
Les outils de benchmark LiteRT mesurent et calculent des statistiques pour les métriques de performances importantes suivantes :
- Délai d'initialisation
- Temps d'inférence de l'état de préchauffage
- Temps d'inférence de l'état stable
- Utilisation de la mémoire pendant l'initialisation
- Utilisation globale de la mémoire
Les outils de benchmark sont disponibles sous forme d'applications de benchmark pour Android et iOS, ainsi que sous forme de binaires de ligne de commande prédéfinis. Ils partagent tous la même logique de mesure des performances de base. Notez que les options et les formats de sortie disponibles sont légèrement différents en raison des différences dans l'environnement d'exécution.
Application de benchmark Android
Une application de benchmark Android basée sur l'API Interpreter v1 est également fournie. Il s'agit d'une meilleure mesure des performances du modèle dans une application Android. Les chiffres de l'outil de benchmark différeront toujours légèrement de ceux obtenus lors de l'exécution de l'inférence avec le modèle dans l'application réelle.
Cette application de benchmark Android n'a pas d'UI. Installez-le et exécutez-le à l'aide de la commande adb, puis récupérez les résultats à l'aide de la commande adb logcat.
Télécharger ou créer l'application
Téléchargez les applications de benchmark Android précompilées de la version Nightly à l'aide des liens suivants :
Pour les applications de benchmark Android compatibles avec les opérations TF via le délégué Flex, utilisez les liens ci-dessous :
Vous pouvez également compiler l'application à partir de la source en suivant ces instructions.
Préparer le benchmark
Avant d'exécuter l'application de benchmark, installez-la et transférez le fichier de modèle sur l'appareil comme suit :
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Exécuter un benchmark
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph est un paramètre obligatoire.
graph:string
Chemin d'accès au fichier du modèle TFLite.
Vous pouvez spécifier d'autres paramètres facultatifs pour exécuter le benchmark.
num_threads:int(par défaut : 1)
Nombre de threads à utiliser pour exécuter l'interpréteur TFLite.use_gpu:bool(valeur par défaut : false)
Utiliser le délégué GPU.use_xnnpack:bool(par défaut=false)
Utilisez le délégué XNNPACK.
Selon l'appareil que vous utilisez, certaines de ces options peuvent ne pas être disponibles ou n'avoir aucun effet. Pour en savoir plus sur les paramètres de performances que vous pouvez exécuter avec l'application de benchmark, consultez Paramètres.
Affichez les résultats à l'aide de la commande logcat :
adb logcat | grep "Inference timings"
Les résultats du benchmark sont présentés comme suit :
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Application de benchmark iOS
Pour exécuter des benchmarks sur un appareil iOS, vous devez compiler l'application à partir de la source.
Placez le fichier du modèle LiteRT dans le répertoire benchmark_data de l'arborescence source et modifiez le fichier benchmark_params.json. Ces fichiers sont inclus dans l'application, qui lit les données du répertoire. Pour obtenir des instructions détaillées, consultez l'application de benchmark iOS.
Benchmarks de performances pour les modèles connus
Cette section liste les benchmarks de performances de LiteRT lors de l'exécution de modèles connus sur certains appareils Android et iOS.
Benchmarks de performances Android
Ces chiffres de référence des performances ont été générés avec le binaire de référence natif.
Pour les benchmarks Android, l'affinité du processeur est définie pour utiliser les grands cœurs de l'appareil afin de réduire la variance (voir les détails).
Nous partons du principe que les modèles ont été téléchargés et décompressés dans le répertoire /data/local/tmp/tflite_models. Le binaire de référence est créé à l'aide de ces instructions et est supposé se trouver dans le répertoire /data/local/tmp.
Pour exécuter l'analyse comparative :
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Pour exécuter avec le délégué GPU, définissez --use_gpu=true.
Les valeurs de performances ci-dessous sont mesurées sur Android 10.
| Nom du modèle | Appareil | CPU, 4 threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5,0 ms | --- | |
| NASNet Mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
Benchmarks de performances iOS
Ces chiffres de référence des performances ont été générés avec l'application de benchmark iOS.
Pour exécuter des benchmarks iOS, l'application de benchmark a été modifiée pour inclure le modèle approprié, et benchmark_params.json a été modifié pour définir num_threads sur 2. Pour utiliser le délégué GPU, les options "use_gpu" : "1" et "gpu_wait_type" : "aggressive" ont également été ajoutées à benchmark_params.json.
| Nom du modèle | Appareil | CPU, 2 threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet Mobile | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
Tracer les éléments internes de LiteRT
Tracer les composants internes de LiteRT dans Android
Les événements internes de l'interpréteur LiteRT d'une application Android peuvent être capturés par les outils de traçage Android. Il s'agit des mêmes événements que ceux de l'API Trace d'Android. Les événements capturés à partir du code Java/Kotlin sont donc visibles en même temps que les événements internes LiteRT.
Voici quelques exemples d'événements :
- Appel de l'opérateur
- Modification du graphique par un délégué
- Allocation de tenseurs
Parmi les différentes options de capture de traces, ce guide couvre le profileur de processeur Android Studio et l'application Traçage système. Pour d'autres options, consultez l'outil de ligne de commande Perfetto ou l'outil de ligne de commande Systrace.
Ajouter des événements de trace dans le code Java
Il s'agit d'un extrait de code de l'application exemple Image Classification (Classification d'images). L'interpréteur LiteRT s'exécute dans la section recognizeImage/runInference. Cette étape est facultative, mais elle est utile pour identifier l'endroit où l'appel d'inférence est effectué.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Activer le traçage LiteRT
Pour activer le traçage LiteRT, définissez la propriété système Android debug.tflite.trace sur 1 avant de démarrer l'application Android.
adb shell setprop debug.tflite.trace 1
Si cette propriété a été définie lors de l'initialisation de l'interpréteur LiteRT, les événements clés (par exemple, l'appel d'opérateur) de l'interpréteur seront suivis.
Une fois toutes les traces capturées, désactivez le traçage en définissant la valeur de la propriété sur 0.
adb shell setprop debug.tflite.trace 0
Profileur de processeur Android Studio
Capturez des traces avec le profileur de processeur Android Studio en procédant comme suit :
Sélectionnez Exécuter > Profiler "app" dans les menus du haut.
Lorsque la fenêtre du Profileur s'affiche, cliquez n'importe où dans la chronologie du processeur.
Sélectionnez "Tracer les appels système" parmi les modes de profilage du processeur.
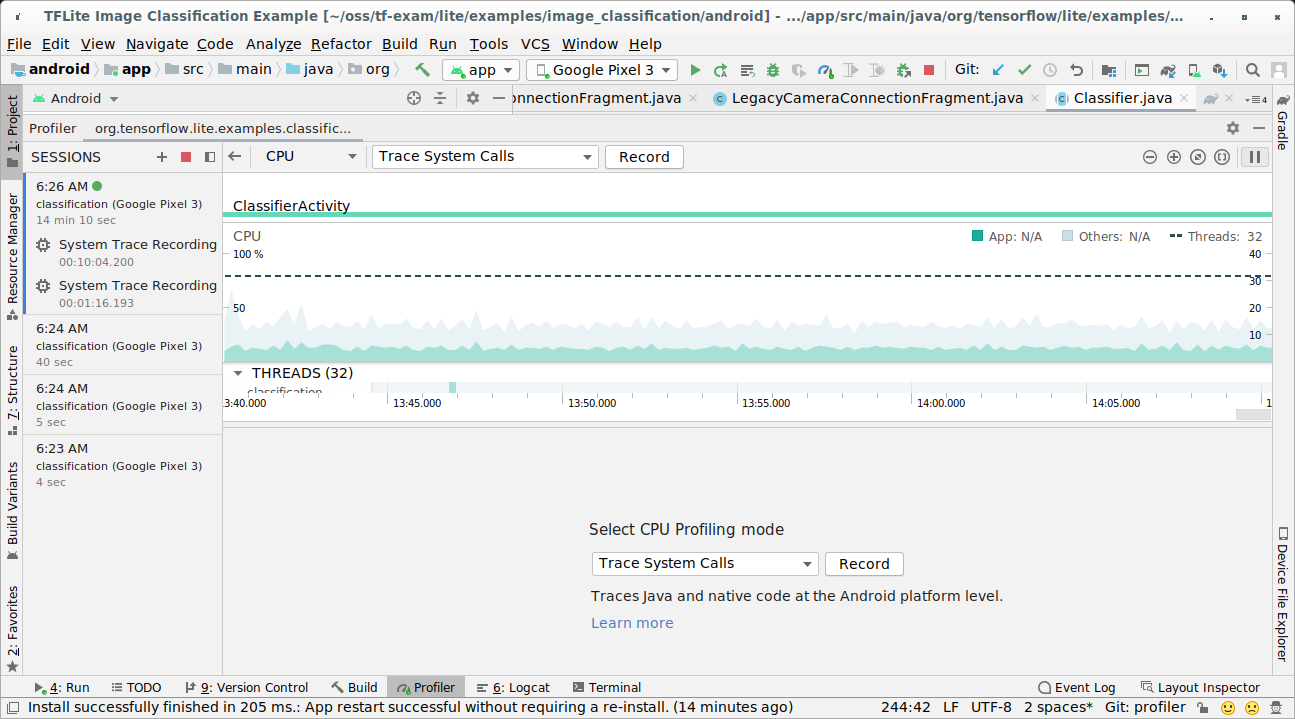
Appuyez sur le bouton "Enregistrer".
Appuyez sur le bouton "Arrêter".
Examinez le résultat de la trace.
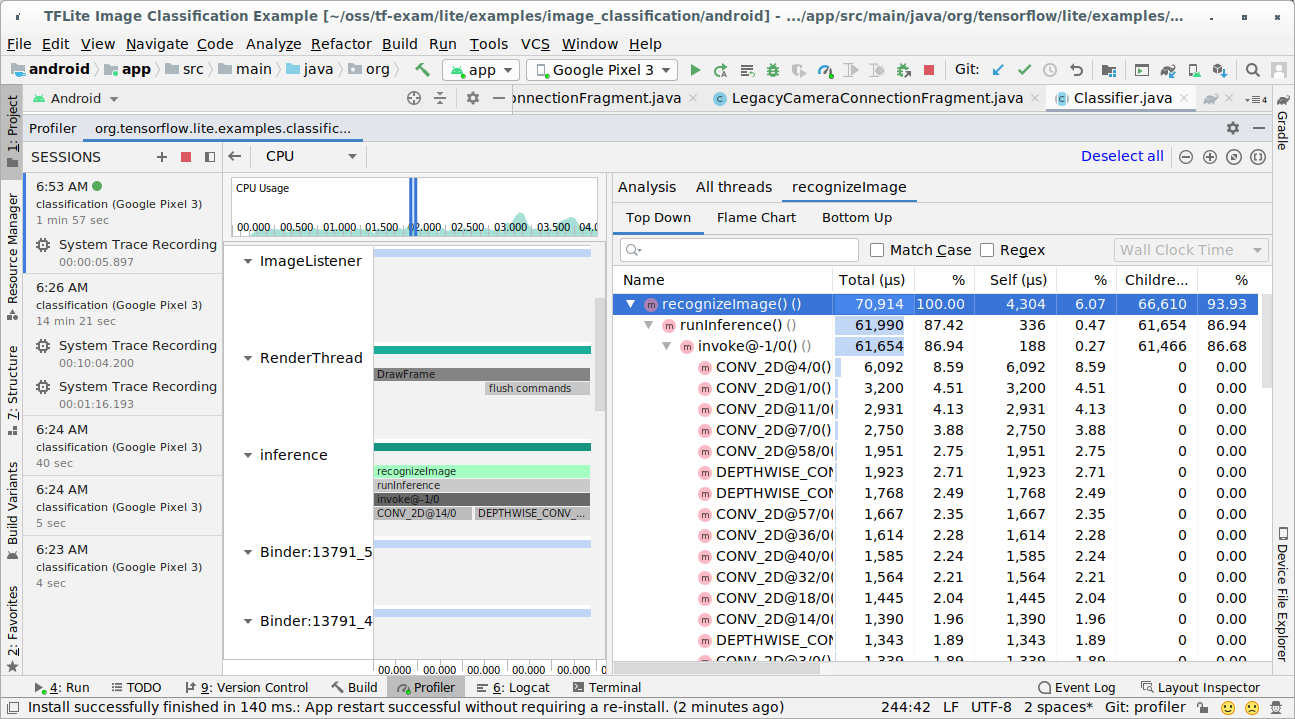
Dans cet exemple, vous pouvez voir la hiérarchie des événements dans un thread et les statistiques pour chaque durée d'opérateur. Vous pouvez également voir le flux de données de l'ensemble de l'application entre les threads.
Application Traçage système
Capturez des traces sans Android Studio en suivant les étapes décrites dans l'application Trace système.
Dans cet exemple, les mêmes événements TFLite ont été capturés et enregistrés au format Perfetto ou Systrace, selon la version de l'appareil Android. Les fichiers de trace capturés peuvent être ouverts dans l'interface utilisateur de Perfetto.
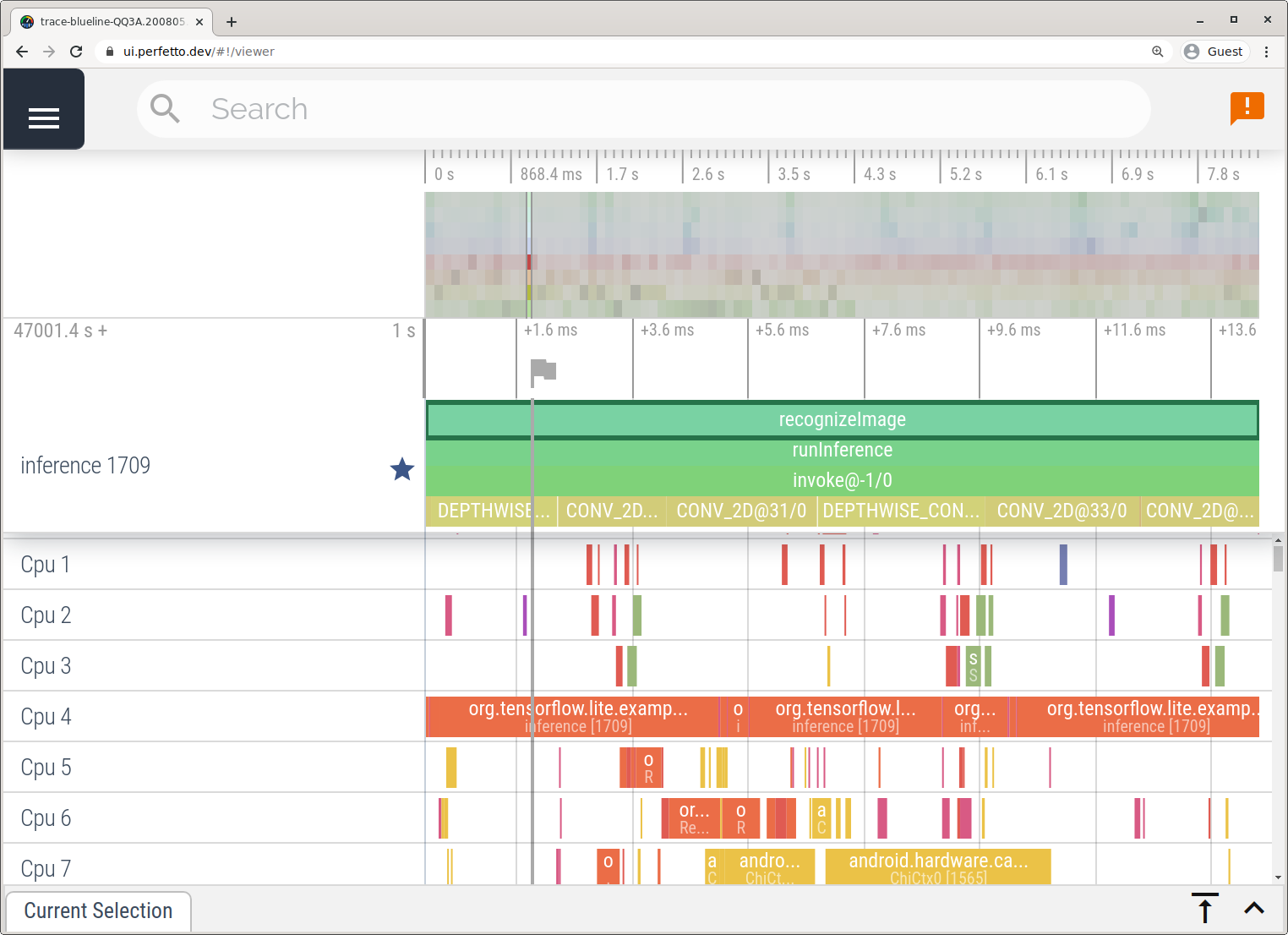
Tracer les composants internes de LiteRT dans iOS
Les événements internes de l'interpréteur LiteRT d'une application iOS peuvent être capturés par l'outil Instruments inclus dans Xcode. Il s'agit d'événements signpost iOS. Les événements capturés à partir du code Swift/Objective-C sont donc visibles en même temps que les événements internes LiteRT.
Voici quelques exemples d'événements :
- Appel de l'opérateur
- Modification du graphique par un délégué
- Allocation de tenseurs
Activer le traçage LiteRT
Définissez la variable d'environnement debug.tflite.trace en suivant les étapes ci-dessous :
Sélectionnez Product > Scheme > Edit Scheme… (Produit > Schéma > Modifier le schéma…) dans les menus supérieurs de Xcode.
Cliquez sur "Profil" dans le volet de gauche.
Décochez la case "Utiliser les arguments et les variables d'environnement de l'action d'exécution".
Ajoutez
debug.tflite.tracedans la section "Variables d'environnement".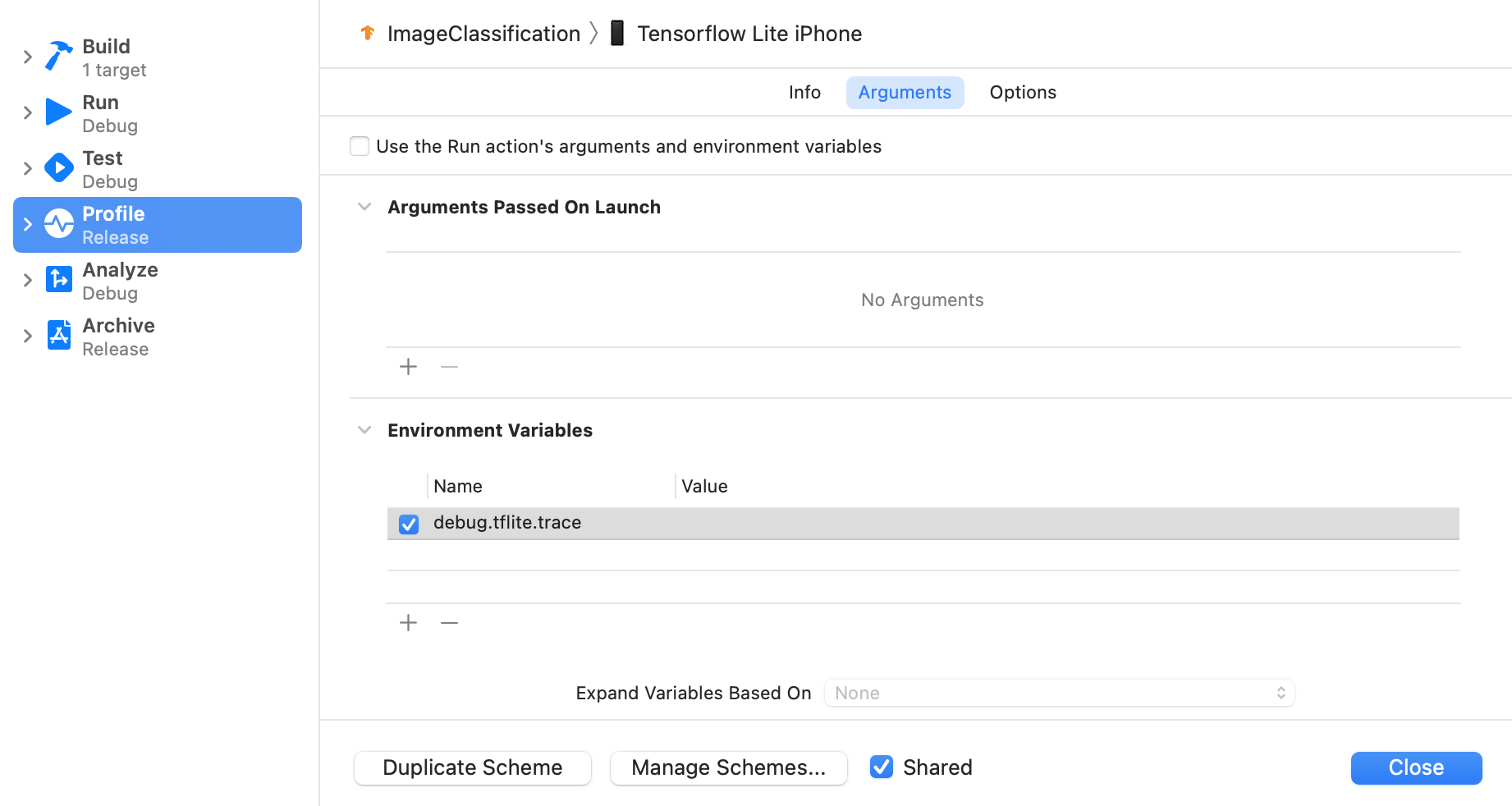
Si vous souhaitez exclure les événements LiteRT lors du profilage de l'application iOS, désactivez le traçage en supprimant la variable d'environnement.
Instruments Xcode
Pour capturer des traces, procédez comme suit :
Sélectionnez Product > Profile (Produit > Profil) dans les menus supérieurs d'Xcode.
Cliquez sur Logging (Journalisation) parmi les modèles de profilage lorsque l'outil Instruments se lance.
Appuyez sur le bouton "Start" (Démarrer).
Appuyez sur le bouton "Arrêter".
Cliquez sur "os_signpost" pour développer les éléments du sous-système de journalisation OS.
Cliquez sur le sous-système de journalisation OS "org.tensorflow.lite".
Examinez le résultat de la trace.
