
Operator machine learning (ML) yang Anda gunakan dalam model dapat memengaruhi proses mengonversi model TensorFlow ke format LiteRT. Konverter LiteRT mendukung sejumlah kecil operasi TensorFlow yang digunakan dalam model inferensi umum, yang berarti tidak semua model dapat dikonversi secara langsung. Alat konverter memungkinkan Anda menyertakan operator tambahan, tetapi mengonversi model dengan cara ini juga mengharuskan Anda mengubah lingkungan runtime LiteRT yang digunakan untuk mengeksekusi model, yang dapat membatasi kemampuan Anda menggunakan opsi deployment runtime standar, seperti layanan Google Play.
LiteRT Converter dirancang untuk menganalisis struktur model dan menerapkan pengoptimalan agar kompatibel dengan operator yang didukung secara langsung. Misalnya, bergantung pada operator ML dalam model Anda, konverter dapat menghilangkan atau menggabungkan operator tersebut untuk memetakannya ke operator LiteRT yang setara.
Bahkan untuk operasi yang didukung, pola penggunaan tertentu terkadang diharapkan, untuk alasan performa. Cara terbaik untuk memahami cara membuat model TensorFlow yang dapat digunakan dengan LiteRT adalah dengan mempertimbangkan secara cermat cara operasi dikonversi dan dioptimalkan, beserta batasan yang diberlakukan oleh proses ini.
Operator yang didukung
Operator bawaan LiteRT adalah subset operator yang merupakan bagian dari library inti TensorFlow. Model TensorFlow Anda juga dapat menyertakan operator kustom dalam bentuk operator komposit atau operator baru yang ditentukan oleh Anda. Diagram di bawah menunjukkan hubungan antara operator ini.
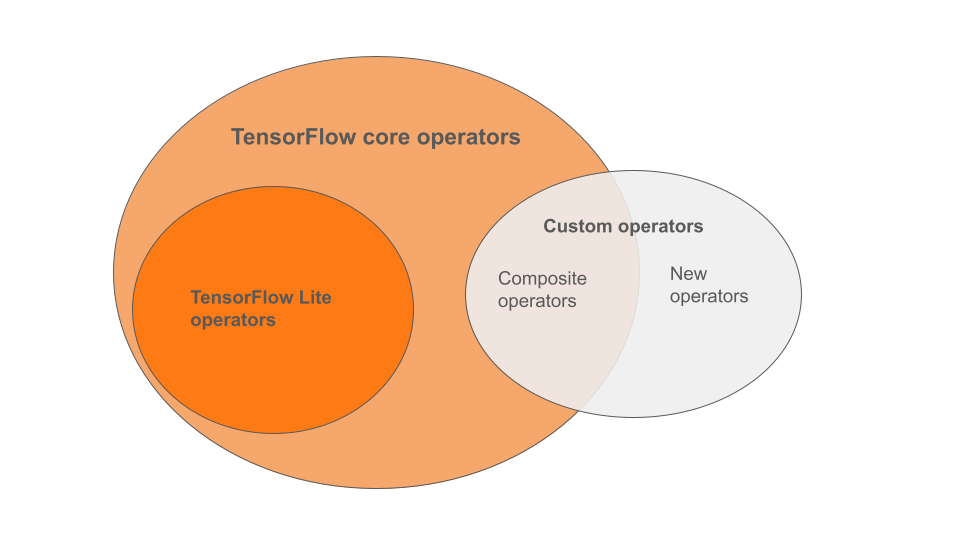
Dari rentang operator model ML ini, ada 3 jenis model yang didukung oleh proses konversi:
- Model dengan operator bawaan LiteRT saja. (Direkomendasikan)
- Model dengan operator bawaan dan operator inti TensorFlow yang dipilih.
- Model dengan operator bawaan, operator inti TensorFlow, dan/atau operator kustom.
Jika model Anda hanya berisi operasi yang didukung secara native oleh LiteRT, Anda tidak memerlukan flag tambahan untuk mengonversinya. Ini adalah jalur yang direkomendasikan karena jenis model ini akan dikonversi dengan lancar dan lebih mudah dioptimalkan serta dijalankan menggunakan runtime LiteRT default. Anda juga memiliki lebih banyak opsi deployment untuk model Anda seperti layanan Google Play. Anda dapat memulai dengan panduan konverter LiteRT. Lihat halaman Operasi LiteRT untuk mengetahui daftar operator bawaan.
Jika Anda perlu menyertakan operasi TensorFlow tertentu dari library inti, Anda harus menentukannya saat konversi dan memastikan runtime Anda menyertakan operasi tersebut. Lihat topik Memilih operator TensorFlow untuk mengetahui langkah-langkah mendetail.
Jika memungkinkan, hindari opsi terakhir untuk menyertakan operator kustom dalam model yang dikonversi. Operator kustom adalah operator yang dibuat dengan menggabungkan beberapa operator inti TensorFlow primitif atau menentukan operator yang benar-benar baru. Saat dikonversi, operator kustom dapat meningkatkan ukuran model secara keseluruhan dengan menimbulkan dependensi di luar library LiteRT bawaan. Operasi kustom, jika tidak dibuat secara khusus untuk deployment perangkat atau seluler, dapat menghasilkan performa yang lebih buruk saat di-deploy ke perangkat dengan resource terbatas dibandingkan dengan lingkungan server. Terakhir, sama seperti menyertakan operator inti TensorFlow tertentu, operator kustom mengharuskan Anda memodifikasi lingkungan runtime model yang membatasi Anda untuk memanfaatkan layanan runtime standar seperti layanan Google Play.
Jenis yang didukung
Sebagian besar operasi LiteRT menargetkan inferensi floating-point (float32) dan terkuantisasi
(uint8, int8), tetapi banyak operasi belum mendukung jenis lain seperti
tf.float16 dan string.
Selain menggunakan versi operasi yang berbeda, perbedaan lain antara model floating-point dan model terkuantisasi adalah cara konversinya. Konversi terkuantisasi memerlukan informasi rentang dinamis untuk tensor. Hal ini memerlukan "fake-quantization" selama pelatihan model, mendapatkan informasi rentang melalui set data kalibrasi, atau melakukan estimasi rentang "langsung". Lihat kuantisasi untuk mengetahui detail selengkapnya.
Konversi langsung, pelipatan dan penggabungan konstan
Sejumlah operasi TensorFlow dapat diproses oleh LiteRT meskipun tidak memiliki padanan langsung. Hal ini berlaku untuk operasi yang dapat dihapus begitu saja dari grafik (tf.identity), diganti dengan tensor (tf.placeholder), atau digabungkan ke dalam operasi yang lebih kompleks (tf.nn.bias_add). Bahkan, beberapa operasi yang didukung terkadang dapat dihapus melalui salah satu proses ini.
Berikut adalah daftar tidak lengkap operasi TensorFlow yang biasanya dihapus dari grafik:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operasi Eksperimental
Operasi LiteRT berikut ada, tetapi belum siap untuk model kustom:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF