
Lượng tử hoá sau huấn luyện là một kỹ thuật chuyển đổi có thể làm giảm kích thước mô hình đồng thời cải thiện được độ trễ của CPU và phần cứng, suy giảm độ chính xác của mô hình. Bạn có thể lượng tử hoá một số thực đã được huấn luyện Mô hình TensorFlow khi bạn chuyển đổi sang định dạng LiteRT bằng phương thức Trình chuyển đổi LiteRT.
Phương pháp tối ưu hoá
Có một số cách định lượng sau khi đào tạo. Dưới đây là bảng tóm tắt các lựa chọn và lợi ích mà các lựa chọn đó mang lại:
| Kỹ thuật | Lợi ích | Phần cứng |
|---|---|---|
| Dải động lượng tử hoá | Nhỏ hơn 4 lần, tăng tốc 2x-3 lần | CPU |
| Số nguyên đầy đủ lượng tử hoá | Nhỏ hơn 4 lần, tăng tốc hơn 3 lần | CPU, TPU cạnh, Vi điều khiển |
| Định lượng Float16 | GPU, nhỏ hơn 2 lần gia tốc | CPU, GPU |
Cây quyết định sau đây có thể giúp xác định lượng tử hoá sau huấn luyện là phương pháp phù hợp nhất cho trường hợp sử dụng của bạn:
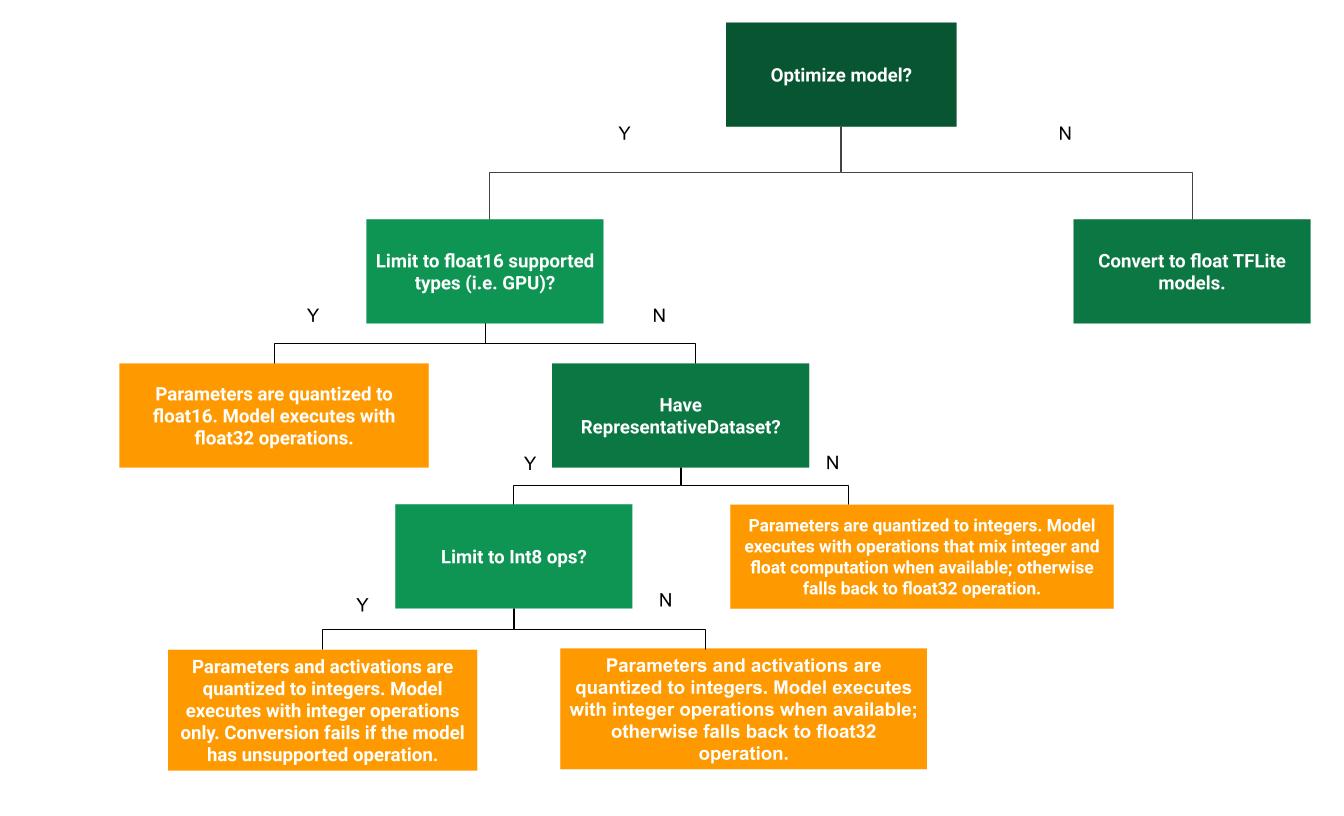
Không định lượng
Bạn nên bắt đầu chuyển đổi sang mô hình TFLite mà không cần lượng tử hoá điểm. Thao tác này sẽ tạo một mô hình TFLite nổi.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Bạn nên thực hiện bước này ở bước đầu tiên để xác minh rằng Các toán tử của mô hình TF tương thích với TFLite và cũng có thể được dùng làm đường cơ sở để gỡ lỗi lượng tử hoá được đưa ra sau quá trình huấn luyện tiếp theo phương pháp lượng tử. Ví dụ: nếu mô hình TFLite lượng tử hoá tạo ra kết quả không mong muốn, trong khi mô hình TFLite nổi là chính xác, chúng ta có thể thu hẹp vấn đề xảy ra với các lỗi được tạo ra bởi phiên bản lượng tử hoá của toán tử TFLite.
