
Siêu dữ liệu LiteRT cung cấp một tiêu chuẩn cho nội dung mô tả mô hình. Siêu dữ liệu là một nguồn kiến thức quan trọng về những việc mà mô hình thực hiện và thông tin đầu vào / đầu ra của mô hình. Siêu dữ liệu bao gồm cả
- các phần dễ đọc truyền tải phương pháp hay nhất khi sử dụng mô hình và
- các phần mà máy có thể đọc được và có thể được các trình tạo mã tận dụng, chẳng hạn như trình tạo mã Android LiteRT và tính năng Liên kết ML của Android Studio.
Tất cả các mô hình hình ảnh được xuất bản trên Kaggle Models đều đã được điền sẵn siêu dữ liệu.
Mô hình có định dạng siêu dữ liệu
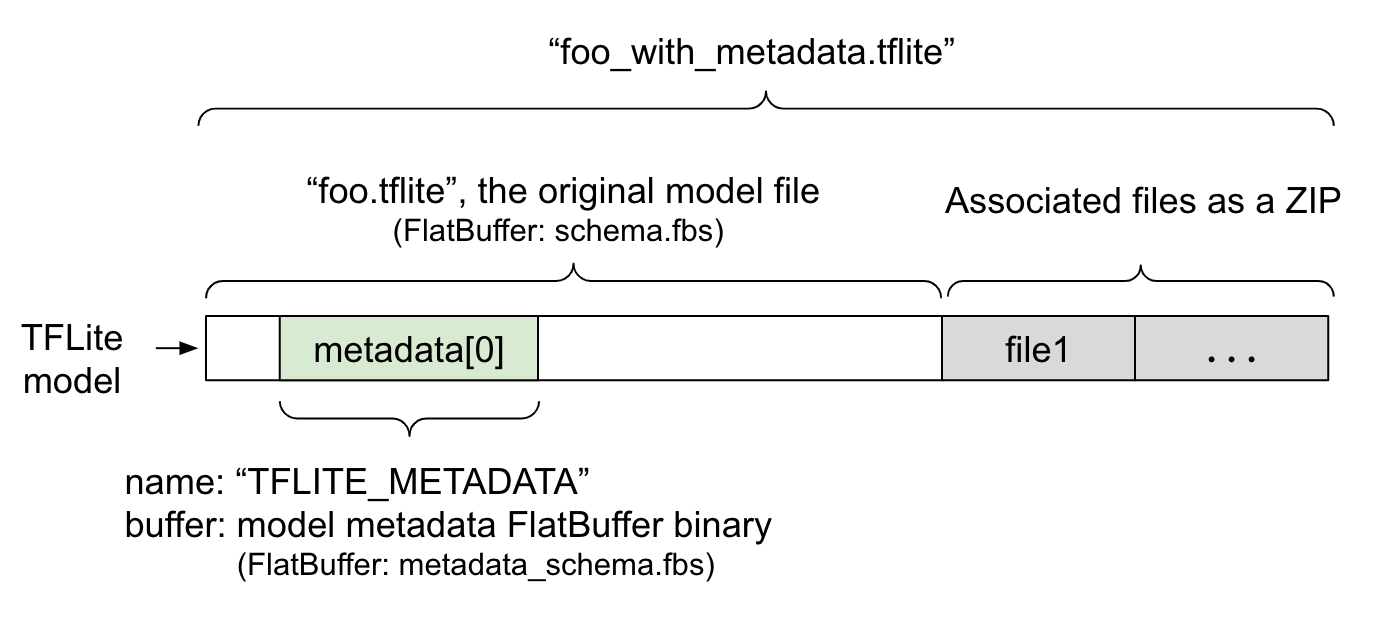
Siêu dữ liệu mô hình được xác định trong metadata_schema.fbs, một tệp FlatBuffer. Như trong Hình 1, siêu dữ liệu này được lưu trữ trong trường metadata của sơ đồ mô hình TFLite, có tên là "TFLITE_METADATA". Một số mô hình có thể đi kèm với các tệp liên kết, chẳng hạn như tệp nhãn phân loại.
Các tệp này được nối vào cuối tệp mô hình gốc dưới dạng tệp ZIP bằng chế độ ZipFile "append" (chế độ 'a'). Trình thông dịch TFLite có thể sử dụng định dạng tệp mới theo cách tương tự như trước đây. Hãy xem phần Đóng gói các tệp liên kết để biết thêm thông tin.
Hãy xem hướng dẫn bên dưới về cách điền, trực quan hoá và đọc siêu dữ liệu.
Thiết lập các công cụ siêu dữ liệu
Trước khi thêm siêu dữ liệu vào mô hình, bạn cần thiết lập một môi trường lập trình Python để chạy TensorFlow. Bạn có thể xem hướng dẫn chi tiết về cách thiết lập tính năng này tại đây.
Sau khi thiết lập môi trường lập trình Python, bạn sẽ cần cài đặt các công cụ bổ sung:
pip install tflite-support
Công cụ siêu dữ liệu LiteRT hỗ trợ Python 3.
Thêm siêu dữ liệu bằng Flatbuffers Python API
Siêu dữ liệu mô hình trong schema có 3 phần:
- Thông tin về mô hình – Nội dung mô tả tổng thể về mô hình cũng như các mục như điều khoản cấp phép. Xem ModelMetadata. 2. Thông tin đầu vào – Nội dung mô tả về các đầu vào và quá trình xử lý trước cần thiết, chẳng hạn như chuẩn hoá. Xem SubGraphMetadata.input_tensor_metadata. 3. Thông tin đầu ra – Nội dung mô tả về đầu ra và quá trình xử lý hậu kỳ cần thiết, chẳng hạn như ánh xạ đến nhãn. Xem SubGraphMetadata.output_tensor_metadata.
Vì LiteRT hiện chỉ hỗ trợ một đồ thị con, nên trình tạo mã LiteRT và tính năng Liên kết ML của Android Studio sẽ sử dụng ModelMetadata.name và ModelMetadata.description thay vì SubGraphMetadata.name và SubGraphMetadata.description khi hiển thị siêu dữ liệu và tạo mã.
Các loại đầu vào / đầu ra được hỗ trợ
Siêu dữ liệu LiteRT cho đầu vào và đầu ra không được thiết kế cho các loại mô hình cụ thể mà là cho các loại đầu vào và đầu ra. Không quan trọng chức năng của mô hình là gì, miễn là các loại đầu vào và đầu ra bao gồm những loại sau hoặc kết hợp những loại sau, thì siêu dữ liệu TensorFlow Lite sẽ hỗ trợ:
- Đối tượng – Các số là số nguyên chưa ký hoặc float32.
- Hình ảnh – Siêu dữ liệu hiện hỗ trợ hình ảnh RGB và hình ảnh thang độ xám.
- Hộp giới hạn – Hộp giới hạn hình chữ nhật. Lược đồ này hỗ trợ nhiều lược đồ đánh số.
Đóng gói các tệp liên kết
Các mô hình LiteRT có thể đi kèm với nhiều tệp được liên kết. Ví dụ: các mô hình ngôn ngữ tự nhiên thường có các tệp từ vựng ánh xạ các phần từ với mã nhận dạng từ; các mô hình phân loại có thể có các tệp nhãn cho biết danh mục đối tượng. Nếu không có các tệp liên kết (nếu có), mô hình sẽ không hoạt động hiệu quả.
Giờ đây, bạn có thể đi kèm các tệp được liên kết với mô hình thông qua thư viện siêu dữ liệu Python. Mô hình LiteRT mới sẽ trở thành một tệp zip chứa cả mô hình và các tệp liên kết. Bạn có thể giải nén tệp này bằng các công cụ zip thông thường. Định dạng mô hình mới này vẫn sử dụng cùng một đuôi tệp, .tflite. Nền tảng này tương thích với khung TFLite và Trình thông dịch hiện có. Hãy xem phần Đóng gói siêu dữ liệu và các tệp liên kết vào mô hình để biết thêm thông tin chi tiết.
Thông tin về tệp liên kết có thể được ghi lại trong siêu dữ liệu. Tuỳ thuộc vào loại tệp và vị trí tệp được đính kèm (tức là ModelMetadata, SubGraphMetadata và TensorMetadata), trình tạo mã Android LiteRT có thể tự động áp dụng quy trình xử lý trước/sau tương ứng cho đối tượng. Hãy xem phần <Codegen usage> (Cách sử dụng Codegen) của từng loại tệp liên kết trong giản đồ để biết thêm thông tin.
Các thông số chuẩn hoá và lượng tử hoá
Chuẩn hoá là một kỹ thuật tiền xử lý dữ liệu phổ biến trong học máy. Mục tiêu của việc chuẩn hoá là thay đổi các giá trị thành một tỷ lệ chung mà không làm sai lệch sự khác biệt trong phạm vi giá trị.
Lượng tử hoá mô hình là một kỹ thuật cho phép giảm độ chính xác của các biểu diễn về trọng số và tuỳ chọn, các hoạt động cho cả bộ nhớ và quá trình tính toán.
Về tiền xử lý và hậu xử lý, chuẩn hoá và định lượng là hai bước độc lập. Dưới đây là các chi tiết.
| Chuẩn hoá | Lượng tử hoá | |
|---|---|---|
Ví dụ về các giá trị tham số của hình ảnh đầu vào trong MobileNet cho các mô hình số thực và lượng tử hoá, tương ứng. |
Mô hình số thực: - giá trị trung bình: 127,5 - độ lệch chuẩn: 127,5 Mô hình lượng tử hoá: - giá trị trung bình: 127,5 - độ lệch chuẩn: 127,5 |
Mô hình số thực: - zeroPoint: 0 - scale: 1.0 Mô hình lượng tử hoá: - zeroPoint: 128.0 - scale:0.0078125f |
Khi nào thì gọi? |
Đầu vào: Nếu dữ liệu đầu vào được chuẩn hoá trong quá trình huấn luyện, thì dữ liệu đầu vào của suy luận cũng cần được chuẩn hoá cho phù hợp. Đầu ra: dữ liệu đầu ra thường sẽ không được chuẩn hoá. |
Các mô hình dấu phẩy động không cần định lượng. Mô hình được lượng tử hoá có thể cần hoặc không cần lượng tử hoá trong quá trình xử lý trước/sau. Điều này phụ thuộc vào kiểu dữ liệu của tensor đầu vào/đầu ra. - tensor số thực: không cần định lượng trong quá trình xử lý trước/sau. Quant op và dequant op được tích hợp vào biểu đồ mô hình. - int8/uint8 tensor: cần định lượng trong quá trình xử lý trước/sau. |
Công thức |
normalized_input = (input - mean) / std |
Lượng tử hoá cho dữ liệu đầu vào:
q = f / scale + zeroPoint Giải lượng tử hoá cho dữ liệu đầu ra: f = (q – zeroPoint) * scale |
Các tham số nằm ở đâu |
Do người tạo mô hình điền và được lưu trữ trong siêu dữ liệu mô hình, dưới dạng NormalizationOptions |
Được trình chuyển đổi TFLite tự động điền và được lưu trữ trong tệp mô hình tflite. |
| Làm cách nào để lấy các tham số? | Thông qua API MetadataExtractor [2]
|
Thông qua API TFLite Tensor [1] hoặc thông qua API MetadataExtractor [2] |
| Các mô hình float và quant có dùng chung giá trị không? | Có, các mô hình số thực và lượng tử hoá có cùng các tham số Chuẩn hoá | Không, mô hình số thực không cần định lượng. |
| Trình tạo mã TFLite hoặc tính năng liên kết mô hình máy học của Android Studio có tự động tạo mã này trong quá trình xử lý dữ liệu không? | Có |
Có |
[1] API LiteRT Java và API LiteRT C++.
[2] Thư viện trình trích xuất siêu dữ liệu
Khi xử lý dữ liệu hình ảnh cho các mô hình uint8, đôi khi quá trình chuẩn hoá và lượng tử hoá sẽ bị bỏ qua. Bạn có thể làm như vậy khi các giá trị pixel nằm trong phạm vi [0, 255]. Nhưng nói chung, bạn phải luôn xử lý dữ liệu theo các thông số chuẩn hoá và lượng tử hoá khi có thể.
Ví dụ
Bạn có thể xem ví dụ về cách điền sẵn siêu dữ liệu cho nhiều loại mô hình tại đây:
Phân loại hình ảnh
Tải tập lệnh xuống tại đây. Tập lệnh này sẽ điền sẵn siêu dữ liệu vào mobilenet_v1_0.75_160_quantized.tflite. Chạy tập lệnh như sau:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Để điền sẵn siêu dữ liệu cho các mô hình phân loại hình ảnh khác, hãy thêm thông số mô hình như thông số này vào tập lệnh. Phần còn lại của hướng dẫn này sẽ nêu bật một số phần chính trong ví dụ về phân loại hình ảnh để minh hoạ các phần tử chính.
Tìm hiểu kỹ về ví dụ phân loại hình ảnh
Thông tin mẫu
Siêu dữ liệu bắt đầu bằng việc tạo thông tin mô hình mới:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Thông tin đầu vào / đầu ra
Phần này hướng dẫn cách mô tả chữ ký đầu vào và đầu ra của mô hình. Trình tạo mã tự động có thể sử dụng siêu dữ liệu này để tạo mã xử lý trước và sau. Cách tạo thông tin đầu vào hoặc đầu ra về một tensor:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Đầu vào hình ảnh
Hình ảnh là một loại dữ liệu đầu vào phổ biến cho học máy. Siêu dữ liệu LiteRT hỗ trợ thông tin như không gian màu và thông tin tiền xử lý như chuẩn hoá. Bạn không cần chỉ định kích thước của hình ảnh theo cách thủ công vì kích thước này đã được cung cấp theo hình dạng của tensor đầu vào và có thể được suy luận tự động.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Gắn nhãn cho dữ liệu đầu ra
Bạn có thể liên kết nhãn với một tensor đầu ra thông qua một tệp được liên kết bằng cách sử dụng TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Tạo Flatbuffer siêu dữ liệu
Đoạn mã sau đây kết hợp thông tin về mô hình với thông tin đầu vào và đầu ra:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Đóng gói siêu dữ liệu và các tệp liên kết vào mô hình
Sau khi Flatbuffers siêu dữ liệu được tạo, siêu dữ liệu và tệp nhãn sẽ được ghi vào tệp TFLite thông qua phương thức populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Bạn có thể đóng gói bao nhiêu tệp liên kết tuỳ thích vào mô hình thông qua load_associated_files. Tuy nhiên, bạn phải đóng gói ít nhất những tệp được ghi lại trong siêu dữ liệu. Trong ví dụ này, bạn bắt buộc phải đóng gói tệp nhãn.
Trực quan hoá siêu dữ liệu
Bạn có thể dùng Netron để trực quan hoá siêu dữ liệu hoặc có thể đọc siêu dữ liệu từ mô hình LiteRT sang định dạng json bằng cách dùng MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio cũng hỗ trợ hiển thị siêu dữ liệu thông qua tính năng Liên kết ML của Android Studio.
Phân phiên bản siêu dữ liệu
Giản đồ siêu dữ liệu được lập phiên bản theo cả số phiên bản Semantic (theo dõi các thay đổi của tệp giản đồ) và mã nhận dạng tệp Flatbuffers (cho biết khả năng tương thích thực sự của phiên bản).
Số phiên bản ngữ nghĩa
Giản đồ siêu dữ liệu được lập phiên bản theo Số phiên bản ngữ nghĩa, chẳng hạn như MAJOR.MINOR.PATCH. Công cụ này theo dõi các thay đổi về giản đồ theo các quy tắc tại đây.
Xem nhật ký về các trường được thêm sau phiên bản 1.0.0.
Thông tin nhận dạng tệp Flatbuffers
Việc phân phiên bản theo ngữ nghĩa đảm bảo khả năng tương thích nếu tuân thủ các quy tắc, nhưng không ngụ ý sự không tương thích thực sự. Khi tăng số CHÍNH, điều đó không nhất thiết có nghĩa là khả năng tương thích ngược bị gián đoạn. Do đó, chúng tôi sử dụng phương thức nhận dạng tệp Flatbuffers, file_identifier, để biểu thị khả năng tương thích thực sự của lược đồ siêu dữ liệu. Giá trị nhận dạng tệp có độ dài chính xác là 4 ký tự. Nó được cố định vào một lược đồ siêu dữ liệu nhất định và người dùng không thể thay đổi. Nếu vì lý do nào đó mà khả năng tương thích ngược của giản đồ siêu dữ liệu phải bị phá vỡ, thì file_identifier sẽ tăng lên, ví dụ: từ "M001" thành "M002". File_identifier dự kiến sẽ thay đổi ít thường xuyên hơn nhiều so với metadata_version.
Phiên bản trình phân tích cú pháp siêu dữ liệu tối thiểu cần thiết
Phiên bản trình phân tích cú pháp siêu dữ liệu tối thiểu cần thiết là phiên bản tối thiểu của trình phân tích cú pháp siêu dữ liệu (mã do Flatbuffers tạo) có thể đọc toàn bộ siêu dữ liệu Flatbuffers. Phiên bản này là số phiên bản lớn nhất trong số các phiên bản của tất cả các trường được điền sẵn và phiên bản tương thích nhỏ nhất do giá trị nhận dạng tệp chỉ ra. MetadataPopulator sẽ tự động điền phiên bản trình phân tích cú pháp siêu dữ liệu tối thiểu cần thiết khi siêu dữ liệu được điền vào một mô hình TFLite. Hãy xem trình trích xuất siêu dữ liệu để biết thêm thông tin về cách sử dụng phiên bản trình phân tích cú pháp siêu dữ liệu tối thiểu cần thiết.
Đọc siêu dữ liệu từ các mô hình
Thư viện Trình trích xuất siêu dữ liệu là một công cụ thuận tiện để đọc siêu dữ liệu và các tệp được liên kết từ các mô hình trên nhiều nền tảng (xem phiên bản Java và phiên bản C++). Bạn có thể tạo công cụ trích xuất siêu dữ liệu của riêng mình bằng các ngôn ngữ khác bằng cách sử dụng thư viện Flatbuffers.
Đọc siêu dữ liệu bằng Java
Để sử dụng thư viện Trình trích xuất siêu dữ liệu trong ứng dụng Android, bạn nên sử dụng Siêu dữ liệu LiteRT AAR được lưu trữ tại MavenCentral.
Thư viện này chứa lớp MetadataExtractor, cũng như các liên kết FlatBuffers Java cho sơ đồ siêu dữ liệu và sơ đồ mô hình.
Bạn có thể chỉ định điều này trong các phần phụ thuộc build.gradle như sau:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Để sử dụng ảnh chụp nhanh hằng đêm, hãy đảm bảo rằng bạn đã thêm kho lưu trữ ảnh chụp nhanh Sonatype.
Bạn có thể khởi động một đối tượng MetadataExtractor bằng một ByteBuffer trỏ đến mô hình:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer phải giữ nguyên trong toàn bộ vòng đời của đối tượng MetadataExtractor. Quá trình khởi tạo có thể không thành công nếu mã nhận dạng tệp Flatbuffers của siêu dữ liệu mô hình không khớp với mã nhận dạng của trình phân tích cú pháp siêu dữ liệu. Hãy xem phần tạo phiên bản siêu dữ liệu để biết thêm thông tin.
Với các giá trị nhận dạng tệp trùng khớp, trình trích xuất siêu dữ liệu sẽ đọc thành công siêu dữ liệu được tạo từ tất cả giản đồ trước đây và trong tương lai do cơ chế tương thích ngược và tương thích xuôi của Flatbuffers. Tuy nhiên, các trình trích xuất siêu dữ liệu cũ không thể trích xuất các trường từ lược đồ trong tương lai. Phiên bản trình phân tích cú pháp tối thiểu cần thiết của siêu dữ liệu cho biết phiên bản tối thiểu của trình phân tích cú pháp siêu dữ liệu có thể đọc toàn bộ Flatbuffers siêu dữ liệu. Bạn có thể sử dụng phương pháp sau để xác minh xem điều kiện phiên bản trình phân tích cú pháp tối thiểu cần thiết có được đáp ứng hay không:
public final boolean isMinimumParserVersionSatisfied();
Bạn được phép truyền vào một mô hình không có siêu dữ liệu. Tuy nhiên, việc gọi các phương thức đọc từ siêu dữ liệu sẽ gây ra lỗi thời gian chạy. Bạn có thể kiểm tra xem một mô hình có siêu dữ liệu hay không bằng cách gọi phương thức hasMetadata:
public boolean hasMetadata();
MetadataExtractor cung cấp các hàm thuận tiện để bạn lấy siêu dữ liệu của các tensor đầu vào/đầu ra. Ví dụ:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Mặc dù sơ đồ mô hình LiteRT hỗ trợ nhiều đồ thị con, nhưng Trình thông dịch TFLite hiện chỉ hỗ trợ một đồ thị con. Do đó, MetadataExtractor bỏ qua chỉ mục đồ thị con làm đối số đầu vào trong các phương thức của nó.
Đọc các tệp liên kết từ các mô hình
Về cơ bản, mô hình LiteRT có siêu dữ liệu và các tệp liên kết là một tệp zip có thể được giải nén bằng các công cụ zip thông thường để lấy các tệp liên kết. Ví dụ: bạn có thể giải nén mobilenet_v1_0.75_160_quantized và trích xuất tệp nhãn trong mô hình như sau:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Bạn cũng có thể đọc các tệp liên kết thông qua thư viện Trình trích xuất siêu dữ liệu.
Trong Java, hãy truyền tên tệp vào phương thức MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Tương tự, trong C++, bạn có thể thực hiện việc này bằng phương thức ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;