट और आउटपुट टाइप में यहां दिए गए टाइप या इनका कॉम्बिनेशन शामिल है, तो TensorFlow Lite मेटाडेटा के साथ इसका इस्तेमाल किया जा सकता है:
- सुविधा - ऐसी संख्याएं जो बिना हस्ताक्षर वाले पूर्णांक या फ़्लोट32 हैं.
- इमेज - मेटाडेटा फ़िलहाल RGB और ग्रेस्केल इमेज के साथ काम करता है.
- बाउंडिंग बॉक्स - आयताकार बाउंडिंग बॉक्स. इस स्कीमा में, नंबरिंग के अलग-अलग तरीकों का इस्तेमाल किया जा सकता है.
संबंधित फ़ाइलों को पैक करना
LiteRT मॉडल के साथ अलग-अलग फ़ाइलें जुड़ी हो सकती हैं. उदाहरण के लिए, नैचुरल लैंग्वेज मॉडल में आम तौर पर ऐसी शब्दावली फ़ाइलें होती हैं जो शब्दों के हिस्सों को शब्द आईडी से मैप करती हैं. वहीं, क्लासिफ़िकेशन मॉडल में ऐसी लेबल फ़ाइलें हो सकती हैं जो ऑब्जेक्ट कैटगरी के बारे में बताती हैं. अगर कोई फ़ाइल जुड़ी हुई है, तो उसके बिना मॉडल ठीक से काम नहीं करेगा.
अब मेटाडेटा Python लाइब्रेरी की मदद से, मॉडल के साथ जुड़ी फ़ाइलों को बंडल किया जा सकता है. नया LiteRT मॉडल, एक ZIP फ़ाइल बन जाता है. इसमें मॉडल और उससे जुड़ी फ़ाइलें, दोनों शामिल होती हैं. इसे सामान्य ज़िप टूल की मदद से अनपैक किया जा सकता है. इस नए मॉडल फ़ॉर्मैट में भी फ़ाइल एक्सटेंशन .tflite का इस्तेमाल किया जाता है. यह मौजूदा TFLite फ़्रेमवर्क और इंटरप्रेटर के साथ काम करता है. ज़्यादा जानकारी के लिए, मेटाडेटा और उससे जुड़ी फ़ाइलों को मॉडल में पैक करना लेख पढ़ें.
मेटाडेटा में, फ़ाइल से जुड़ी जानकारी रिकॉर्ड की जा सकती है. फ़ाइल टाइप और फ़ाइल किस ऑब्जेक्ट से जुड़ी है (जैसे, ModelMetadata, SubGraphMetadata, और TensorMetadata) के आधार पर, LiteRT Android कोड जनरेटर ऑब्जेक्ट पर, प्री/पोस्ट प्रोसेसिंग अपने-आप लागू कर सकता है. ज़्यादा जानकारी के लिए, स्कीमा में हर सहयोगी फ़ाइल टाइप का <Codegen usage> सेक्शन देखें.
नॉर्मलाइज़ेशन और क्वांटाइज़ेशन पैरामीटर
मशीन लर्निंग में, डेटा को प्रोसेस करने की एक सामान्य तकनीक है नॉर्मलाइज़ेशन. सामान्य बनाने का मकसद, वैल्यू को एक सामान्य स्केल में बदलना है. इससे वैल्यू की रेंज में अंतर नहीं आता.
मॉडल क्वांटाइज़ेशन एक ऐसी तकनीक है जो वज़न के सटीक रिप्रज़ेंटेशन को कम करने की अनुमति देती है. साथ ही, यह स्टोरेज और कंप्यूटेशन, दोनों के लिए ऐक्टिवेशन को कम करने की अनुमति देती है.
प्रीप्रोसेसिंग और पोस्ट-प्रोसेसिंग के हिसाब से, सामान्यीकरण और परिमाणीकरण दो अलग-अलग चरण हैं. यहाँ जानकारी दी गई है.
| नॉर्मलाइज़ेशन | क्वांटाइज़ेशन | |
|---|---|---|
फ़्लोट और क्वांट मॉडल के लिए, MobileNet में इनपुट इमेज के पैरामीटर वैल्यू का उदाहरण. |
फ़्लोट मॉडल: - mean: 127.5 - std: 127.5 क्वांट मॉडल: - mean: 127.5 - std: 127.5 |
फ़्लोट मॉडल: - zeroPoint: 0 - scale: 1.0 क्वांट मॉडल: - zeroPoint: 128.0 - scale:0.0078125f |
इसे कब लागू किया जाता है? |
इनपुट: अगर ट्रेनिंग के दौरान इनपुट डेटा को सामान्य किया जाता है, तो अनुमान लगाने के लिए इस्तेमाल किए जाने वाले इनपुट डेटा को भी उसी के मुताबिक सामान्य किया जाना चाहिए. आउटपुट: आउटपुट डेटा को सामान्य तौर पर नॉर्मलाइज़ नहीं किया जाएगा. |
फ़्लोट मॉडल के लिए, क्वांटाइज़ेशन की ज़रूरत नहीं होती. क्वांटाइज़ किए गए मॉडल को प्री/पोस्ट प्रोसेसिंग में क्वांटाइज़ेशन की ज़रूरत हो सकती है या नहीं भी हो सकती. यह इनपुट/आउटपुट टेंसर के डेटाटाइप पर निर्भर करता है. - फ़्लोट टेंसर: प्री/पोस्ट प्रोसेसिंग में क्वानटाइज़ेशन की ज़रूरत नहीं है. Quant op और dequant op, मॉडल ग्राफ़ में शामिल होते हैं. - int8/uint8 टेंसर: प्री/पोस्ट प्रोसेसिंग में क्वांटाइज़ेशन की ज़रूरत होती है. |
फ़ॉर्मूला |
normalized_input = (input - mean) / std |
इनपुट के लिए क्वांटाइज़ करें:
q = f / scale + zeroPoint आउटपुट के लिए डीक्वांटाइज़ करें: f = (q - zeroPoint) * scale |
पैरामीटर कहां मौजूद होते हैं |
इसे मॉडल बनाने वाला व्यक्ति भरता है और यह मॉडल के मेटाडेटा में NormalizationOptions के तौर पर सेव होता है |
इन्हें TFLite कन्वर्टर अपने-आप भरता है. साथ ही, इन्हें tflite मॉडल फ़ाइल में सेव किया जाता है. |
| पैरामीटर कैसे पाएं? | MetadataExtractor API
[2] के ज़रिए
|
TFLite Tensor API [1] या MetadataExtractor API [2] के ज़रिए |
| क्या फ़्लोट और क्वांट मॉडल, एक ही वैल्यू शेयर करते हैं? | हां, फ़्लोट और क्वांट मॉडल में एक जैसे सामान्यीकरण पैरामीटर होते हैं | नहीं, फ़्लोट मॉडल के लिए क्वांटाइज़ेशन की ज़रूरत नहीं होती. |
| क्या TFLite Code Generator या Android Studio ML Binding, डेटा प्रोसेसिंग के दौरान इसे अपने-आप जनरेट करता है? | हां |
हां |
[1] LiteRT Java API और LiteRT C++ API.
[2] मेटाडेटा एक्सट्रैक्टर लाइब्रेरी
uint8 मॉडल के लिए इमेज डेटा प्रोसेस करते समय, कभी-कभी सामान्य बनाने और क्वांटाइज़ेशन की प्रोसेस को छोड़ दिया जाता है. अगर पिक्सल की वैल्यू [0, 255] की रेंज में है, तो ऐसा किया जा सकता है. हालांकि, आम तौर पर आपको डेटा को हमेशा सामान्य बनाने और क्वांटाइज़ेशन के पैरामीटर के हिसाब से प्रोसेस करना चाहिए.
उदाहरण
अलग-अलग तरह के मॉडल के लिए, मेटाडेटा कैसे भरा जाना चाहिए, इसके उदाहरण यहां दिए गए हैं:
इमेज क्लासिफ़िकेशन
स्क्रिप्ट को यहां से डाउनलोड करें. यह स्क्रिप्ट, mobilenet_v1_0.75_160_quantized.tflite में मेटाडेटा भरती है. स्क्रिप्ट को इस तरह चलाएं:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
इमेज क्लासिफ़िकेशन के अन्य मॉडल के लिए मेटाडेटा जोड़ने के लिए, स्क्रिप्ट में मॉडल स्पेसिफ़िकेशन जोड़ें. जैसे, यह. इस गाइड के बाकी हिस्से में, इमेज क्लासिफ़िकेशन के उदाहरण में मौजूद कुछ मुख्य सेक्शन को हाइलाइट किया जाएगा, ताकि मुख्य एलिमेंट के बारे में बताया जा सके.
इमेज क्लासिफ़िकेशन के उदाहरण के बारे में ज़्यादा जानें
मॉडल की जानकारी
मेटाडेटा, नई मॉडल जानकारी बनाकर शुरू होता है:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
इनपुट / आउटपुट की जानकारी
इस सेक्शन में, आपको अपने मॉडल के इनपुट और आउटपुट सिग्नेचर के बारे में बताने का तरीका दिखाया गया है. इस मेटाडेटा का इस्तेमाल, कोड जनरेट करने वाले टूल, प्री-प्रोसेसिंग और पोस्ट-प्रोसेसिंग कोड बनाने के लिए कर सकते हैं. किसी टेंसर के बारे में इनपुट या आउटपुट की जानकारी बनाने के लिए:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
इमेज इनपुट
मशीन लर्निंग के लिए, इमेज एक सामान्य इनपुट टाइप है. LiteRT मेटाडेटा, कलरस्पेस और प्री-प्रोसेसिंग की जानकारी के साथ-साथ सामान्यीकरण जैसी जानकारी भी सेव करता है. इमेज के डाइमेंशन को मैन्युअल तरीके से तय करने की ज़रूरत नहीं है, क्योंकि यह इनपुट टेंसर के शेप से पहले ही मिल जाता है. साथ ही, इसे अपने-आप भी अनुमानित किया जा सकता है.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
लेबल आउटपुट
TENSOR_AXIS_LABELS का इस्तेमाल करके, लेबल को किसी आउटपुट टेंसर से मैप किया जा सकता है. इसके लिए, उससे जुड़ी फ़ाइल का इस्तेमाल किया जाता है.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
मेटाडेटा Flatbuffers बनाएं
यहां दिए गए कोड में, मॉडल की जानकारी के साथ-साथ इनपुट और आउटपुट की जानकारी भी शामिल है:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
मॉडल में पैक मेटाडेटा और उससे जुड़ी फ़ाइलें
मेटाडेटा Flatbuffers बन जाने के बाद, मेटाडेटा और लेबल फ़ाइल को populate तरीके से TFLite फ़ाइल में लिखा जाता है:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
load_associated_files की मदद से, मॉडल में जितनी चाहें उतनी जुड़ी हुई फ़ाइलें पैक की जा सकती हैं. हालांकि, मेटाडेटा में बताई गई फ़ाइलों को पैक करना ज़रूरी है. इस उदाहरण में, लेबल फ़ाइल को पैक करना ज़रूरी है.
मेटाडेटा को विज़ुअलाइज़ करना
अपने मेटाडेटा को विज़ुअलाइज़ करने के लिए, Netron का इस्तेमाल किया जा सकता है. इसके अलावा, MetadataDisplayer का इस्तेमाल करके, LiteRT मॉडल से मेटाडेटा को json फ़ॉर्मैट में पढ़ा जा सकता है:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio में, Android Studio ML Binding feature की मदद से मेटाडेटा भी दिखाया जा सकता है.
मेटाडेटा वर्शनिंग
मेटाडेटा स्कीमा को दो तरह से वर्शन किया जाता है. पहला, सिमैंटिक वर्शनिंग नंबर के हिसाब से. यह स्कीमा फ़ाइल में हुए बदलावों को ट्रैक करता है. दूसरा, Flatbuffers फ़ाइल आइडेंटिफ़िकेशन के हिसाब से. यह वर्शन के साथ सही तरीके से काम करने की जानकारी देता है.
सिमेंटिक वर्शनिंग नंबर
मेटाडेटा स्कीमा को सिमेंटिक वर्शनिंग नंबर के हिसाब से वर्शन किया जाता है. जैसे, MAJOR.MINOR.PATCH. यह यहां दिए गए नियमों के मुताबिक, स्कीमा में हुए बदलावों को ट्रैक करता है.
वर्शन 1.0.0 के बाद जोड़े गए फ़ील्ड का इतिहास देखें.
Flatbuffers फ़ाइल की पहचान
सिमेंटिक वर्शनिंग के नियमों का पालन करने पर, यह गारंटी मिलती है कि वर्शन एक-दूसरे के साथ काम करेंगे. हालांकि, इसका मतलब यह नहीं है कि वर्शन एक-दूसरे के साथ काम नहीं करेंगे. मेजर नंबर को बढ़ाने का मतलब यह नहीं है कि पुराने सिस्टम के साथ काम करने की सुविधा पर कोई असर पड़ा है. इसलिए, हम Flatbuffers फ़ाइल की पहचान, file_identifier का इस्तेमाल करते हैं, ताकि मेटाडेटा स्कीमा की सही कंपैटिबिलिटी का पता चल सके. फ़ाइल आइडेंटिफ़ायर में ठीक चार वर्ण हैं. यह किसी मेटाडेटा स्कीमा के लिए तय होता है और उपयोगकर्ता इसमें बदलाव नहीं कर सकते. अगर किसी वजह से मेटाडेटा स्कीमा की बैकवर्ड कंपैटिबिलिटी को तोड़ना पड़ता है, तो file_identifier बढ़ जाएगा. उदाहरण के लिए, “M001” से “M002”. metadata_version की तुलना में, file_identifier में बहुत कम बार बदलाव किया जाता है.
मेटाडेटा पार्सर का ज़रूरी कम से कम वर्शन
मेटाडेटा पार्सर का ज़रूरी कम से कम वर्शन, मेटाडेटा पार्सर (Flatbuffers जनरेट किया गया कोड) का वह कम से कम वर्शन होता है जो मेटाडेटा Flatbuffers को पूरी तरह से पढ़ सकता है. वर्शन, असल में भरे गए सभी फ़ील्ड के वर्शन में सबसे बड़ा वर्शन नंबर होता है. साथ ही, यह फ़ाइल आइडेंटिफ़ायर से पता चलने वाला सबसे छोटा वर्शन होता है. मेटाडेटा पार्सर का ज़रूरी वर्शन, MetadataPopulator अपने-आप भर देता है. ऐसा तब होता है, जब मेटाडेटा को TFLite मॉडल में भरा जाता है. मेटाडेटा पार्सर के ज़रूरी वर्शन का इस्तेमाल कैसे किया जाता है, इस बारे में ज़्यादा जानने के लिए, मेटाडेटा एक्सट्रैक्टर देखें.
मॉडल से मेटाडेटा पढ़ना
मेटाडेटा एक्सट्रैक्टर लाइब्रेरी, अलग-अलग प्लैटफ़ॉर्म पर मौजूद मॉडल से मेटाडेटा और उससे जुड़ी फ़ाइलों को पढ़ने का एक आसान टूल है. इसके बारे में ज़्यादा जानने के लिए, Java वर्शन और C++ वर्शन देखें. Flatbuffers लाइब्रेरी का इस्तेमाल करके, अन्य भाषाओं में अपना मेटाडेटा एक्सट्रैक्टर टूल बनाया जा सकता है.
Java में मेटाडेटा पढ़ना
अपने Android ऐप्लिकेशन में Metadata Extractor लाइब्रेरी का इस्तेमाल करने के लिए, हमारा सुझाव है कि आप MavenCentral पर होस्ट किए गए LiteRT Metadata AAR का इस्तेमाल करें.
इसमें MetadataExtractor क्लास के साथ-साथ, मेटाडेटा स्कीमा और मॉडल स्कीमा के लिए FlatBuffers Java बाइंडिंग भी शामिल हैं.
build.gradle की डिपेंडेंसी में इसे इस तरह बताया जा सकता है:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
हर रात के स्नैपशॉट का इस्तेमाल करने के लिए, पक्का करें कि आपने Sonatype snapshot repository जोड़ा हो.
MetadataExtractor ऑब्जेक्ट को ByteBuffer से शुरू किया जा सकता है. यह मॉडल की ओर इशारा करता है:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer ऑब्जेक्ट के पूरे लाइफ़टाइम के लिए, ByteBuffer में कोई बदलाव नहीं होना चाहिए.MetadataExtractor अगर मॉडल के मेटाडेटा का Flatbuffers फ़ाइल आइडेंटिफ़ायर, मेटाडेटा पार्सर के आइडेंटिफ़ायर से मेल नहीं खाता है, तो हो सकता है कि मॉडल शुरू न हो पाए. ज़्यादा जानकारी के लिए, मेटाडेटा वर्शनिंग देखें.
फ़ाइल आइडेंटिफ़ायर मैच होने पर, मेटाडेटा एक्सट्रैक्टर, पिछले और आने वाले समय के सभी स्कीमा से जनरेट किए गए मेटाडेटा को पढ़ पाएगा. ऐसा Flatbuffers के फ़ॉरवर्ड और बैकवर्ड कंपैटिबिलिटी मैकेनिज़्म की वजह से होगा. हालांकि, आने वाले समय के स्कीमा के फ़ील्ड को, पुराने मेटाडेटा एक्सट्रैक्टर से नहीं निकाला जा सकता. मेटाडेटा के पार्सर का ज़रूरी वर्शन, मेटाडेटा पार्सर का वह सबसे कम वर्शन होता है जो पूरे मेटाडेटा Flatbuffers को पढ़ सकता है. यह पुष्टि करने के लिए कि पार्सर के ज़रूरी वर्शन की शर्त पूरी हुई है या नहीं, यहां दिया गया तरीका अपनाएं:
public final boolean isMinimumParserVersionSatisfied();
मेटाडेटा के बिना मॉडल पास करने की अनुमति है. हालांकि, मेटाडेटा से डेटा पढ़ने वाली विधियों को लागू करने पर, रनटाइम गड़बड़ियां होंगी. hasMetadata तरीके का इस्तेमाल करके, यह देखा जा सकता है कि किसी मॉडल में मेटाडेटा है या नहीं:
public boolean hasMetadata();
MetadataExtractor आपको इनपुट/आउटपुट टेंसर के मेटाडेटा को पाने के लिए आसान फ़ंक्शन उपलब्ध कराता है. उदाहरण के लिए,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
LiteRT मॉडल स्कीमा में एक से ज़्यादा सबग्राफ़ इस्तेमाल किए जा सकते हैं. हालांकि, फ़िलहाल TFLite इंटरप्रेटर सिर्फ़ एक सबग्राफ़ के साथ काम करता है. इसलिए, MetadataExtractor अपने तरीकों में सबग्राफ़ इंडेक्स को इनपुट आर्ग्युमेंट के तौर पर शामिल नहीं करता है.
मॉडल से जुड़ी फ़ाइलें पढ़ने की अनुमति
मेटाडेटा और उससे जुड़ी फ़ाइलों वाला LiteRT मॉडल, असल में एक zip फ़ाइल होती है. इससे जुड़ी फ़ाइलों को पाने के लिए, इसे सामान्य zip टूल से अनपैक किया जा सकता है. उदाहरण के लिए, mobilenet_v1_0.75_160_quantized को अनज़िप किया जा सकता है. साथ ही, मॉडल में लेबल फ़ाइल को इस तरह से निकाला जा सकता है:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
मेटाडेटा एक्सट्रैक्टर लाइब्रेरी की मदद से, इससे जुड़ी फ़ाइलें भी पढ़ी जा सकती हैं.
Java में, फ़ाइल का नाम MetadataExtractor.getAssociatedFile
मेथड में पास करें:
public InputStream getAssociatedFile(String fileName);
इसी तरह, C++ में इसे ModelMetadataExtractor::GetAssociatedFile तरीके से किया जा सकता है:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;