
Os dispositivos de borda geralmente têm memória ou poder computacional limitados. Várias otimizações podem ser aplicadas aos modelos para que eles sejam executados dentro dessas restrições. Além disso, algumas otimizações permitem o uso de hardware especializado para inferência acelerada.
O LiteRT e o kit de ferramentas de otimização de modelos do TensorFlow oferecem ferramentas para minimizar a complexidade da otimização de inferências.
Recomendamos que você considere a otimização do modelo durante o processo de desenvolvimento do aplicativo. Este documento descreve algumas práticas recomendadas para otimizar modelos do TensorFlow para implantação em hardware de borda.
Por que os modelos precisam ser otimizados
A otimização de modelos pode ajudar no desenvolvimento de aplicativos de várias maneiras principais.
Redução de tamanho
Algumas formas de otimização podem ser usadas para reduzir o tamanho de um modelo. Modelos menores têm os seguintes benefícios:
- Tamanho de armazenamento menor:modelos menores ocupam menos espaço de armazenamento nos dispositivos dos usuários. Por exemplo, um app Android que usa um modelo menor ocupa menos espaço de armazenamento no dispositivo móvel de um usuário.
- Tamanho de download menor:modelos menores exigem menos tempo e largura de banda para fazer o download nos dispositivos dos usuários.
- Menos uso de memória:modelos menores usam menos RAM quando são executados, o que libera memória para outras partes do aplicativo e pode resultar em melhor desempenho e estabilidade.
A quantização pode reduzir o tamanho de um modelo em todos esses casos, possivelmente à custa de alguma acurácia. A poda e o clustering podem reduzir o tamanho de um modelo para download, tornando-o mais fácil de compactar.
Redução de latência
Latência é o tempo necessário para executar uma única inferência com um determinado modelo. Algumas formas de otimização podem reduzir a quantidade de computação necessária para executar a inferência usando um modelo, resultando em menor latência. A latência também pode afetar o consumo de energia.
No momento, a quantização pode ser usada para reduzir a latência simplificando os cálculos que ocorrem durante a inferência, possivelmente às custas de alguma precisão.
Compatibilidade do acelerador
Alguns aceleradores de hardware, como a Edge TPU, podem executar inferências muito rapidamente com modelos otimizados corretamente.
Em geral, esses tipos de dispositivos exigem que os modelos sejam quantizados de uma maneira específica. Consulte a documentação de cada acelerador de hardware para saber mais sobre os requisitos.
Contrapartidas
As otimizações podem resultar em mudanças na acurácia do modelo, que precisam ser consideradas durante o processo de desenvolvimento do aplicativo.
As mudanças na acurácia dependem do modelo individual que está sendo otimizado e são difíceis de prever com antecedência. Em geral, os modelos otimizados para tamanho ou latência perdem um pouco de acurácia. Dependendo do seu aplicativo, isso pode ou não afetar a experiência dos usuários. Em casos raros, alguns modelos podem ganhar precisão como resultado do processo de otimização.
Tipos de otimização
No momento, o LiteRT oferece suporte à otimização por quantização, poda e clustering.
Essas ferramentas fazem parte do TensorFlow Model Optimization Toolkit (link em inglês), que oferece recursos para técnicas de otimização de modelos compatíveis com o TensorFlow Lite.
Quantização
A quantização reduz a precisão dos números usados para representar os parâmetros de um modelo, que, por padrão, são números de ponto flutuante de 32 bits. Isso resulta em um tamanho de modelo menor e uma computação mais rápida.
Os seguintes tipos de quantização estão disponíveis no LiteRT:
| Técnica | Requisitos de dados | Redução de tamanho | Precisão | Hardware compatível |
|---|---|---|---|---|
| Quantização float16 pós-treinamento | Não há dados | Até 50% | Perda insignificante de precisão | CPU, GPU |
| Quantização de intervalo dinâmico pós-treinamento | Não há dados | Até 75% | Menor perda de acurácia | CPU, GPU (Android) |
| Quantização de números inteiros pós-treinamento | Amostra representativa sem rótulo | Até 75% | Pequena perda de precisão | CPU, GPU (Android), EdgeTPU |
| Treinamento com reconhecimento de quantização | Dados de treinamento rotulados | Até 75% | Menor perda de acurácia | CPU, GPU (Android), EdgeTPU |
A árvore de decisão a seguir ajuda você a selecionar os esquemas de quantização que talvez queira usar no modelo, com base apenas no tamanho e na acurácia esperados.
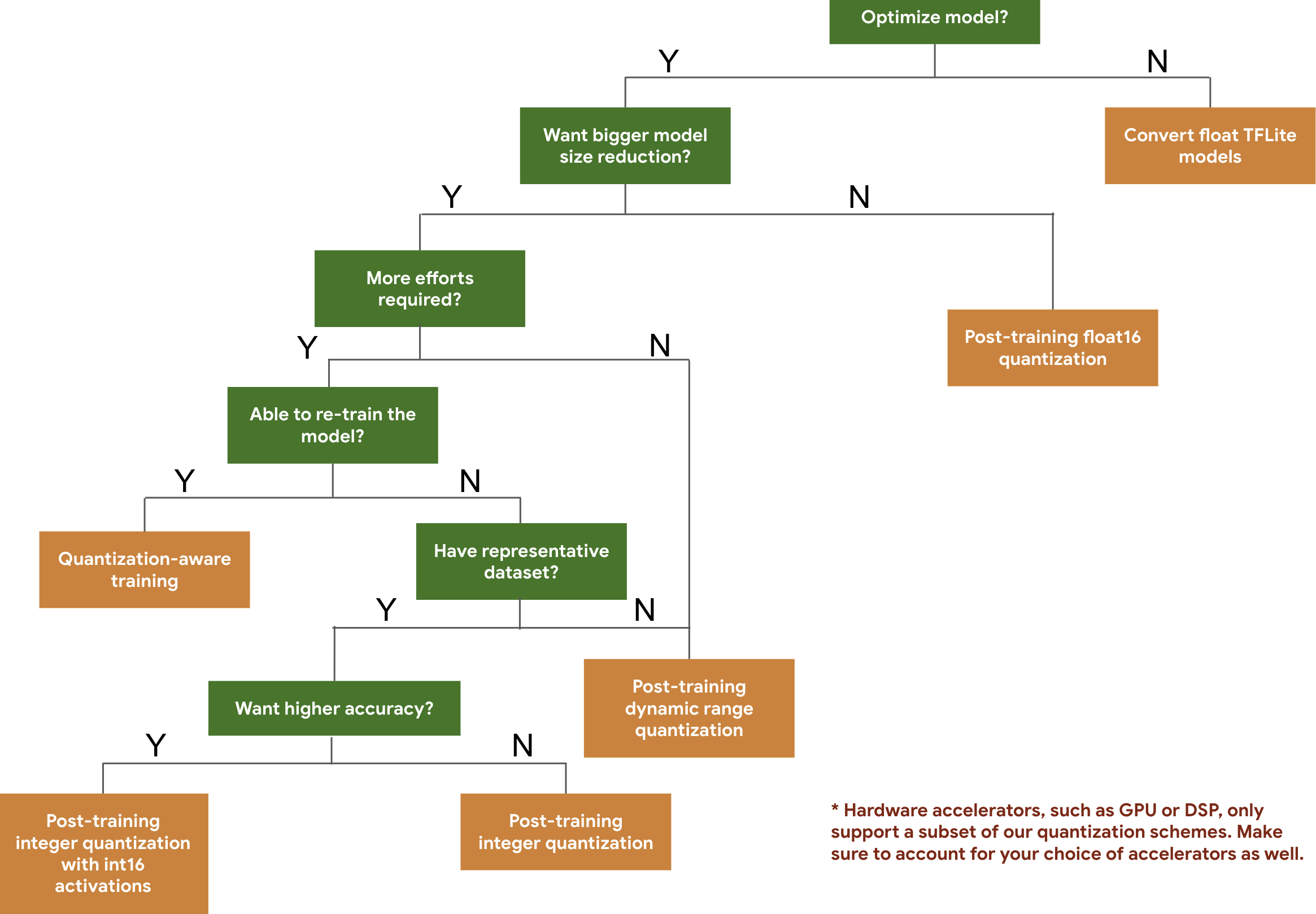
Confira abaixo os resultados de latência e precisão para quantização pós-treinamento e treinamento com reconhecimento de quantização em alguns modelos. Todos os números de latência são medidos em dispositivos Pixel 2 usando uma única CPU de núcleo grande. À medida que o kit de ferramentas melhora, os números aqui também melhoram:
| Modelo | Acurácia de primeiro nível (original) | Acurácia de primeiro nível (quantizada pós-treinamento) | Acurácia de primeiro nível (treinamento com Quantization Aware) | Latência (original) (ms) | Latência (quantização pós-treinamento) (ms) | Latência (treinamento com Quantization Aware) (ms) | Tamanho (original) (MB) | Tamanho (otimizado) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0,768 | N/A | 3973 | 2868 | N/A | 178,3 | 44,9 |
Quantização de números inteiros completa com ativações int16 e pesos int8
A quantização com ativações int16 é um esquema de quantização de números inteiros com ativações em int16 e pesos em int8. Esse modo pode melhorar a acurácia do modelo quantizado em comparação com o esquema de quantização de números inteiros completo com ativações e pesos em int8, mantendo um tamanho de modelo semelhante. É recomendada quando as ativações são sensíveis à quantização.
OBSERVAÇÃO:no momento, apenas implementações de kernel de referência não otimizadas estão disponíveis no TFLite para esse esquema de quantização. Portanto, por padrão, o desempenho será lento em comparação com os kernels int8. No momento, é possível acessar todas as vantagens desse modo usando hardware especializado ou software personalizado.
