
Operatory systemów uczących się (ML), których używasz w modelu, mogą wpływać na proces konwertowania modelu TensorFlow na format TensorFlow Lite. Konwerter TensorFlow Lite obsługuje ograniczoną liczbę operacji TensorFlow używanych w popularnych modelach wnioskowania, co oznacza, że nie każdy model można bezpośrednio przekonwertować. Konwerter umożliwia uwzględnienie dodatkowych operatorów, ale konwersja modelu w ten sposób wymaga też zmodyfikowania środowiska wykonawczego TensorFlow Lite, którego używasz do wykonywania modelu, co może ograniczyć Twoje możliwości korzystania ze standardowych opcji wdrażania, takich jak Usługi Google Play.
Konwerter TensorFlow Lite Converter analizuje strukturę modelu i stosuje optymalizacje w celu zapewnienia jego zgodności z bezpośrednio obsługiwanymi operatorami. Na przykład w zależności od operatorów ML w Twoim modelu konwerter może pominąć lub scalać te operatory, aby zmapować je na ich odpowiedniki w TensorFlow Lite.
Ze względu na wydajność nawet w przypadku obsługiwanych operacji czasami można oczekiwać określonych wzorców wykorzystania. Aby zrozumieć, jak stworzyć model TensorFlow, który można wykorzystać z TensorFlow Lite, najlepiej zastanowić się nad tym, w jaki sposób operacje są konwertowane i zoptymalizowane, oraz jakie są ograniczenia narzucane przez ten proces.
Obsługiwane operatory
Wbudowane operatory TensorFlow Lite są podzbiorem operatorów, które wchodzą w skład podstawowej biblioteki TensorFlow. Twój model TensorFlow może też zawierać niestandardowe operatory w postaci operatorów złożonych lub nowych, zdefiniowanych przez Ciebie. Na diagramie poniżej widać relacje między tymi operatorami.
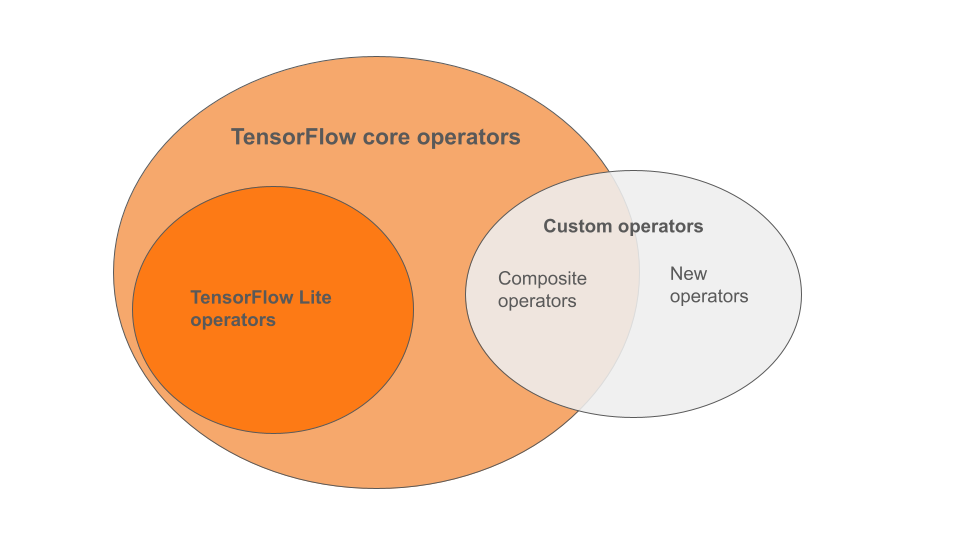
Z tego zakresu operatorów modeli ML dostępne są 3 typy modeli obsługiwanych przez proces konwersji:
- Modele z wbudowanym operatorem TensorFlow Lite. (Zalecane)
- Modele z wbudowanymi operatorami i wybranymi operatorami podstawowymi TensorFlow.
- Modele z wbudowanymi operatorami, głównymi operatorami TensorFlow lub niestandardowymi operatorami.
Jeśli Twój model zawiera tylko operacje, które są natywnie obsługiwane przez TensorFlow Lite, nie potrzebujesz dodatkowych flag, aby go przekonwertować. Jest to zalecana ścieżka, ponieważ ten typ modelu przebiega płynnie i jest łatwiejszy do optymalizacji oraz uruchamiania za pomocą domyślnego środowiska wykonawczego TensorFlow Lite. Dostępne są też inne opcje wdrażania modelu, np. Usługi Google Play. Zacznij od zapoznania się z przewodnikiem po konwerterze TensorFlow Lite. Listę wbudowanych operatorów znajdziesz na stronie operacji TensorFlow Lite.
Jeśli chcesz uwzględnić wybrane operacje TensorFlow z podstawowej biblioteki, musisz to określić w momencie konwersji i upewnić się, że środowisko wykonawcze uwzględnia te operacje. Szczegółowe instrukcje znajdziesz w temacie Wybieranie operatorów TensorFlow.
W miarę możliwości unikaj ostatniej opcji dodawania operatorów niestandardowych do przekonwertowanego modelu. Operatory niestandardowe to operatory tworzone przez połączenie wielu podstawowych operatorów TensorFlow lub zdefiniowanie zupełnie nowego. Po przekonwertowaniu operatorów niestandardowych mogą one zwiększać rozmiar całego modelu, powodując zależności spoza wbudowanej biblioteki TensorFlow Lite. Operacje niestandardowe, jeśli nie zostały utworzone specjalnie na potrzeby wdrażania urządzeń mobilnych lub urządzeń, mogą pogorszyć wydajność po wdrożeniu na urządzeniach z ograniczonymi zasobami w porównaniu do środowiska serwera. Podobnie jak w przypadku wybranych podstawowych operatorów TensorFlow, operatory niestandardowe wymagają zmodyfikowania środowiska wykonawczego modelu, co ograniczy możliwość korzystania ze standardowych usług wykonawczych, takich jak Usługi Google Play.
Typy obsługiwane
Większość operacji TensorFlow Lite jest kierowana zarówno na wnioskowanie w postaci zmiennoprzecinkowej (float32), jak i kwantyzowanych (uint8, int8), ale wiele operacji nie używa jeszcze innych typów, takich jak tf.float16 czy ciągi znaków.
Oprócz zastosowania różnych wersji operacji Inną różnicą między modelami zmiennoprzecinkowymi a kwantyzowanymi jest sposób ich konwertowania. Konwersja kwantyzowana wymaga informacji o zakresie dynamicznym dla tensorów. Wymaga to „fałszywej kwantyfikacji” podczas trenowania modelu, uzyskiwania informacji o zakresie za pomocą zbioru danych kalibracyjnych lub szacowania zakresu na bieżąco. Więcej informacji znajdziesz w sekcji dotyczącej kwantyzacji.
Proste konwersje, stałe składanie i łączenie
W TensorFlow Lite można przetwarzać wiele operacji TensorFlow, mimo że nie mają one bezpośredniego odpowiednika. Dotyczy to operacji, które można po prostu usunąć z wykresu (tf.identity), zastąpić tensorami (tf.placeholder) lub przekształcić w bardziej złożone operacje (tf.nn.bias_add). Nawet niektóre obsługiwane operacje mogą być czasem usuwane w ramach jednego z tych procesów.
Oto niepełna lista operacji TensorFlow, które są zwykle usuwane z wykresu:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operacje eksperymentalne
Obecne operacje TensorFlow Lite są obecne, ale nie są jeszcze gotowe dla modeli niestandardowych:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF