
邊緣裝置通常的記憶體或運算能力有限。集成 最佳化功能可以套用至模型 限制。此外,某些最佳化功能允許您針對 加快推論速度
LiteRT 和 TensorFlow 模型最佳化 工具包提供工具 將最佳化推論的複雜度降到最低
建議您在申請過程中將模型最佳化 開發流程本文件將概述最佳化的幾個最佳做法 用於部署至邊緣硬體的 TensorFlow 模型。
為什麼要將模型最佳化
模型最佳化功能在處理應用程式時 。
縮減大小
有些最佳化形式可用來縮減模型的大小。較小 優點如下:
- 儲存空間大小較小:較小型的模型占用較少儲存空間 使用者裝置。舉例來說,採用小型模型的 Android 應用程式 減少使用者行動裝置的儲存空間
- 下載大小較小:較小型的模型在下載前需要花費的時間和頻寬較少。 使用者下載的產品/服務裝置。
- 記憶體用量較低:較小的模型會在執行時佔用較少 RAM, 應用程式會釋出記憶體給應用程式的其他部分使用 進而提升效能和穩定性
量化功能可以縮減模型的大小 但可能會有一些準確性修剪和分群法能縮減 以便輕鬆壓縮
減少延遲
延遲時間是指在特定條件下執行單一推論所需的時間 模型某些最佳化形式可以減少所需的運算量 以使用模型進行推論,進而縮短延遲時間延遲也可能 都可能會影響耗電量
目前,量化可用於簡化 推論期間的運算作業,可能會由 準確度。
加速器相容性
部分硬體加速器,例如 Edge TPU 支援極快速的推論作業, 使用經過適當最佳化調整的模型
一般來說,這些類型的裝置必須依照特定 。請參閱各硬體加速器的說明文件,進一步瞭解 Google Cloud 就是最佳選擇
優缺點
最佳化作業可能會導致模型準確度發生變化, 都會採用這個原則
準確度變化則視要最佳化的個別模型而定 難以事先預測一般來說,經過最佳化調整的模型 模型大小或延遲時間就會失去一小部分的準確率。視您的 是否會影響您使用者的無須專人管理在極少數情況下 某些模型的某些模型可能會因為最佳化程序而獲得一些準確性。
最佳化類型
LiteRT 目前透過量化、修剪和 分群法
這些都是 TensorFlow 模型最佳化 這些工具 與 TensorFlow 相容的模型最佳化技術資源 精簡
量化
量化 的運作方式是降低模型輸出內容使用數字的精確度 參數,預設為 32 位元浮點數。這會產生 縮減模型大小並加快運算速度
LiteRT 提供下列類型的量化功能:
| 做法 | 資料條件 | 縮減大小 | 準確率 | 支援的硬體 |
|---|---|---|---|---|
| 訓練後的 float16 量化 | 沒有資料 | 最高 50% | 準確率損失極低 | CPU、GPU |
| 訓練後的動態範圍量化 | 沒有資料 | 高達 75% | 準確率損失最低 | CPU、GPU (Android) |
| 訓練後的整數量化 | 未標示代表性樣本 | 高達 75% | 準確度損失較低 | CPU、GPU (Android)、EdgeTPU |
| 量化感知訓練 | 有標籤的訓練資料 | 高達 75% | 準確率損失最低 | CPU、GPU (Android)、EdgeTPU |
下列決策樹狀圖有助於選取您可能想要的量化配置 要用於模型的訓練即可 準確度。
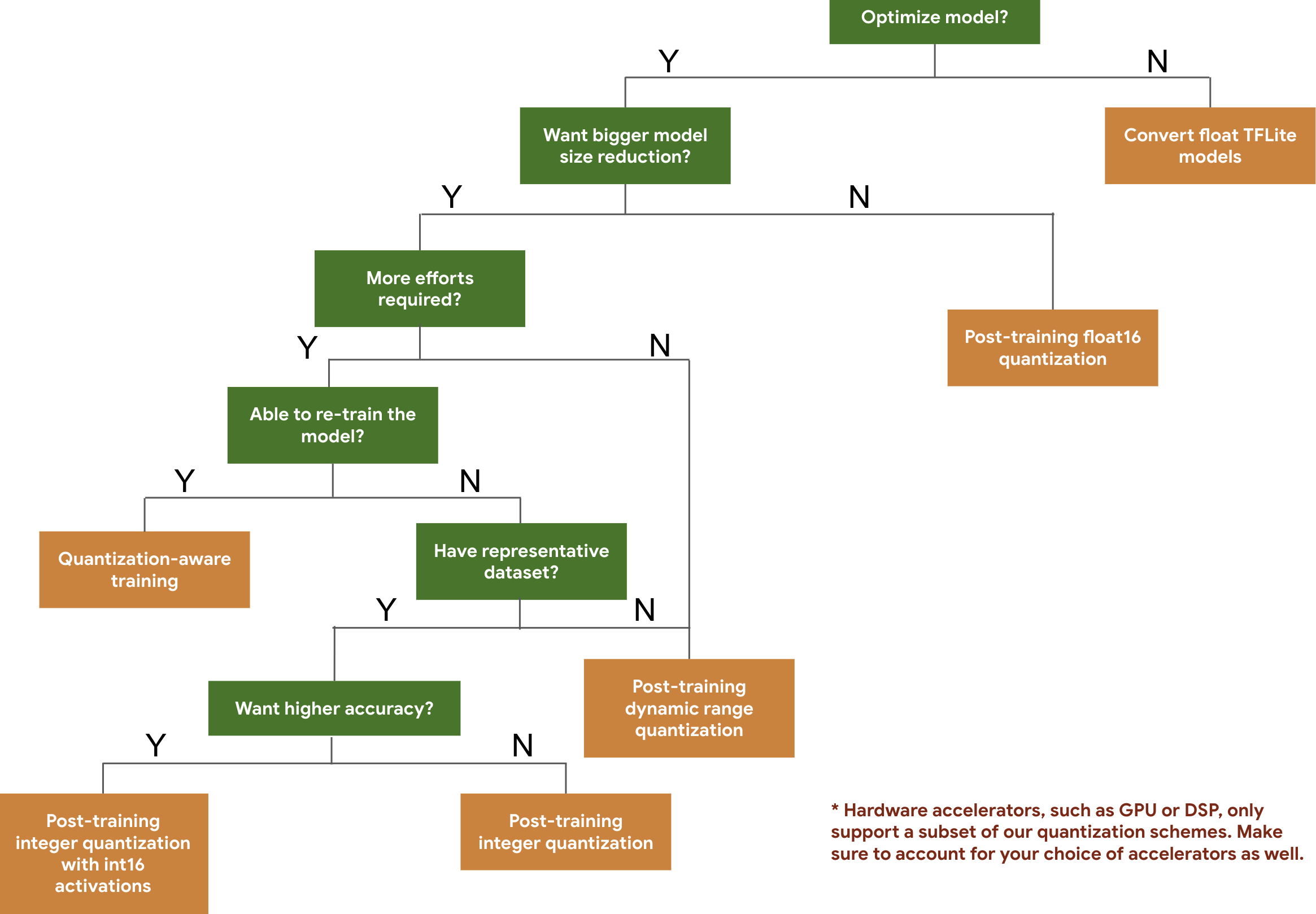
以下是訓練後的量化延遲和準確率結果, 在幾個模型上進行量化感知訓練所有延遲數據的測量依據 使用單一大核心 CPU 的 Pixel 2 裝置。隨著工具包不斷改進 這裡的數字:
| 型號 | 排名前 1 的準確率 (原始) | 1 大準確率 (後訓練量化) | 1 大準確率 (量化感知訓練) | 延遲時間 (原始) (毫秒) | 延遲時間 (後的訓練量化) (毫秒) | 延遲時間 (量化感知訓練,毫秒) | 大小 (原始) (MB) | 大小 (最佳化) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | $0.709 美元 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 人 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 美元 | 0.637 | $0.709 美元 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | $0.78 美元 | 0.772 | 0.775 美元 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 美元 | 0.768 | 不適用 | 3973 | 2868 | 不適用 | 178.3 號 | 44.9 人 |
透過 int16 啟動和 int8 權重進行完整整數量化
透過 int16 啟用量量化 是全整數量化配置,啟用 int16,在 int8。與 在 int8 中同時執行活化和權重的完整整數量化配置 保持類似的模型大小如果啟動時機非常敏感,則建議採用這個選項 和量化指標
注意:目前只有未最佳化的參考核心實作項目: 適用於這個量化配置的 TFLite 格式,因此根據預設, 速度會比 int8 核心更慢這個模式的完整優點 可透過專屬硬體或自訂軟體存取。
以下是一些能善加利用這個模式的模型的準確率結果。
| 型號 | 準確度指標類型 | 準確度 (float32 啟動) | 準確度 (int8 啟用) | 準確度 (int16 啟用次數) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (未發布) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | 前 1 大準確率 | 0.7062 版 | $0.694 美元 | 0.6936 |
| MobileNetV2 | 前 1 大準確率 | 0.718 | 0.7126 | 0.7137 版 |
| MobileBert | F1(完全比對) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
修枝鋸
裁舊的運作方式 移除模型中,對模型有小影響的參數 預測結果經過縮減的模型大小和磁碟大小相同,執行階段也相同 但可以更有效率地壓縮因此,裁舊是非常實用的 可縮減模型下載大小
LiteRT 日後能有效降低已修剪模型的延遲時間。
分群
分群法 原理是將模型中每個圖層的權重分組,並歸類至預先定義的數字 取得分群法的質量值 個別叢集這樣可減少模型中不重複權重值的數量 進而降低複雜度
因此,叢集模型可以更有效率地壓縮, 與裁舊類似
開發工作流程
作為起點,請先檢查 模型適用於您的應用程式如果不是, 建議使用者先從訓練後的量化作業著手 工具因為這樣普遍適用,而且 不需要使用訓練資料
不符合準確性與延遲時間目標的情況,或硬體不足時 加速器支援相當重要,具有量化能力感知能力 訓練 是更好的選擇如需更多最佳化技巧,請參閱 TensorFlow 模型最佳化 工具包。