
अपने मॉडल में इस्तेमाल किए जाने वाले मशीन लर्निंग (एमएल) ऑपरेटर का इस्तेमाल करने से, कन्वर्ज़न की प्रोसेस TensorFlow मॉडल से LiteRT फ़ॉर्मैट में. LiteRT कन्वर्टर TensorFlow की कुछ कार्रवाइयों के साथ काम करता है जिनका इस्तेमाल सामान्य तौर पर किया जाता है अनुमान मॉडल का मतलब है कि हर मॉडल सीधे तौर पर कन्वर्टेबल नहीं होता. कन्वर्टर टूल की मदद से, ऐसे ऑपरेटर को शामिल किया जा सकता है जो मॉडल चुनने के बाद, आपको LiteRT रनटाइम में बदलाव करना होगा आपके मॉडल को एक्ज़ीक्यूट करने के लिए इस्तेमाल किया जाता है. इससे मॉडल को चलाने की क्षमता सीमित हो सकती है स्टैंडर्ड रनटाइम डिप्लॉयमेंट विकल्पों का इस्तेमाल करें, जैसे कि Google Play services.
LiteRT Converter को मॉडल का विश्लेषण करने के लिए डिज़ाइन किया गया है स्ट्रक्चर के साथ-साथ और ऑप्टिमाइज़ेशन लागू करके उसे सीधे तौर पर इस्तेमाल किए जा सकने वाले ऑपरेटर. उदाहरण के लिए, एमएल ऑपरेटर के आधार पर तो आपका मॉडल, कन्वर्टर हो सकता है उन्हें जोड़ना या फ़्यूज़ करना ऑपरेटर का इस्तेमाल किया जा सकता है, ताकि उन्हें अपने LiteRT समकक्षों से मैप किया जा सके.
साथ काम करने वाली कार्रवाइयों के लिए भी, कभी-कभी इस्तेमाल के खास पैटर्न की उम्मीद की जाती है. की समीक्षा करें. TensorFlow को बनाने का सबसे अच्छा तरीका मॉडल है, जिसका इस्तेमाल LiteRT, संक्रियाओं को रूपांतरित करने के तरीके पर विचार करता है और साथ ही, ऑप्टिमाइज़ करने में मदद मिलेगी.
ये ऑपरेटर इस्तेमाल किए जा सकते हैं
LiteRT बिल्ट-इन ऑपरेटर, ऑपरेटर के सबसेट होते हैं जो TensorFlow की कोर लाइब्रेरी का हिस्सा हैं. आपका TensorFlow मॉडल कंपोज़िट ऑपरेटर के रूप में कस्टम ऑपरेटर को भी शामिल करना या नए ऑपरेटर होते हैं. नीचे दिया गया डायग्राम, इन ऑपरेटर के बीच में.
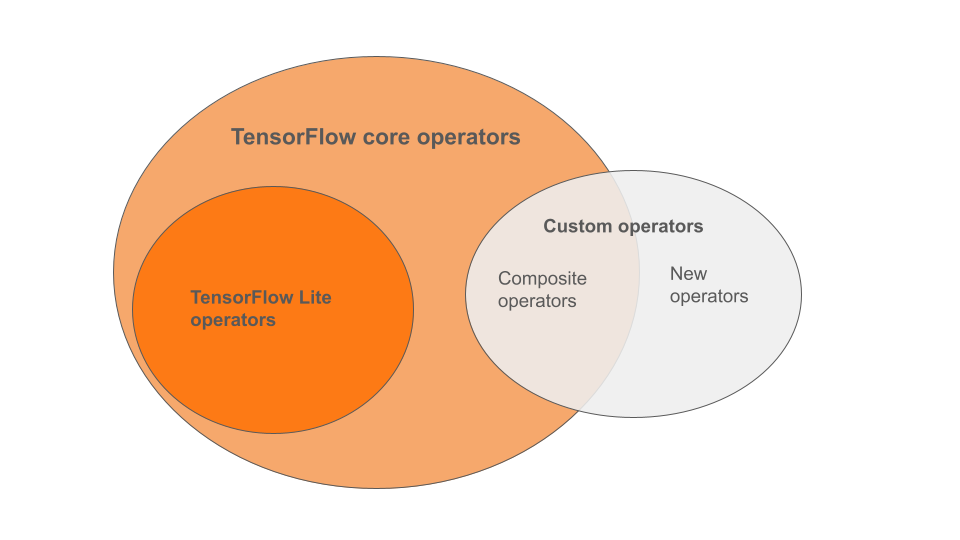
इस रेंज में तीन तरह के एमएल मॉडल ऑपरेटर होते हैं कन्वर्ज़न प्रोसेस के साथ काम करने वाले मॉडल:
- सिर्फ़ LiteRT बिल्ट-इन ऑपरेटर वाले मॉडल. (सुझाया गया)
- पहले से मौजूद ऑपरेटर वाले मॉडल और चुनिंदा TensorFlow कोर ऑपरेटर.
- पहले से मौजूद ऑपरेटर वाले मॉडल, TensorFlow कोर ऑपरेटर, और/या कस्टम ऑपरेटर का इस्तेमाल करें.