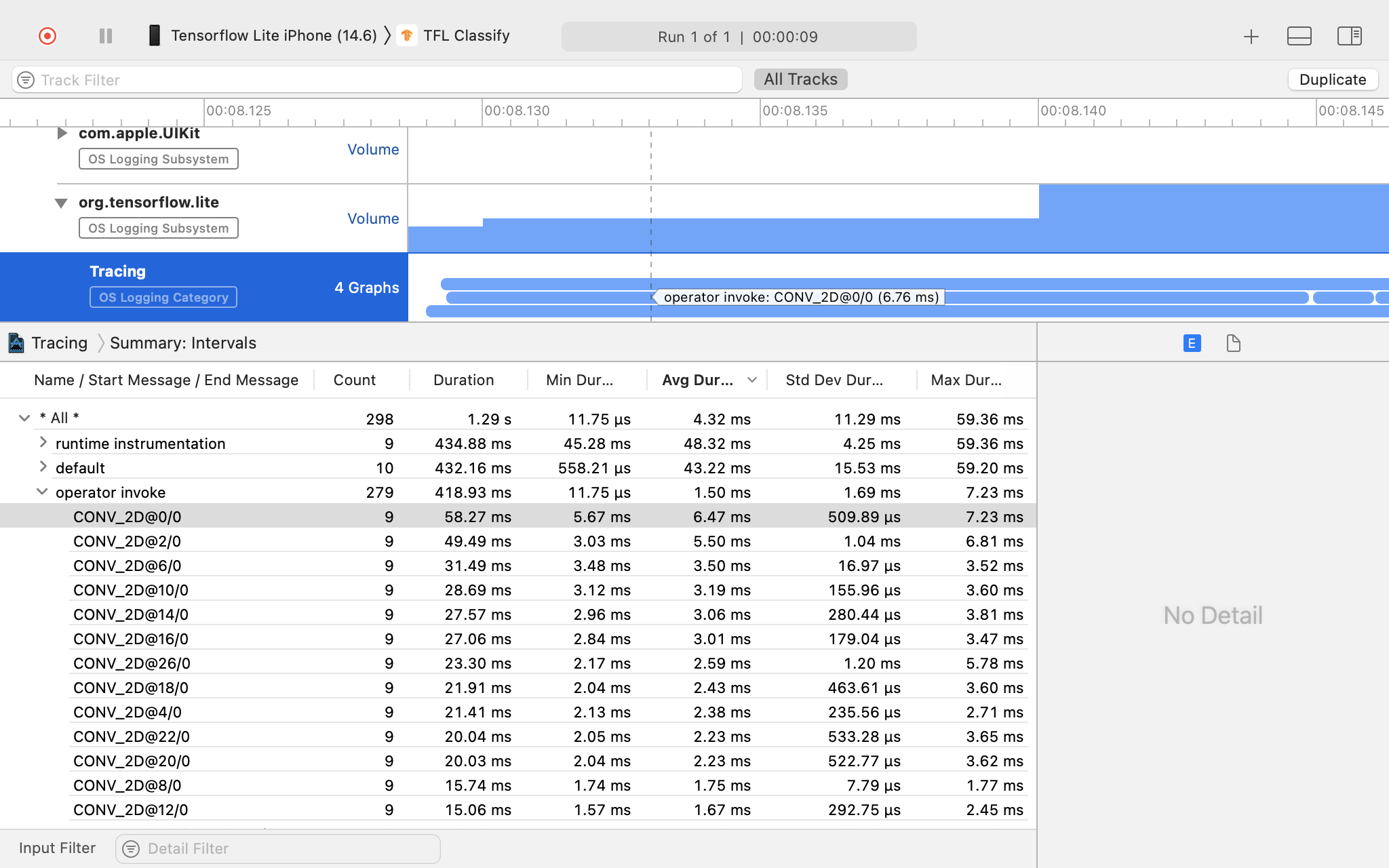
Dans cet exemple, vous pouvez voir la hiérarchie des événements et les statistiques pour chaque période d'opérateur.
Utiliser les données de traçage
Les données de traçage vous permettent d'identifier les goulots d'étranglement des performances.
Voici quelques exemples d'insights que vous pouvez obtenir à partir du profileur et de solutions potentielles pour améliorer les performances :
- Si le nombre de cœurs de processeur disponibles est inférieur au nombre de threads d'inférence, les frais généraux de planification du processeur peuvent entraîner des performances médiocres. Vous pouvez reprogrammer d'autres tâches gourmandes en ressources processeur dans votre application pour éviter qu'elles ne se chevauchent avec l'inférence de votre modèle ou ajuster le nombre de threads de l'interpréteur.
- Si les opérateurs ne sont pas entièrement délégués, certaines parties du graphique du modèle sont exécutées sur le CPU plutôt que sur l'accélérateur matériel attendu. Vous pouvez remplacer les opérateurs non acceptés par des opérateurs acceptés similaires.