
Makine öğrenimi (ML) modellerinizi çalıştırmak için grafik işlem birimlerini (GPU'lar) kullanma modelinizin performansını ve kullanıcı deneyimini önemli ölçüde iyileştirebilir bazılarını anlatabilirsiniz. iOS cihazlarda, Modellerinizi yetki verin. Yetki verilmiş temsilciler, Modelinizin kodunu GPU işlemcilerinde çalıştırmanıza olanak tanıyan LiteRT.
Bu sayfada, iOS uygulamaları. LiteRT için GPU yetkilendirmesini kullanma hakkında daha fazla bilgi için ve gelişmiş teknikler hakkında bilgi edinmek için GPU delegeler sayfası.
Yorumlayıcı API ile GPU'yu kullanma
LiteRT Çevirmeni API, bir dizi genel özel API'ler kullanır. Aşağıdakiler talimatları, iOS uygulamasına GPU desteğini ekleme konusunda size yol gösterir. Bu kılavuz ML modelini başarıyla yürütebilen bir iOS uygulamanız olduğunu varsayar yardımcı olur.
Podfile'ı GPU desteğini içerecek şekilde değiştirme
LiteRT 2.3.0 sürümünden itibaren GPU yetkilendirmesi hariçtir
ayırmak için de kullanabilirsiniz. Bunları bir
TensorFlowLiteSwift kapsülünün alt spesifikasyonları:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
VEYA
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
TensorFlowLiteObjC veya TensorFlowLiteC aracını da kullanabilirsiniz:
2.4.0 ve sonraki sürümlerde kullanılabilen Objective-C veya C API'si.
İlk kullanıma hazırlama ve GPU yetkisini kullanma
GPU yetkisini LiteRT Çevirmen ile kullanabilirsiniz bir dizi programlamaya sahip API dil. Swift ve Objective-C önerilir, ancak C++ ve daha fazla Daha önceki bir LiteRT sürümünü kullanıyorsanız C kullanmanız gerekir %2,4'ten daha fazlasıdır. Aşağıdaki kod örneklerinde, temsilcinin her kullanıma sunuyoruz.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (2.4.0'dan önce)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
GPU API dili kullanım notları
- 2.4.0'dan önceki LiteRT sürümleri yalnızca C API'yi Hedef-C.
- C++ API yalnızca bazel veya TensorFlow kullanıyorsanız kullanılabilir Kendiniz hafifletin. C++ API, CocoaPods ile kullanılamaz.
- LiteRT'i C++ ile GPU delegesi ile kullanırken GPU'yu alın
TFLGpuDelegateCreate()işlevi aracılığıyla delege etmek ve ardındanInterpreter::ModifyGraphWithDelegate(), sesli arama yapmak yerineInterpreter::AllocateTensors().
Sürüm moduyla derleme ve test etme
Aşağıdaki işlemleri yapmak için uygun Metal API hızlandırıcı ayarlarını kullanarak sürüm derlemesine geçin. daha iyi performans elde edebilir ve nihai test yapabilirsiniz. Bu bölümde, bir sürüm derlemesini etkinleştirin ve Metal hızlandırma ayarını yapılandırın.
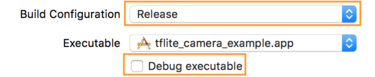
Sürüm derlemesine geçmek için:
- Ürün > Şema > Şemayı Düzenle... ve Çalıştır'ı seçin.
- Bilgi sekmesinde, Derleme Yapılandırması'nı Sürüm olarak değiştirin ve
Yürütülebilir hataları ayıkla seçeneğinin işaretini kaldırın.
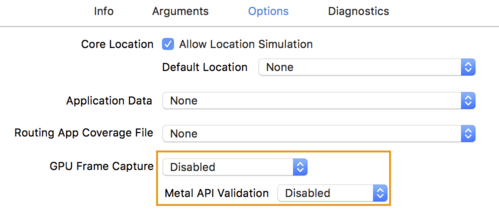
- Options (Seçenekler) sekmesini tıklayın ve GPU Frame Capture'ı (GPU Çerçeve Yakalama) Disabled (Devre Dışı) olarak değiştirin.
ve Metal API Doğrulaması'nı Devre Dışı olarak değiştirin.
- 64 bit mimari üzerinde salt kullanıma yönelik derlemeler seçtiğinizden emin olun. Şunun altında:
Proje gezgini > tflite_camera_example > PROJE > projenizin_adı >
Derleme Ayarları bölümünde Yalnızca Etkin Mimari Derle > Bırak
Evet.

Gelişmiş GPU desteği
Bu bölümde, aşağıdakiler de dahil olmak üzere iOS için GPU yetkilendirmesinin gelişmiş kullanımları ele alınmaktadır: yetki verme seçenekleri, giriş ve çıkış tamponları ile nicelenmiş modellerin kullanımını öğreneceksiniz.
iOS İçin Yetki Seçenekleri
GPU temsilcisinin oluşturucusu, Swift'teki seçeneklerin struct kadarını kabul eder
API,
Objective-C
API,
ve C
API.
nullptr (C API) veya hiçbir şey (Objective-C ve Swift API) iletmemelidir.
başlatıcı, varsayılan seçenekleri (Temel Kullanım bölümünde açıklandığı üzere) ayarlar
yukarıdaki örneğe bakın).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
C++ API kullanan Giriş/Çıkış arabellekleri
GPU'da hesaplama işlemi için verilerin GPU'da kullanılabilmesi gerekir. Bu genellikle bir bellek kopyası oluşturmanız gerektiği anlamına gelir. Bu tür durumlarda verileriniz mümkünse CPU/GPU bellek sınırını aşıyor çünkü bu, çok zaman harcıyor. Bu tür bir geçiş genellikle kaçınılmazdır ancak bazı durumlarda durumlardan biri atlanabilir.
Ağ girişi, GPU belleğinde önceden yüklü bir görüntüyse ( kamera feed'ini içeren bir GPU dokusu) GPU belleğinde kalabilir. bile yer almıyor. Benzer bir şekilde, ağın çıkışı resim stili gibi oluşturabilirsiniz. aktarma sonucu doğrudan ekranda görüntüleyebilirsiniz.
LiteRT, en iyi performansı elde etmek için kullanıcıların doğrudan TensorFlow donanım arabelleğinden okuma ve yazma ve atlama bu işlemden kaçınmalısınız.
Resim girişinin GPU belleğinde olduğunu varsayarsak önce bunu bir
Metal için MTLBuffer nesnesi. Bir TfLiteTensor öğesini,
kullanıcı tarafından TFLGpuDelegateBindMetalBufferToTensor() ile MTLBuffer hazırlandı
işlevini kullanın. Bu işlevin
Interpreter::ModifyGraphWithDelegate(). Ayrıca, çıkarım çıktısı da şu şekildedir:
varsayılan olarak GPU belleğinden CPU belleğine kopyalanır. Bu davranışı devre dışı bırakabilirsiniz
şu tarihte Interpreter::SetAllowBufferHandleOutput(true) numaralı telefonu arayarak
başlatma.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Varsayılan davranış devre dışı bırakıldıktan sonra çıkarım çıkışı GPU'dan kopyalanıyor
için açık bir çağrı yapılması gerekir
Her çıkış tensörü için Interpreter::EnsureTensorDataIsReadable(). Bu
yaklaşım nicel modeller için de işe yarar ancak her durumda
float32 boyutlu arabellek, çünkü arabellek
dahili nicelikten çıkarılmış tampon.
Nicel modeller
iOS GPU yetki verme kitaplıkları, varsayılan olarak nicelenmiş modelleri destekler. Şunları yapmayın: GPU yetkilendirmesi ile nicelenmiş modeller kullanmak için kod değişikliği yapılması gerekir. İlgili içeriği oluşturmak için kullanılan Bu bölümde, test veya destek için nicel desteğin nasıl devre dışı bırakılacağı açıklanmaktadır. .
Miktarı ölçülmüş model desteğini devre dışı bırak
Aşağıdaki kodda, miktarlandırılmış modeller için desteğin nasıl devre dışı bırakılacağı gösterilmektedir.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
GPU hızlandırmalı olarak nicelenmiş modelleri çalıştırma hakkında daha fazla bilgi için bkz. GPU temsilcisine genel bakış.