अगर आपके मॉडल में सिर्फ़ ऐसे ऑपरेशन हैं जो नेटिव तौर पर LiteRT, उसे बदलने के लिए आपको किसी दूसरे फ़्लैग की ज़रूरत नहीं है. यह का सुझाव दिया गया पथ है क्योंकि इस प्रकार का मॉडल आसानी से रूपांतरित हो जाएगा साथ ही, इसे डिफ़ॉल्ट LiteRT रनटाइम का इस्तेमाल करके ऑप्टिमाइज़ किया जा सकता है और चलाया जा सकता है. आपके पास अपने मॉडल के लिए डिप्लॉयमेंट के ज़्यादा विकल्प भी हैं, जैसे कि Google Play services. Google Ads API का इस्तेमाल करके, LiteRT कन्वर्टर गाइड. यहां जाएं: LiteRT Ops पेज, पहले से मौजूद ऑपरेटर की सूची देखें.
अगर आपको मुख्य लाइब्रेरी से TensorFlow के चुनिंदा ऑपरेशन शामिल करने हैं, तो आपको उसे कन्वर्ज़न के समय तय करना होगा और पक्का करना होगा कि आपके रनटाइम में वे शामिल हों कार्रवाइयां. इसके लिए TensorFlow ऑपरेटर चुनें विषय देखें विस्तृत चरण.
जब भी हो सके, अपने डिवाइस में कस्टम ऑपरेटर शामिल करने के आखिरी विकल्प से बचें बदला गया मॉडल. कस्टम ऑपरेटर या तो एक-दूसरे से कई प्रिमिटिव TensorFlow कोर ऑपरेटर होंगे या पूरी तरह से नया तय करना होगा. जब कस्टम ऑपरेटर कन्वर्ट किए जाते हैं, तो वे यह मॉडल, पहले से मौजूद LiteRT लाइब्रेरी के बाहर डिपेंडेंसी शुरू करके मॉडल का इस्तेमाल करता है. कस्टम ऑपरेशन, अगर खास तौर पर मोबाइल या डिवाइस डिप्लॉयमेंट के लिए नहीं बनाए गए हैं, लागू करने पर, परफ़ॉर्मेंस खराब हो सकती है किसी सर्वर एनवायरमेंट की तुलना में सीमित संसाधन वाले डिवाइस. आखिर में, जिस तरह TensorFlow के चुनिंदा कोर ऑपरेटर को शामिल किया जाता है, उसी तरह कस्टम ऑपरेटर को भी शामिल किया जाता है ज़रूरी है कि मॉडल रनटाइम एनवायरमेंट में बदलाव करना इससे आपको रनटाइम की स्टैंडर्ड सेवाओं का फ़ायदा नहीं मिलता. जैसे, Google Play services.
इस तरह के कोड काम करते हैं
ज़्यादातर LiteRT ऑपरेशन, फ़्लोटिंग-पॉइंट (float32) और, दोनों को टारगेट करते हैं
क्वांटाइज़्ड (uint8, int8) अनुमान, लेकिन कई ऑपरेशन अन्य टाइप के लिए अभी तक उपलब्ध नहीं हैं
जैसे कि tf.float16 और स्ट्रिंग.
ऑपरेशन के अलग-अलग वर्शन का इस्तेमाल करने के अलावा, एक अन्य अंतर फ़्लोटिंग-पॉइंट और क्वांटाइज़्ड मॉडल के बीच कन्वर्ट करने का तरीका होता है. क्वांटाइज़्ड कन्वर्ज़न के लिए टेंसर के लिए डाइनैमिक रेंज की जानकारी की ज़रूरत होती है. यह "नकली-संख्यात्मक विश्लेषण" की ज़रूरत है मॉडल ट्रेनिंग के दौरान, रेंज की जानकारी पाना कैलिब्रेशन डेटा सेट के माध्यम से या "ऑन-द-फ़्लाई" तरीके से रेंज का अनुमान. यहां जाएं: संख्या में देखें.
स्ट्रेट-फ़ॉरवर्ड कन्वर्ज़न, कॉन्स्टेंट-फ़ोल्डिंग, और फ़्यूज़िंग
LiteRT की मदद से, TensorFlow की कई कार्रवाइयां प्रोसेस की जा सकती हैं
हालांकि, वे सीधे तौर पर नहीं मिलते. यह मामला उन कार्रवाइयों का है जो
ग्राफ़ (tf.identity) से हटा दिया जाएगा, उसके स्थान पर टेंसर का इस्तेमाल किया जाएगा
(tf.placeholder), या ज़्यादा जटिल ऑपरेशन (tf.nn.bias_add) में मर्ज किया गया.
कभी-कभी इनमें से किसी एक वजह से, कुछ काम करने वाली कार्रवाइयों को भी हटाया जा सकता है
प्रोसेस.
यहां TensorFlow से जुड़ी कार्रवाइयों की सूची दी गई है, लेकिन पूरी सूची नहीं है. आम तौर पर, इसे हटा दिया जाता है देखें:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
एक्सपेरिमेंट के तौर पर किए जाने वाले ऑपरेशन
यहां LiteRT से जुड़ी कार्रवाइयां मौजूद हैं, लेकिन ये कस्टम ऐक्शन के लिए तैयार नहीं हैं मॉडल:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF