
Los metadatos de LiteRT proporcionan un estándar para las descripciones de modelos. Los metadatos son una fuente importante de conocimiento sobre lo que hace el modelo y su información de entrada y salida. Los metadatos constan de
- Partes legibles por humanos que transmiten la práctica recomendada cuando se usa el modelo
- partes legibles por máquina que pueden aprovechar los generadores de código, como el generador de código de LiteRT para Android y la función de vinculación de AA de Android Studio.
Todos los modelos de imágenes publicados en Kaggle Models se completaron con metadatos.
Modelo con formato de metadatos
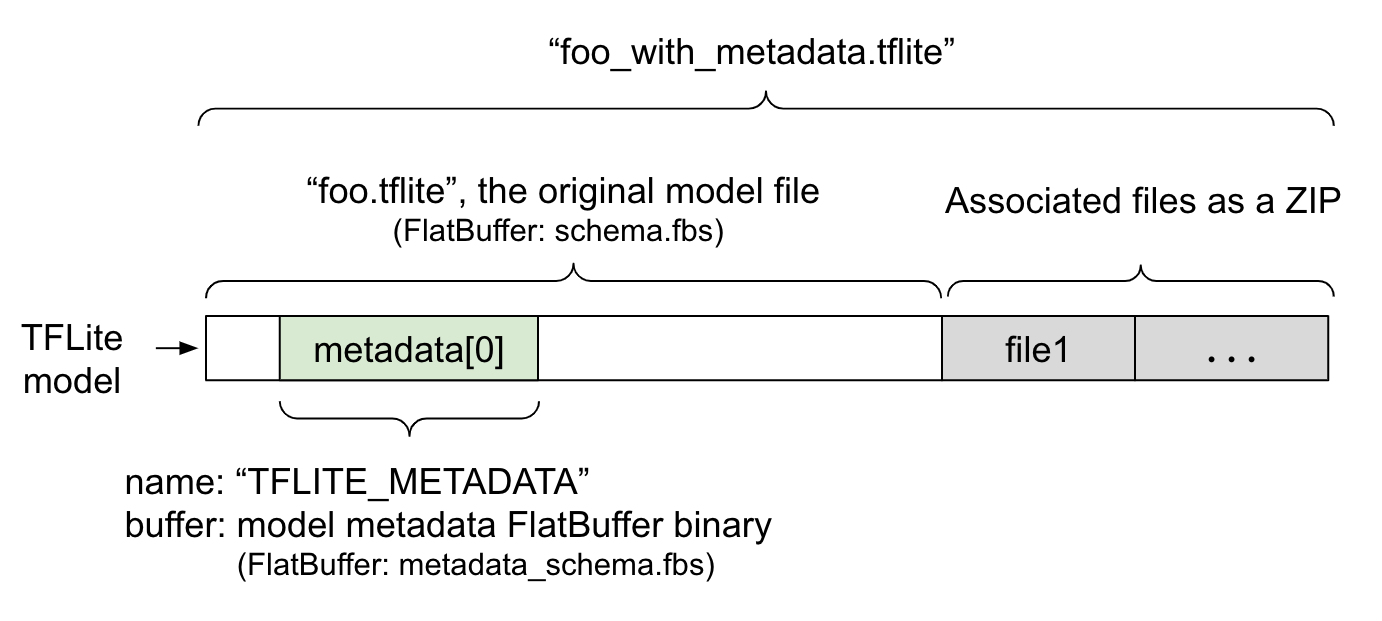
Los metadatos del modelo se definen en metadata_schema.fbs, un archivo FlatBuffer. Como se muestra en la Figura 1, se almacena en el campo metadata del esquema del modelo de TFLite, con el nombre "TFLITE_METADATA". Algunos modelos pueden incluir archivos asociados, como archivos de etiquetas de clasificación.
Estos archivos se concatenan al final del archivo del modelo original como un ZIP con el modo"append" de ZipFile (modo 'a'). El intérprete de TFLite puede consumir el nuevo formato de archivo de la misma manera que antes. Consulta Cómo empaquetar los archivos asociados para obtener más información.
Consulta las instrucciones a continuación para completar, visualizar y leer los metadatos.
Configura las herramientas de metadatos
Antes de agregar metadatos a tu modelo, deberás configurar un entorno de programación en Python para ejecutar TensorFlow. Aquí encontrarás una guía detallada para configurar esta opción.
Después de configurar el entorno de programación de Python, deberás instalar herramientas adicionales:
pip install tflite-support
Las herramientas de metadatos de LiteRT admiten Python 3.
Cómo agregar metadatos con la API de Flatbuffers para Python
Los metadatos del modelo en el esquema constan de tres partes:
- Información del modelo: Descripción general del modelo, así como elementos como las condiciones de la licencia Consulta ModelMetadata. 2. Información de entrada: Descripción de las entradas y el preprocesamiento necesarios, como la normalización. Consulta SubGraphMetadata.input_tensor_metadata. 3. Información de salida: Descripción del resultado y el posprocesamiento requerido, como la asignación a etiquetas. Consulta SubGraphMetadata.output_tensor_metadata.
Dado que LiteRT solo admite un subgrafo en este momento, el generador de código de LiteRT y la función de vinculación de AA de Android Studio usarán ModelMetadata.name y ModelMetadata.description, en lugar de SubGraphMetadata.name y SubGraphMetadata.description, cuando muestren metadatos y generen código.
Tipos de entrada y salida admitidos
Los metadatos de LiteRT para la entrada y la salida no se diseñan con tipos de modelos específicos en mente, sino con tipos de entrada y salida. No importa lo que haga el modelo funcionalmente, siempre y cuando los tipos de entrada y salida consistan en los siguientes o una combinación de los siguientes, serán compatibles con los metadatos de TensorFlow Lite:
- Es un atributo: Números que son números enteros sin signo o float32.
- Imagen: Actualmente, los metadatos admiten imágenes en RGB y en escala de grises.
- Cuadro de límite: Son cuadros de límite con forma rectangular. El esquema admite una variedad de esquemas de numeración.
Empaqueta los archivos asociados
Los modelos de LiteRT pueden incluir diferentes archivos asociados. Por ejemplo, los modelos de lenguaje natural suelen tener archivos de vocabulario que asignan fragmentos de palabras a IDs de palabras, y los modelos de clasificación pueden tener archivos de etiquetas que indican categorías de objetos. Sin los archivos asociados (si los hay), un modelo no funcionará bien.
Ahora, los archivos asociados se pueden incluir en el modelo a través de la biblioteca de Python de metadatos. El nuevo modelo de LiteRT se convierte en un archivo ZIP que contiene el modelo y los archivos asociados. Se puede descomprimir con herramientas zip comunes. Este nuevo formato de modelo sigue usando la misma extensión de archivo, .tflite. Es compatible con el framework y el intérprete de TFLite existentes. Consulta Cómo empaquetar metadatos y archivos asociados en el modelo para obtener más detalles.
La información del archivo asociado se puede registrar en los metadatos. Según el tipo de archivo y dónde se adjunta (es decir, ModelMetadata, SubGraphMetadata y TensorMetadata), el generador de código de LiteRT para Android puede aplicar automáticamente el preprocesamiento o posprocesamiento correspondiente al objeto. Consulta la sección "Uso de Codegen" de cada tipo de archivo asociado en el esquema para obtener más detalles.
Parámetros de normalización y cuantificación
La normalización es una técnica común de preprocesamiento de datos en el aprendizaje automático. El objetivo de la normalización es cambiar los valores a una escala común, sin distorsionar las diferencias en los rangos de valores.
La cuantización del modelo es una técnica que permite representaciones de precisión reducida de los pesos y, de manera opcional, de las activaciones para el almacenamiento y el procesamiento.
En términos de procesamiento previo y posterior, la normalización y la cuantificación son dos pasos independientes. A continuación, le indicamos los detalles.
| Normalización | Cuantización | |
|---|---|---|
Ejemplo de los valores de los parámetros de la imagen de entrada en MobileNet para los modelos de números flotantes y los modelos cuantificados, respectivamente. |
Modelo de números de punto flotante: - Media: 127.5 - Desviación estándar: 127.5 Modelo cuantificado: - Media: 127.5 - Desviación estándar: 127.5 |
Modelo de números de punto flotante: - zeroPoint: 0 - scale: 1.0 Modelo de números cuantificados: - zeroPoint: 128.0 - scale:0.0078125f |
¿Cuándo se debe invocar? |
Entradas: Si los datos de entrada se normalizan durante el entrenamiento, los datos de entrada de la inferencia también deben normalizarse de manera acorde. Resultados: Los datos de salida no se normalizarán en general. |
Los modelos de números de punto flotante no necesitan cuantificación. Es posible que el modelo cuantificado necesite o no cuantificación en el procesamiento previo o posterior. Depende del tipo de datos de los tensores de entrada y salida. - Tensores de números de punto flotante: No se necesita cuantización en el preprocesamiento ni el posprocesamiento. Las operaciones de cuantificación y de descuantificación se incorporan al gráfico del modelo. - Tensores int8/uint8: Necesitan cuantización en el preprocesamiento y el posprocesamiento. |
Fórmula |
normalized_input = (input - mean) / std |
Cuantificación para entradas:
q = f / scale + zeroPoint Descuantificación para salidas: f = (q - zeroPoint) * scale |
Dónde se encuentran los parámetros |
El creador del modelo lo completa y se almacena en los metadatos del modelo como NormalizationOptions. |
El conversor de TFLite lo completa automáticamente y se almacena en el archivo del modelo de TFLite. |
| ¿Cómo se obtienen los parámetros? | A través de la API de MetadataExtractor [2]
|
A través de la API de Tensor de TFLite [1] o de la API de MetadataExtractor [2] |
| ¿Los modelos de flotante y de cuantificación comparten el mismo valor? | Sí, los modelos de números de punto flotante y de cuantificación tienen los mismos parámetros de normalización. | No, el modelo de números de punto flotante no necesita cuantización. |
| ¿El generador de código de TFLite o la vinculación de AA de Android Studio lo generan automáticamente en el procesamiento de datos? | Sí |
Sí |
[1] La API de LiteRT en Java y la API de LiteRT en C++.
[2] La biblioteca del extractor de metadatos
Cuando se procesan datos de imágenes para modelos uint8, a veces se omiten la normalización y la cuantificación. Está bien hacerlo cuando los valores de píxeles están en el rango de [0, 255]. Sin embargo, en general, siempre debes procesar los datos según los parámetros de normalización y cuantificación cuando corresponda.
Ejemplos
Aquí puedes encontrar ejemplos de cómo se deben completar los metadatos para los diferentes tipos de modelos:
Clasificación de imágenes
Descarga la secuencia de comandos aquí, que completa los metadatos en mobilenet_v1_0.75_160_quantized.tflite. Ejecuta la secuencia de comandos de la siguiente manera:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Para completar los metadatos de otros modelos de clasificación de imágenes, agrega las especificaciones del modelo, como esta, al script. En el resto de esta guía, se destacarán algunas de las secciones clave del ejemplo de clasificación de imágenes para ilustrar los elementos clave.
Análisis detallado del ejemplo de clasificación de imágenes
Información del modelo
Los metadatos comienzan con la creación de un nuevo objeto ModelInfo:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Información de entrada y salida
En esta sección, se muestra cómo describir la firma de entrada y salida de tu modelo. Los generadores automáticos de código pueden usar estos metadatos para crear código de preprocesamiento y posprocesamiento. Para crear información de entrada o salida sobre un tensor, haz lo siguiente:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
entrada de imagen
Las imágenes son un tipo de entrada común para el aprendizaje automático. Los metadatos de LiteRT admiten información como el espacio de color y el procesamiento previo, como la normalización. La dimensión de la imagen no requiere especificación manual, ya que la proporciona la forma del tensor de entrada y se puede inferir automáticamente.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Etiqueta de salida
La etiqueta se puede asignar a un tensor de salida a través de un archivo asociado con TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Crea los Flatbuffers de metadatos
El siguiente código combina la información del modelo con la información de entrada y salida:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Cómo empaquetar metadatos y archivos asociados en el modelo
Una vez que se crean los Flatbuffers de metadatos, los metadatos y el archivo de etiquetas se escriben en el archivo de TFLite a través del método populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Puedes incluir tantos archivos asociados como desees en el modelo a través de load_associated_files. Sin embargo, es necesario empaquetar al menos los archivos que se documentan en los metadatos. En este ejemplo, es obligatorio empaquetar el archivo de etiquetas.
Visualiza los metadatos
Puedes usar Netron para visualizar tus metadatos, o bien puedes leer los metadatos de un modelo de LiteRT en formato JSON con MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio también admite la visualización de metadatos a través de la función de vinculación de ML de Android Studio.
Control de versiones de metadatos
El esquema de metadatos se versiona tanto por el número de versión semántica, que hace un seguimiento de los cambios del archivo de esquema, como por la identificación del archivo de Flatbuffers, que indica la verdadera compatibilidad de versiones.
Número de control de versiones semántico
El esquema de metadatos se versiona con el número de versión semántica, como MAJOR.MINOR.PATCH. Realiza un seguimiento de los cambios de esquema según las reglas que se indican aquí.
Consulta el historial de campos agregados después de la versión 1.0.0.
