
에지 기기는 메모리나 컴퓨팅 성능이 제한적인 경우가 많습니다. 이러한 제약 조건 내에서 실행할 수 있도록 모델에 다양한 최적화를 적용할 수 있습니다. 또한 일부 최적화를 통해 추론을 가속화하기 위해 특수 하드웨어를 사용할 수 있습니다.
LiteRT와 TensorFlow 모델 최적화 도구는 추론 최적화의 복잡성을 최소화하는 도구를 제공합니다.
애플리케이션 개발 프로세스 중에 모델 최적화를 고려하는 것이 좋습니다. 이 문서에서는 에지 하드웨어에 배포하기 위해 TensorFlow 모델을 최적화하기 위한 몇 가지 권장사항을 설명합니다.
모델을 최적화해야 하는 이유
모델 최적화는 애플리케이션 개발에 여러 가지 주요 방식으로 도움이 될 수 있습니다.
크기 축소
일부 최적화는 모델의 크기를 줄이는 데 사용할 수 있습니다. 소형 모델에는 다음과 같은 이점이 있습니다.
- 더 작은 스토리지 크기: 더 작은 모델은 사용자의 기기에서 더 적은 저장공간을 차지합니다. 예를 들어 더 작은 모델을 사용하는 Android 앱은 사용자의 모바일 기기에서 더 적은 저장공간을 차지합니다.
- 다운로드 크기 감소: 모델이 작을수록 사용자의 기기에 다운로드하는 데 필요한 시간과 대역폭이 줄어듭니다.
- 메모리 사용량 감소: 작은 모델은 실행될 때 RAM을 적게 사용하므로 애플리케이션의 다른 부분에서 사용할 수 있는 메모리가 확보되어 성능과 안정성이 향상될 수 있습니다.
양자화는 이러한 모든 경우에 모델 크기를 줄일 수 있으며, 정확도가 약간 떨어질 수 있습니다. 가지치기 및 클러스터링을 사용하면 모델을 더 쉽게 압축할 수 있으므로 다운로드할 모델의 크기를 줄일 수 있습니다.
지연 시간 감소
지연 시간은 지정된 모델로 단일 추론을 실행하는 데 걸리는 시간입니다. 일부 최적화는 모델을 사용하여 추론을 실행하는 데 필요한 계산량을 줄여 지연 시간을 단축할 수 있습니다. 지연 시간은 전력 소비에도 영향을 미칠 수 있습니다.
현재 양자화는 추론 중에 발생하는 계산을 단순화하여 지연 시간을 줄이는 데 사용할 수 있으며, 이 경우 정확도가 다소 떨어질 수 있습니다.
가속기 호환성
Edge TPU와 같은 일부 하드웨어 가속기는 올바르게 최적화된 모델로 추론을 매우 빠르게 실행할 수 있습니다.
일반적으로 이러한 유형의 기기에서는 모델이 특정 방식으로 양자화되어야 합니다. 요구사항에 관해 자세히 알아보려면 각 하드웨어 가속기의 문서를 참고하세요.
절충사항
최적화로 인해 모델 정확도가 변경될 수 있으며, 이는 애플리케이션 개발 프로세스 중에 고려해야 합니다.
정확도 변화는 최적화되는 개별 모델에 따라 달라지며 사전에 예측하기 어렵습니다. 일반적으로 크기나 지연 시간에 최적화된 모델은 정확도가 약간 떨어집니다. 애플리케이션에 따라 사용자 환경에 영향을 미칠 수도 있고 미치지 않을 수도 있습니다. 드물지만 최적화 프로세스의 결과로 특정 모델의 정확도가 향상될 수 있습니다.
최적화 유형
LiteRT는 현재 양자화, 프루닝, 클러스터링을 통한 최적화를 지원합니다.
이러한 기능은 TensorFlow Lite와 호환되는 모델 최적화 기법을 위한 리소스를 제공하는 TensorFlow 모델 최적화 도구의 일부입니다.
양자화
양자화는 모델의 매개변수를 나타내는 데 사용되는 숫자의 정밀도를 줄이는 방식으로 작동합니다. 기본적으로 이러한 숫자는 32비트 부동 소수점 숫자입니다. 따라서 모델 크기가 줄어들고 계산 속도가 빨라집니다.