Lượng tử hoá dải động
Lượng tử hoá phạm vi động giúp giảm mức sử dụng bộ nhớ và tính toán nhanh hơn mà không cần phải cung cấp tập dữ liệu đại diện để lấy mẫu. Chiến dịch này loại lượng tử hoá, chỉ lượng tử hoá tĩnh các trọng số từ dấu phẩy động thành số nguyên tại thời điểm chuyển đổi, cung cấp độ chính xác 8 bit:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Để giảm thêm độ trễ trong quá trình suy luận, "phạm vi động" toán tử lượng tử hoá các kích hoạt một cách linh động dựa trên phạm vi của chúng đến 8 bit và thực hiện các phép tính với trọng số 8 bit và các phép kích hoạt. Tối ưu hoá này cung cấp độ trễ gần với suy luận điểm cố định hoàn toàn. Tuy nhiên, dữ liệu đầu ra vẫn được lưu trữ bằng dấu phẩy động, nên tốc độ tăng của hoạt động dải động sẽ ít hơn so với một phép tính điểm cố định hoàn toàn.
Lượng tử hoá số nguyên đầy đủ
Bạn có thể cải thiện thêm độ trễ, giảm mức sử dụng bộ nhớ cao nhất và khả năng tương thích với các thiết bị phần cứng hoặc trình tăng tốc chỉ chứa số nguyên tất cả toán học mô hình đều được lượng tử hoá số nguyên.
Để lượng tử hoá số nguyên đầy đủ, bạn cần hiệu chỉnh hoặc ước tính phạm vi,
ví dụ: (tối thiểu, tối đa) của tất cả tensor dấu phẩy động trong mô hình. Không giống như hằng số
tensor như trọng số và độ chệch, các tensor biến đổi như đầu vào mô hình,
không thể kích hoạt (đầu ra của lớp trung gian) và đầu ra của mô hình
được hiệu chỉnh trừ khi chúng tôi chạy một vài chu kỳ suy luận. Kết quả là, trình chuyển đổi
cần có một tập dữ liệu đại diện để hiệu chỉnh chúng. Tập dữ liệu này có thể là
một nhóm nhỏ (khoảng 100-500 mẫu) của dữ liệu huấn luyện hoặc xác thực. Tham khảo
hàm representative_dataset() bên dưới.
Từ phiên bản TensorFlow 2.7, bạn có thể chỉ định tập dữ liệu đại diện thông qua signature như ví dụ sau:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Nếu có nhiều chữ ký trong mô hình TensorFlow cho trước, bạn có thể chỉ định nhiều tập dữ liệu bằng cách chỉ định khoá chữ ký:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Bạn có thể tạo tập dữ liệu đại diện bằng cách cung cấp danh sách tensor đầu vào:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Kể từ phiên bản TensorFlow 2.7, bạn nên sử dụng phương pháp dựa trên chữ ký so với cách tiếp cận dựa trên danh sách tensor đầu vào vì thứ tự tensor đầu vào có thể có thể dễ dàng lật ngược.
Để thử nghiệm, bạn có thể sử dụng một tập dữ liệu giả như sau:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Số nguyên có số thực có độ chính xác đơn dự phòng (sử dụng dữ liệu đầu vào/đầu ra số thực mặc định)
Để định lượng hoàn toàn một mô hình số nguyên, nhưng hãy sử dụng các toán tử độ chính xác đơn khi không triển khai số nguyên (để đảm bảo quá trình chuyển đổi diễn ra suôn sẻ), hãy sử dụng các bước sau:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Chỉ số nguyên
Tạo mô hình chỉ số nguyên là một trường hợp sử dụng phổ biến đối với LiteRT cho Vi điều khiển và san hô TPU cạnh tranh.
Ngoài ra, để đảm bảo khả năng tương thích với các thiết bị chỉ dùng số nguyên (chẳng hạn như 8 bit) bộ vi điều khiển) và trình tăng tốc (chẳng hạn như TPU San hô san hô), bạn có thể thực thi lượng tử hoá số nguyên đầy đủ cho tất cả hoạt động, bao gồm cả đầu vào và đầu ra, bằng cách sử dụng các bước sau:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Định lượng Float16
Bạn có thể giảm kích thước của mô hình dấu phẩy động bằng cách lượng tử hoá trọng số thành float16 là tiêu chuẩn IEEE cho các số có dấu phẩy động 16 bit. Cách bật float16 lượng tử hoá trọng số, hãy sử dụng các bước sau:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Sau đây là các ưu điểm của phương pháp lượng tử float16:
- Giúp giảm kích thước mô hình xuống tới một nửa (vì tất cả trọng số đều trở thành một nửa kích thước của mô hình kích thước gốc).
- Điều này làm giảm độ chính xác ở mức tối thiểu.
- Lớp này hỗ trợ một số đại biểu (ví dụ: uỷ quyền GPU) có thể hoạt động trực tiếp trên dữ liệu float16, dẫn đến việc thực thi nhanh hơn float32 các phép tính.
Nhược điểm của phương pháp lượng tử hoá float16 như sau:
- Nó không làm giảm độ trễ nhiều như việc lượng tử hoá cho phép toán điểm cố định.
- Theo mặc định, mô hình lượng tử hoá float16 sẽ "loại bỏ lượng tử" giá trị trọng số thành float32 khi chạy trên CPU. (Lưu ý rằng việc uỷ quyền GPU sẽ không hoạt động loại bỏ lượng tử này, vì nó có thể hoạt động trên dữ liệu float16.)
Chỉ số nguyên: Kích hoạt 16 bit với trọng số 8 bit (thử nghiệm)
Đây là một lược đồ lượng tử thử nghiệm. Nó tương tự như "chỉ số nguyên" nhưng các hoạt động kích hoạt được lượng tử hoá dựa trên phạm vi của chúng đến 16 bit, trọng số được lượng tử hoá trong số nguyên 8 bit và độ chệch được lượng tử hoá thành số nguyên 64 bit. Chiến dịch này được gọi là lượng tử hoá 16x8.
Ưu điểm chính của phương pháp lượng tử hoá này là có thể cải thiện độ chính xác đáng kể nhưng chỉ tăng nhẹ kích thước mô hình.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Nếu lượng tử hoá 16x8 không được hỗ trợ cho một số toán tử trong mô hình này thì mô hình vẫn có thể lượng tử hoá được, nhưng các toán tử không được hỗ trợ sẽ được giữ ở dạng số thực. Chiến lược phát hành đĩa đơn bạn nên thêm tùy chọn sau vào target_spec để cho phép điều này.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Ví dụ về các trường hợp sử dụng mà trong đó sơ đồ lượng tử hoá bao gồm:
- độ phân giải siêu cao,
- xử lý tín hiệu âm thanh như khử tiếng ồn và tạo tia sáng,
- khử nhiễu cho hình ảnh,
- Tái tạo HDR từ một hình ảnh duy nhất.
Nhược điểm của cách lượng tử hoá này là:
- Hiện tại, suy luận chậm hơn đáng kể so với số nguyên đầy đủ 8 bit do thiếu cách triển khai nhân tối ưu hoá.
- Hiện tại, ứng dụng này không tương thích với TFLite tăng tốc phần cứng hiện có đại biểu.
Bạn có thể xem hướng dẫn cho chế độ lượng tử hoá này tại đây.
Độ chính xác của mô hình
Vì trọng số được định lượng sau khi huấn luyện, nên có thể sẽ có tình trạng mất độ chính xác, đặc biệt đối với các mạng nhỏ hơn. Các mô hình lượng tử hoá hoàn toàn được huấn luyện trước là được cung cấp cho các mạng truyền hình cụ thể trên Kaggle Mẫu sản phẩm của Google. Cần phải kiểm tra độ chính xác của mô hình lượng tử hoá để xác minh rằng mọi suy giảm độ chính xác đều nằm trong giới hạn có thể chấp nhận. Có các công cụ để đánh giá mô hình LiteRT .
Ngoài ra, nếu độ chính xác giảm quá cao, hãy cân nhắc sử dụng phương pháp lượng tử hoá biết đào tạo của Google. Tuy nhiên, làm như vậy yêu cầu sửa đổi trong quá trình huấn luyện mô hình để thêm giá trị giả các nút lượng tử hoá, trong khi các kỹ thuật lượng tử hoá sau đào tạo sử dụng mô hình được huấn luyện trước hiện có.
Biểu diễn tensor lượng tử hoá
Lượng tử hoá 8 bit ước lượng giá trị dấu phẩy động bằng cách sử dụng .
\[real\_value = (int8\_value - zero\_point) \times scale\]
Nội dung trình bày này có hai phần chính:
Trọng số trên mỗi trục (còn gọi là mỗi kênh) hoặc trọng số trên mỗi tensor được biểu thị bằng các giá trị bù trong khoảng [-127, 127] với điểm 0 bằng 0.
Số liệu kích hoạt/đầu vào trên mỗi tensor được biểu thị bằng các giá trị bổ sung của int8 hai trong phạm vi [-128, 127], với điểm không trong phạm vi [-128, 127].
Để có cái nhìn chi tiết về chương trình lượng tử của chúng tôi, vui lòng xem bài viết lượng tử hoá . Những nhà cung cấp phần cứng muốn sử dụng TensorFlow Giao diện uỷ quyền của Lite được khuyến khích triển khai lược đồ lượng tử hoá được mô tả ở đó.