
Operatory systemów uczących się używane w modelu mogą wpływać procesu konwersji z modelu TensorFlow na format LiteRT. Konwerter LiteRT obsługuje ograniczoną liczbę wspólnych operacji TensorFlow modeli wnioskowania, co oznacza, że nie każdy model można bezpośrednio konwertować. Narzędzie konwertera pozwala na dodanie dodatkowych operatorów, ale model w ten sposób wymaga również zmodyfikowania środowiska wykonawczego LiteRT środowiska używanego do wykonywania modelu, co może ograniczać używać standardowych opcji wdrażania w środowisku wykonawczym, takich jak Usługi Google Play.
Narzędzie LiteRT Converter służy do analizowania modelu i optymalizować je, aby zapewnić zgodność bezpośrednio obsługiwanych operatorów. Na przykład w zależności od operatorów ML w Twojego modelu, konwerter może połączyć lub połączyć aby zmapować je na ich odpowiedniki LiteRT.
Nawet w przypadku obsługiwanych operacji można czasami spodziewać się określonych wzorców użytkowania, ze względu na wydajność. Najlepszy sposób na poznanie TensorFlow model, którego można używać z LiteRT polega na starannym rozważaniu sposobu konwertowania operacji oraz ograniczeń nałożonych przez ten proces.
Obsługiwane operatory
Wbudowane operatory LiteRT to podzbiór operatorów które są częścią podstawowej biblioteki TensorFlow. Twój model TensorFlow może mogą też zawierać operatory niestandardowe w postaci operatorów złożonych, lub nowych operatorów zdefiniowanych przez Ciebie. Na diagramie poniżej widać zależności między tymi operatorami.
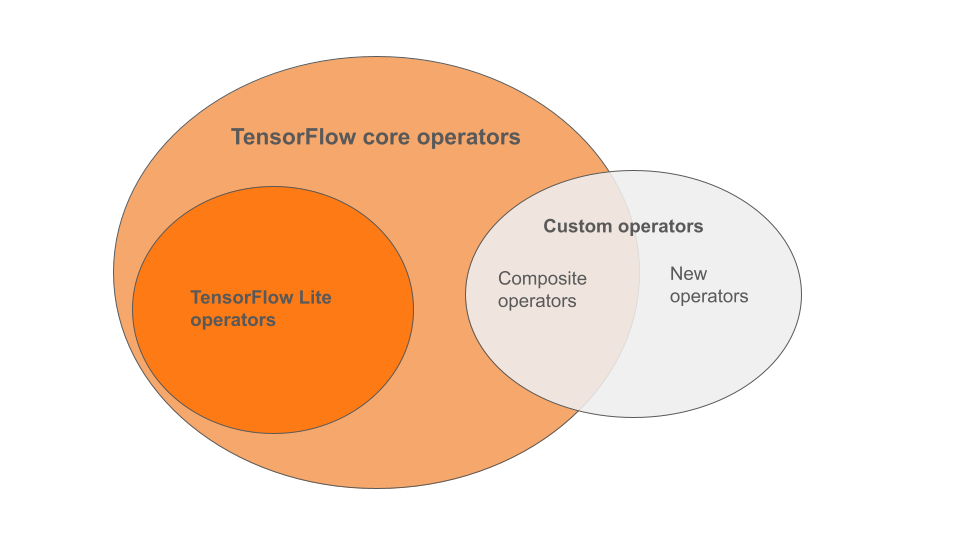
Spośród tego zakresu operatorów modelu ML wyróżniamy 3 typy: modele obsługiwane w procesie konwersji:
- Modele tylko z wbudowanym operatorem LiteRT. (Zalecane)
- Modele z wbudowanymi operatorami i wybraniem TensorFlow operatorzy komórkowi.
- modeli z wbudowanymi operatorami, podstawowych operatorów TensorFlow, z operatorami niestandardowymi.
Jeśli model zawiera tylko operacje, które są natywnie obsługiwane przez LiteRT, do jego konwertowania nie są potrzebne żadne dodatkowe flagi. Ten to zalecana ścieżka, ponieważ ten typ modelu zapewnia płynną konwersję Łatwiej jest też optymalizować i uruchamiać za pomocą domyślnego środowiska wykonawczego LiteRT. Masz też więcej opcji wdrażania dla swojego modelu, takich jak Usługi Google Play. Możesz zacząć od Przewodnik po konwerterach LiteRT Zobacz stronie LiteRT Ops dla z listą wbudowanych operatorów.
Jeśli chcesz wybrać operacje TensorFlow z biblioteki podstawowej, należy to określić podczas konwersji i upewnić się, że środowisko wykonawcze zawiera te operacji. Zapoznaj się z tematem Wybieranie operatorów TensorFlow: ze szczegółowymi instrukcjami.
Gdy tylko jest to możliwe, unikaj ostatniej opcji – dodawania operatorów niestandardowych w parametrach przekonwertowany model. Operatory niestandardowe to operatory utworzone przez połączenie wielu podstawowych operatorów TensorFlow, lub zdefiniować zupełnie nowy. Konwertowanie operatorów niestandardowych może zwiększać ogólną wartość przez naliczanie zależności poza wbudowaną biblioteką LiteRT. Własne operacje, jeśli nie zostały utworzone specjalnie na potrzeby wdrażania na urządzeniach mobilnych lub urządzeniach może pogorszyć wydajność po wdrożeniu w przypadku urządzeń z ograniczonymi zasobami w porównaniu ze środowiskiem serwera. I wreszcie, podobnie jak wybrane podstawowe operatory TensorFlow, operatory niestandardowe wymaga od Ciebie zmodyfikować środowisko wykonawcze modelu co ogranicza możliwość korzystania ze standardowych usług środowiska wykonawczego, takich jak Usług Google Play.
Typy obsługiwane
Większość operacji LiteRT jest kierowana zarówno na liczbę zmiennoprzecinkową (float32), jak i
wnioskowanie kwantyzowane (uint8, int8), ale wiele operacji nie ma jeszcze w przypadku innych typów
takich jak tf.float16 i struny.
Oprócz korzystania z różnych wersji działań druga różnica między modelami zmiennoprzecinkowymi i kwantyzowanymi. Konwersja kwantowa wymaga informacji o zakresie dynamicznym dla tensorów. Ten wymaga „fałszywej kwantyzacji” podczas trenowania modelu, uzyskiwanie informacji o zakresie za pomocą zbioru danych kalibracyjnych lub „na bieżąco” oszacowania zakresu. Zobacz kwantyzacji.
Proste konwersje, stałe składanie i łączenie
LiteRT może przetwarzać wiele operacji TensorFlow, nawet jeśli
chociaż nie mają
bezpośredniego odpowiednika. Dotyczy to operacji, które mogą
zostać po prostu usunięte z grafu (tf.identity), zastąpione tensorami
(tf.placeholder) lub w bardziej złożonych operacjach (tf.nn.bias_add).
Niektóre obsługiwane operacje mogą zostać usunięte przy użyciu tych
Oto niepełna lista operacji TensorFlow, które są zwykle usuwane z wykresu:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operacje eksperymentalne
Istnieją następujące operacje LiteRT, ale nie są gotowe do użycia niestandardowego modele:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF