
Eğitim sonrası niceleme, model boyutunu azaltabilecek bir dönüşüm tekniğidir CPU ve donanım hızlandırıcı gecikmesini de artırır. azalmaya yol açabilir. Eğitilmiş bir kaymanın miktarını TensorFlow modelini kullanarak LiteRT biçimine dönüştürdüğünüzde LiteRT Dönüştürücüsü.
Optimizasyon Yöntemleri
Aralarından seçim yapabileceğiniz çeşitli eğitim sonrası miktar belirleme seçenekleri vardır. Burada seçimlerin ve sağladıkları avantajların özet tablosunu görebilirsiniz:
| Teknik | Avantajları | Donanım |
|---|---|---|
| Dinamik aralık nicelleştirme | 4 kat daha küçük, 2-3 kat hızlanma | CPU |
| Tam tam sayı nicelleştirme | 4 kat daha küçük, 3 kattan fazla hızlandırma | CPU, Edge TPU, Mikrodenetleyiciler |
| Kayan nokta16 niceliği | 2 kat daha küçük, GPU ivme | CPU, GPU |
Aşağıdaki karar ağacı, hangi eğitim sonrası niceliği belirlemeye yardımcı olabilir örneğin kullanım alanınıza en uygun olanı seçin:
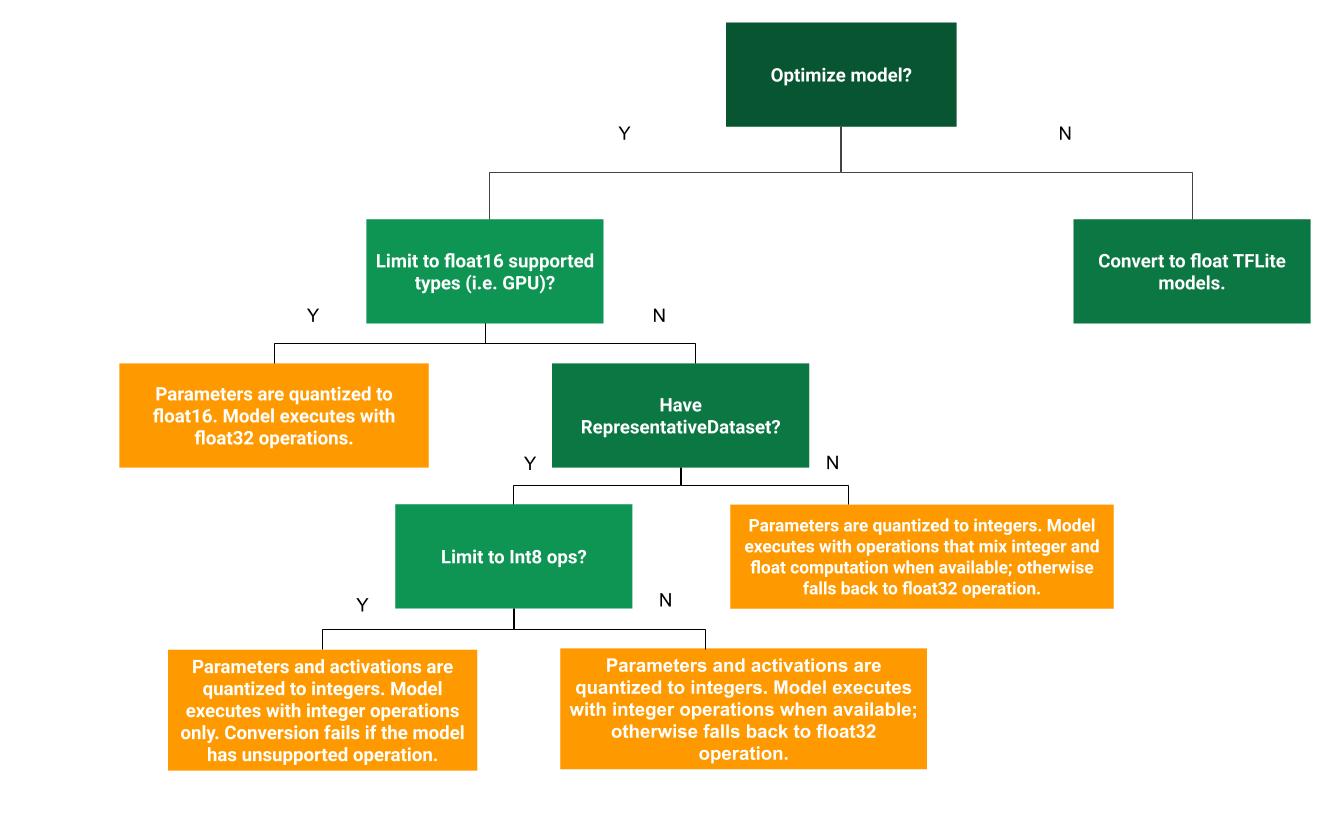
Nicelendirme Yok
Başlangıç olarak miktar belirleme olmadan TFLite modeline dönüştürmeniz önerilir puan. Bu işlem, kayan TFLite modeli oluşturur.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Bunu, orijinal sitenizin mevcut olmadığını doğrulamak için ilk adım olarak yapmanızı öneririz. TF modelinin operatörleri TFLite ile uyumludur ve aynı zamanda bir sonraki eğitim sonrası ölçüm hatalarını ayıklamak için referans yöntem olarak nitelendirilebilir. Örneğin, nicel bir TFLite modeli beklenmedik sonuçlar var, ancak kayan TFLite modeli doğru olsa da, deneme süresini ve TFLite operatörlerinin sayısallaştırılmış sürümünde ortaya çıkan hatalara
Dinamik aralık nicelemesi
Dinamik aralıklı niceleme, daha az bellek kullanımı ve daha hızlı hesaplama sağlar Bu da kalibrasyon için temsili bir veri kümesi sağlamanıza gerek kalmadan yapılır. Bu nicelik türü olarak, yalnızca kayan noktadan alınan ağırlıkları statik olarak ölçer değeri, 8 bit hassasiyet sağlar:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Çıkarım sırasında gecikmeyi daha da azaltmak için "dinamik-aralık" operatörler etkinleştirmeleri 8 bite kadar aralıklarına göre dinamik olarak ölçer ve hesaplamaları için de kullanabilirsiniz. Bu optimizasyon, ve tamamen sabit noktalı çıkarımlara yakın gecikmelerdir. Ancak çıkışlar hâlâ kayan nokta kullanılarak depolanır, böylece dinamik aralıklı işlemlerin artan hızı daha azdır tam sabit noktalı hesaplamaya göre daha belirgindir.
Tam tam sayı niceleme
Gecikme süresinde daha fazla iyileştirme, en yüksek bellek kullanımında azalma ve tamsayı donanım cihazlarıyla veya hızlandırıcılarla uyumluluğun sağlandığından emin olun. tüm model matematiği tam sayıdır.
Tam tamsayı nicelemesi için aralığı kalibre etmeniz veya tahmin etmeniz gerekir.
ör. (min., maks.) olarak ayarlanır. Sabit değerden farklı olarak
ağırlık ve yanlılık gibi tensörler, model girişi gibi değişken tensörler,
etkinleştirmeler (ara katmanların çıkışları) ve model çıkışı
kalibre edilir. Sonuç olarak, dönüştürücü
kalibre etmek için temsili bir veri kümesi gerekir. Bu veri kümesi, çok sayıda
(yaklaşık 100-500 örnek) içeren bir veri kümesi kullanır. Referans
aşağıdaki representative_dataset() işlevini kullanın.
TensorFlow 2.7 sürümünden itibaren, temsili veri kümesini signature (imza) seçeneğini aşağıdaki örnekte görebilirsiniz:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Belirtilen TensorFlow modelinde birden fazla imza varsa imza anahtarlarını belirterek birden çok veri kümesini belirtin:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Bir giriş tensörü listesi sağlayarak temsili veri kümesini oluşturabilirsiniz:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 sürümünden itibaren imza tabanlı yaklaşımı kullanmanızı öneririz. giriş tensörü listesi temelli yaklaşıma kıyasla kolayca çevrilebilir.
Test amacıyla model veri kümesini aşağıdaki gibi kullanabilirsiniz:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Kayan yedekli tam sayı (varsayılan kayan giriş/çıkış kullanılarak)
Bir modelin miktarını tam olarak belirlemek için ancak bir modele tamsayı uygulaması yoksa (dönüşümün sorunsuz bir şekilde gerçekleşmesini sağlamak için) şu adımları uygulayın:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Yalnızca tam sayı
Sadece tamsayılara sahip modeller oluşturmak LiteRT için Mikrodenetleyiciler ve Mercan Edge TPU'lar.
Buna ek olarak, yalnızca tam sayı cihazlarla (ör. 8 bit hızlandırıcıları (ör. Coral Edge TPU) ve hızlandırıcıları (ör. Coral Edge TPU) giriş ve çıkış dahil olmak üzere tüm işlemler için tam tam sayı şu adımları uygulayın:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Kayan nokta16 niceliği
Ağırlıkları nicel olarak ölçerek kayan nokta modelinin boyutunu küçültebilirsiniz. float16, 16 bit kayan nokta sayıları için IEEE standardıdır. Kayma16'yı etkinleştirmek için ağırlıkların niceliğinin belirlenmesi için şu adımları uygulayın:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
bolluk16 nicelemesinin avantajları şunlardır:
- Model boyutunu yarıya kadar küçültür (çünkü tüm ağırlıklar, toplam ağırlığının yarısı orijinal boyut) ekleyebilirsiniz.
- Doğrulukta minimum kayıp yaşanır.
- Çalışabilen bazı yetki verilmiş kullanıcıları (ör. GPU delegesi) destekler doğrudan float16 verileri üzerinde çalışarak float32'ye göre daha hızlı yürütülmesini sağlar hesaplamaları için de geçerlidir.
bolluk16 niceliğinin dezavantajları şunlardır:
- Gecikmeyi sabit noktalı matematiğin nicelemesi kadar azaltmaz.
- Varsayılan olarak, float16 nicelenmiş model ağırlık değerleri çalıştırıldığında float32 olarak ayarlanır. (GPU yetkisi verilen kullanıcının nedeniyle bu ayırma işlemi yapılır.)
Yalnızca tam sayı: 8 bit ağırlıklarla 16 bit etkinleştirmeler (deneysel)
Bu, deneysel bir miktar belirleme şemasıdır. "Yalnızca tamsayı" değerine benzerdir Ancak etkinleştirme işlemleri, 16 bit ve ağırlık aralıklarına göre ölçülür. 8 bitlik bir tam sayıyla, yanlılık ise 64 bitlik tam sayı olarak ölçülür. Bu Buna, 16x8 ölçümlemesi de denir.
Bu ölçümün temel avantajı, doğruluğu daha da artırabilmesidir ancak model boyutunu çok az artırmış olursunuz.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Modeldeki bazı operatörler için 16x8 ölçümleme desteklenmiyorsa ancak desteklenmeyen operatörler hareketli olarak tutuldu. İlgili içeriği oluşturmak için kullanılan buna izin vermek için target_spec'e aşağıdaki seçenek eklenmelidir.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Bu yöntemin doğruluk artışı sağladığı kullanım alanlarına örnekler nicelleştirme şeması şunları içerir:
- çözünürlüğünü artırın
- gürültü giderme ve ışınlama gibi ses sinyali işleme,
- resimdeki parazit giderme,
- Tek bir görüntüden HDR yeniden oluşturma.
Bu hesaplamanın dezavantajı ise şudur:
- Şu anda çıkarım 8 bitlik tam tamsayıya göre belirgin bir şekilde daha yavaştır. optimize edilmiş çekirdek uygulaması yoktur.
- Şu anda mevcut donanım hızlandırmalı TFLite ile uyumlu değil delege ediyor.
Bu miktar belirleme modu için bir eğitici bulabilirsiniz burada bulabilirsiniz.
Model doğruluğu
Ağırlıklar eğitim sonrası ölçüldüğünden, doğruluk kaybı özellikle de küçük ağlarda kullanabilirsiniz. Önceden eğitilmiş tamamen miktarlandırılmış modeller Kaggle'daki belirli ağlar için sağlanır Modeller , Projenin başarılı bir şekilde gerçekleştirildiğini doğrulamak için nicelleştirilmiş modelin doğruluktaki herhangi bir düşüş kabul edilebilir sınırlar dahilindedir. Paydaşlarla yapacağınız LiteRT modelini değerlendir doğruluk oranı.
Alternatif olarak, doğruluk düşüşü çok yüksekse nicel analiz veya farkında eğitim , Ancak bunu yapmak, model eğitimi sırasında sahte etiket ekleme düğümleri belirlemekte, bu örnekte ise eğitim sonrası mevcut bir önceden eğitilmiş modeli kullandığını fark edeceksiniz.
Nicel tensörlerin temsili
8 bitlik niceleme, aşağıdakini kullanarak kayan nokta değerlerini tahmin eder: formülünü kullanabilirsiniz.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Temsilin iki ana bölümü vardır:
Eksen başına (kanal başına) veya tensör başına ağırlıklar iki noktalı [-127, 127] aralığındaki tamamlayıcı değerleri içerir ve sıfır noktası 0'a eşit olur.
tensör başına etkinleştirmeler/girişler [-128, 127] aralığında sıfır noktasıyla [-128, 127] aralığı.
Nicelendirme şemamızın ayrıntılı bir görünümü için lütfen nicelendirme şemamıza spesifikasyonlarını inceleyin. TensorFlow'a bağlanmak isteyen donanım tedarikçileri Lite'ın delege arayüzünün nicelik şemasını uygulaması önerilir. açıklayacağım.