Identificación del archivo de Flatbuffers
El versionamiento semántico garantiza la compatibilidad si se siguen las reglas, pero no implica la verdadera incompatibilidad. Cuando se aumenta el número de versión PRINCIPAL, no necesariamente significa que se rompió la compatibilidad con versiones anteriores. Por lo tanto, usamos el identificador de archivo de Flatbuffers, file_identifier, para indicar la compatibilidad real del esquema de metadatos. El identificador de archivo tiene exactamente 4 caracteres. Está fijo a un esquema de metadatos determinado y los usuarios no pueden cambiarlo. Si la compatibilidad con versiones anteriores del esquema de metadatos debe interrumpirse por algún motivo, el valor de file_identifier aumentará, por ejemplo, de "M001" a "M002". Se espera que el valor de file_identifier cambie con mucha menos frecuencia que el de metadata_version.
Versión mínima necesaria del analizador de metadatos
La versión mínima necesaria del analizador de metadatos es la versión mínima del analizador de metadatos (el código generado por Flatbuffers) que puede leer los Flatbuffers de metadatos en su totalidad. Efectivamente, la versión es el número de versión más grande entre las versiones de todos los campos completados y la versión compatible más pequeña que indica el identificador de archivo. El MetadataPopulator completa automáticamente la versión mínima necesaria del analizador de metadatos cuando los metadatos se completan en un modelo de TFLite. Consulta el extractor de metadatos para obtener más información sobre cómo se usa la versión mínima necesaria del analizador de metadatos.
Leer los metadatos de los modelos
La biblioteca Metadata Extractor es una herramienta conveniente para leer los metadatos y los archivos asociados de los modelos en diferentes plataformas (consulta la versión en Java y la versión en C++). Puedes compilar tu propia herramienta de extracción de metadatos en otros lenguajes con la biblioteca de Flatbuffers.
Cómo leer los metadatos en Java
Para usar la biblioteca Metadata Extractor en tu app para Android, te recomendamos que uses el AAR de metadatos de LiteRT alojado en MavenCentral.
Contiene la clase MetadataExtractor, así como las vinculaciones de FlatBuffers Java para el esquema de metadatos y el esquema del modelo.
Puedes especificar esto en tus dependencias de build.gradle de la siguiente manera:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Para usar instantáneas nocturnas, asegúrate de haber agregado el repositorio de instantáneas de Sonatype.
Puedes inicializar un objeto MetadataExtractor con un ByteBuffer que apunte al modelo:
public MetadataExtractor(ByteBuffer buffer);
El valor de ByteBuffer debe permanecer sin cambios durante toda la vida útil del objeto MetadataExtractor. Es posible que la inicialización falle si el identificador del archivo Flatbuffers de los metadatos del modelo no coincide con el del analizador de metadatos. Consulta Control de versiones de metadatos para obtener más información.
Con identificadores de archivos coincidentes, el extractor de metadatos leerá correctamente los metadatos generados a partir de todos los esquemas pasados y futuros gracias al mecanismo de compatibilidad con versiones anteriores y posteriores de Flatbuffers. Sin embargo, los extractores de metadatos más antiguos no pueden extraer campos de esquemas futuros. La versión mínima necesaria del analizador de los metadatos indica la versión mínima del analizador de metadatos que puede leer los Flatbuffers de metadatos en su totalidad. Puedes usar el siguiente método para verificar si se cumple la condición de versión mínima necesaria del analizador:
public final boolean isMinimumParserVersionSatisfied();
Se permite pasar un modelo sin metadatos. Sin embargo, invocar métodos que leen los metadatos causará errores de tiempo de ejecución. Para verificar si un modelo tiene metadatos, invoca el método hasMetadata:
public boolean hasMetadata();
MetadataExtractor proporciona funciones convenientes para que obtengas los metadatos de los tensores de entrada y salida. Por ejemplo:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Si bien el esquema del modelo LiteRT admite varios subgrafos, el intérprete de TFLite actualmente solo admite un subgrafo. Por lo tanto, MetadataExtractor omite el índice de subgrafo como argumento de entrada en sus métodos.
Leer los archivos asociados de los modelos
El modelo de LiteRT con metadatos y archivos asociados es, básicamente, un archivo ZIP que se puede descomprimir con herramientas comunes de ZIP para obtener los archivos asociados. Por ejemplo, puedes descomprimir mobilenet_v1_0.75_160_quantized y extraer el archivo de etiquetas en el modelo de la siguiente manera:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
También puedes leer archivos asociados a través de la biblioteca Metadata Extractor.
En Java, pasa el nombre del archivo al método MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Del mismo modo, en C++, esto se puede hacer con el método ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;