Confira abaixo os resultados de acurácia de alguns modelos que se beneficiam desse modo.
| Modelo | Tipo de métrica de acurácia | Acurácia (ativações float32) | Precisão (ativações int8) | Precisão (ativações int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7% | 7,7% | 7,2% |
| DeepSpeech 0.5.1 (sem enrolamento) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0.5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | Acurácia de primeiro nível | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | Acurácia de primeiro nível | 0,718 | 0,7126 | 0,7137 |
| MobileBert | F1(correspondência exata) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Poda
A poda funciona removendo parâmetros de um modelo que têm apenas um impacto pequeno nas previsões. Os modelos reduzidos têm o mesmo tamanho no disco e a mesma latência de tempo de execução, mas podem ser compactados com mais eficiência. Isso torna a poda uma técnica útil para reduzir o tamanho do download do modelo.
No futuro, o LiteRT vai reduzir a latência dos modelos reduzidos.
Clustering
O clustering agrupa os pesos de cada camada em um modelo em um número predefinido de clusters e compartilha os valores centroides dos pesos pertencentes a cada cluster individual. Isso reduz o número de valores de peso únicos em um modelo, diminuindo a complexidade dele.
Como resultado, os modelos clusterizados podem ser compactados com mais eficiência, oferecendo benefícios de implantação semelhantes à poda.
Fluxo de trabalho de desenvolvimento
Para começar, verifique se os modelos em modelos hospedados podem funcionar para seu aplicativo. Caso contrário, recomendamos que os usuários comecem com a ferramenta de quantização pós-treinamento, já que ela é amplamente aplicável e não exige dados de treinamento.
Para casos em que as metas de acurácia e latência não são atendidas ou em que o suporte a aceleradores de hardware é importante, o treinamento com reconhecimento de quantização é a melhor opção. Confira outras técnicas de otimização no Kit de ferramentas de otimização de modelos do TensorFlow.
Se quiser reduzir ainda mais o tamanho do modelo, tente a poda e/ou o clustering antes de quantizar os modelos.