LiteRT에서는 다음과 같은 양자화 유형을 사용할 수 있습니다.
| 기법 | 데이터 요구사항 | 크기 축소 | 정확성 | 지원되는 하드웨어 |
|---|---|---|---|---|
| 학습 후 float16 양자화 | 데이터 없음 | 최대 50% | 정확도 손실이 미미함 | CPU, GPU |
| 학습 후 동적 범위 양자화 | 데이터 없음 | 최대 75% | 정확도 손실이 가장 적음 | CPU, GPU (Android) |
| 학습 후 정수 양자화 | 라벨이 지정되지 않은 대표 샘플 | 최대 75% | 정확도 손실이 적음 | CPU, GPU (Android), EdgeTPU |
| 양자화 인식 학습 | 라벨이 지정된 학습 데이터 | 최대 75% | 정확도 손실이 가장 적음 | CPU, GPU (Android), EdgeTPU |
다음 결정 트리는 예상 모델 크기와 정확도에 따라 모델에 사용할 양자화 스키마를 선택하는 데 도움이 됩니다.
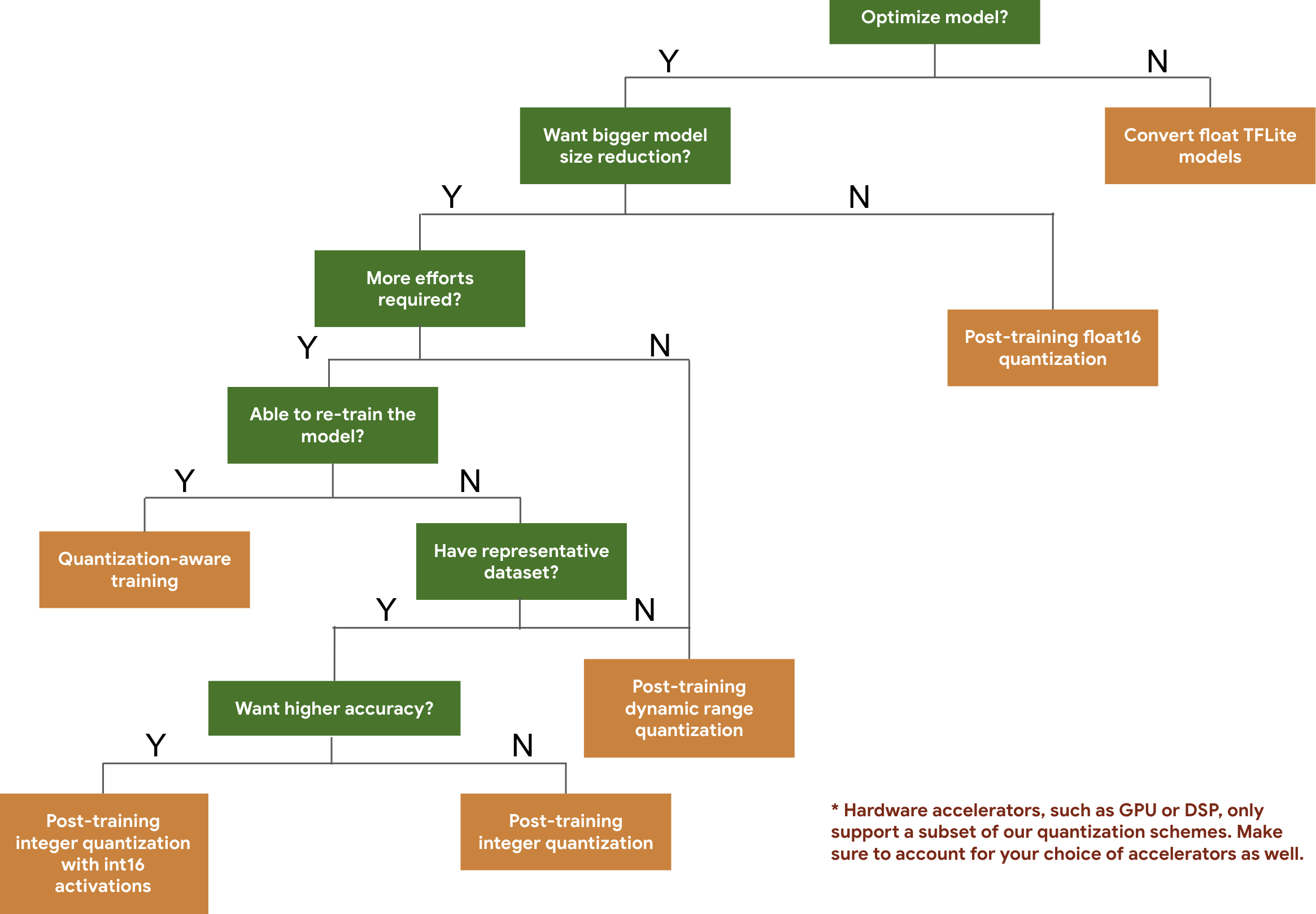
아래는 몇 가지 모델에서 학습 후 양자화와 양자화 인식 학습의 지연 시간 및 정확도 결과입니다. 모든 지연 시간은 단일 대형 코어 CPU를 사용하는 Pixel 2 기기에서 측정됩니다. 툴킷이 개선되면 여기의 숫자도 개선됩니다.
| 모델 | 최상위 정확성 (원래) | 최상위 정확도 (학습 후 양자화) | 최상위 정확도 (양자화 인식 학습) | 지연 시간 (원래) (밀리초) | 지연 시간 (학습 후 양자화) (밀리초) | 지연 시간 (양자화 인식 학습) (밀리초) | 크기 (원본) (MB) | 크기 (최적화됨) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | 해당 사항 없음 | 3973 | 2868 | 해당 사항 없음 | 178.3 | 44.9 |
int16 활성화 및 int8 가중치를 사용한 전체 정수 양자화
int16 활성화를 사용한 양자화는 활성화가 int16이고 가중치가 int8인 전체 정수 양자화 방식입니다. 이 모드는 활성화와 가중치가 모두 int8인 전체 정수 양자화 방식과 비교하여 유사한 모델 크기를 유지하면서 양자화된 모델의 정확도를 향상할 수 있습니다. 활성화가 양자화에 민감한 경우에 권장됩니다.
참고: 현재 이 양자화 스킴의 경우 최적화되지 않은 참조 커널 구현만 TFLite에서 사용할 수 있으므로 기본적으로 성능이 int8 커널에 비해 느립니다. 이 모드의 모든 이점은 현재 전문 하드웨어나 맞춤 소프트웨어를 통해 액세스할 수 있습니다.
아래는 이 모드의 이점을 누리는 일부 모델의 정확도 결과입니다.
| 모델 | 정확도 측정항목 유형 | 정확도 (float32 활성화) | 정확도 (int8 활성화) | 정확도 (int16 활성화) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | 최상위 정확성 | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | 최상위 정확성 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(일치검색) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
가지치기
가지치기는 모델의 예측에 미치는 영향이 미미한 매개변수를 삭제하는 방식으로 작동합니다. 가지치기된 모델은 디스크에서 크기가 동일하고 런타임 지연 시간이 동일하지만 더 효과적으로 압축할 수 있습니다. 따라서 가지치기는 모델 다운로드 크기를 줄이는 데 유용한 기술입니다.
향후 LiteRT는 가지치기된 모델의 지연 시간을 줄여줄 것입니다.
클러스터링
클러스터링은 모델의 각 레이어의 가중치를 미리 정의된 클러스터 수로 그룹화한 다음 각 개별 클러스터에 속하는 가중치의 중심 값을 공유하는 방식으로 작동합니다. 이렇게 하면 모델의 고유한 가중치 값 수가 줄어들어 복잡성이 줄어듭니다.
따라서 클러스터링된 모델을 더 효과적으로 압축할 수 있어 가지치기와 유사한 배포 이점을 제공합니다.
개발 워크플로
시작점으로 호스팅된 모델의 모델이 애플리케이션에 적합한지 확인하세요. 그렇지 않은 경우 학습 후 양자화 도구는 광범위하게 적용할 수 있고 학습 데이터가 필요하지 않으므로 사용자가 이 도구로 시작하는 것이 좋습니다.
정확도 및 지연 시간 타겟이 충족되지 않거나 하드웨어 가속기 지원이 중요한 경우 양자화 인식 학습이 더 나은 옵션입니다. TensorFlow 모델 최적화 도구에서 추가 최적화 기법을 확인하세요.