
প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন হল একটি রূপান্তর কৌশল যা মডেলের আকার কমাতে পারে এবং একই সাথে CPU এবং হার্ডওয়্যার অ্যাক্সিলারেটর ল্যাটেন্সি উন্নত করতে পারে, মডেলের নির্ভুলতায় সামান্য অবনতি ঘটে। LiteRT কনভার্টার ব্যবহার করে LiteRT ফর্ম্যাটে রূপান্তর করার সময় আপনি ইতিমধ্যেই প্রশিক্ষিত ফ্লোট টেনসরফ্লো মডেলের কোয়ান্টাইজেশন করতে পারেন।
অপ্টিমাইজেশন পদ্ধতি
প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশনের জন্য বেশ কয়েকটি বিকল্প রয়েছে যা থেকে বেছে নেওয়া যেতে পারে। এখানে পছন্দগুলি এবং সেগুলি থেকে প্রাপ্ত সুবিধাগুলির একটি সারসংক্ষেপ রয়েছে:
| কৌশল | সুবিধা | হার্ডওয়্যার |
|---|---|---|
| গতিশীল পরিসরের পরিমাণ নির্ধারণ | ৪ গুণ ছোট, ২-৩ গুণ গতি বৃদ্ধি | সিপিইউ |
| পূর্ণ পূর্ণসংখ্যার পরিমাণ নির্ধারণ | ৪ গুণ ছোট, ৩ গুণ বেশি গতি বৃদ্ধি | সিপিইউ, এজ টিপিইউ, মাইক্রোকন্ট্রোলার |
| Float16 কোয়ান্টাইজেশন | ২ গুণ ছোট, জিপিইউ ত্বরণ | সিপিইউ, জিপিইউ |
নিম্নলিখিত সিদ্ধান্ত বৃক্ষটি আপনার ব্যবহারের ক্ষেত্রে প্রশিক্ষণ-পরবর্তী কোন কোয়ান্টাইজেশন পদ্ধতিটি সবচেয়ে ভালো তা নির্ধারণ করতে সাহায্য করতে পারে:
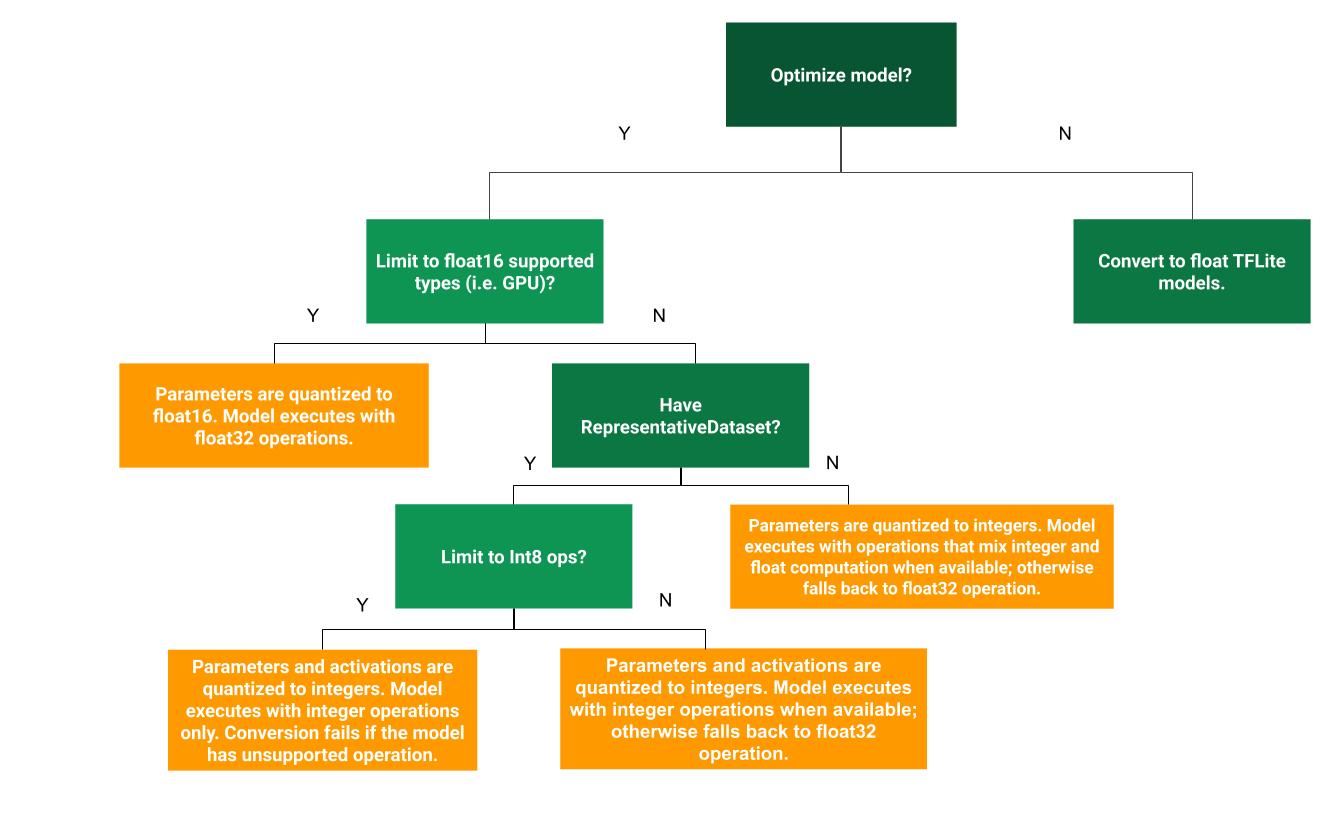
কোন পরিমাণ নির্ধারণ নেই
কোয়ান্টাইজেশন ছাড়াই একটি TFLite মডেলে রূপান্তর করা একটি প্রস্তাবিত সূচনা বিন্দু। এটি একটি ফ্লোট TFLite মডেল তৈরি করবে।
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
আমরা সুপারিশ করছি যে আপনি এটি প্রাথমিক পদক্ষেপ হিসেবে করুন যাতে নিশ্চিত করা যায় যে মূল TF মডেলের অপারেটরগুলি TFLite-এর সাথে সামঞ্জস্যপূর্ণ এবং পরবর্তী প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন পদ্ধতি দ্বারা প্রবর্তিত কোয়ান্টাইজেশন ত্রুটিগুলি ডিবাগ করার জন্য এটি একটি বেসলাইন হিসাবেও ব্যবহার করা যেতে পারে। উদাহরণস্বরূপ, যদি একটি কোয়ান্টাইজড TFLite মডেল অপ্রত্যাশিত ফলাফল তৈরি করে, যখন ফ্লোট TFLite মডেলটি সঠিক হয়, তাহলে আমরা সমস্যাটিকে TFLite অপারেটরগুলির কোয়ান্টাইজড সংস্করণ দ্বারা প্রবর্তিত ত্রুটিগুলিতে সীমাবদ্ধ করতে পারি।
গতিশীল পরিসরের পরিমাণ নির্ধারণ
ডায়নামিক রেঞ্জ কোয়ান্টাইজেশন মেমোরির ব্যবহার কমিয়ে দেয় এবং দ্রুত গণনা করে, ক্যালিব্রেশনের জন্য একটি প্রতিনিধিত্বমূলক ডেটাসেট সরবরাহ না করেই। এই ধরণের কোয়ান্টাইজেশন, রূপান্তরের সময় শুধুমাত্র ভাসমান বিন্দু থেকে পূর্ণসংখ্যা পর্যন্ত ওজনগুলিকে স্ট্যাটিকভাবে কোয়ান্টাইজ করে, যা 8-বিট নির্ভুলতা প্রদান করে:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
ইনফারেন্সের সময় ল্যাটেন্সি আরও কমাতে, "ডায়নামিক-রেঞ্জ" অপারেটররা তাদের রেঞ্জের উপর ভিত্তি করে অ্যাক্টিভেশনগুলিকে গতিশীলভাবে 8-বিটে কোয়ান্টাইজ করে এবং 8-বিট ওজন এবং অ্যাক্টিভেশনের মাধ্যমে গণনা সম্পাদন করে। এই অপ্টিমাইজেশন সম্পূর্ণ স্থির-পয়েন্ট ইনফারেন্সের কাছাকাছি ল্যাটেন্সি প্রদান করে। যাইহোক, আউটপুটগুলি এখনও ফ্লোটিং পয়েন্ট ব্যবহার করে সংরক্ষণ করা হয় তাই ডায়নামিক-রেঞ্জ অপশনের বর্ধিত গতি সম্পূর্ণ স্থির-পয়েন্ট গণনার চেয়ে কম।
পূর্ণ পূর্ণসংখ্যার পরিমাণ নির্ধারণ
সমস্ত মডেল গণিত পূর্ণসংখ্যার কোয়ান্টাইজড কিনা তা নিশ্চিত করে আপনি আরও ল্যাটেন্সি উন্নতি, সর্বোচ্চ মেমোরি ব্যবহার হ্রাস এবং কেবল পূর্ণসংখ্যার হার্ডওয়্যার ডিভাইস বা অ্যাক্সিলারেটরের সাথে সামঞ্জস্য পেতে পারেন।
পূর্ণ পূর্ণসংখ্যার কোয়ান্টাইজেশনের জন্য, আপনাকে মডেলের সমস্ত ভাসমান-বিন্দু টেনসরের পরিসর, অর্থাৎ (সর্বনিম্ন, সর্বোচ্চ) ক্যালিব্রেট বা অনুমান করতে হবে। ওজন এবং পক্ষপাতের মতো ধ্রুবক টেনসরের বিপরীতে, মডেল ইনপুট, অ্যাক্টিভেশন (মধ্যবর্তী স্তরের আউটপুট) এবং মডেল আউটপুটের মতো পরিবর্তনশীল টেনসরগুলিকে ক্যালিব্রেট করা যাবে না যদি না আমরা কয়েকটি ইনফারেন্স চক্র চালাই। ফলস্বরূপ, কনভার্টারকে ক্যালিব্রেট করার জন্য একটি প্রতিনিধি ডেটাসেটের প্রয়োজন হয়। এই ডেটাসেটটি প্রশিক্ষণ বা বৈধতা ডেটার একটি ছোট উপসেট (প্রায় ~100-500 নমুনা) হতে পারে। নীচের representative_dataset() ফাংশনটি দেখুন।
TensorFlow 2.7 সংস্করণ থেকে, আপনি নিম্নলিখিত উদাহরণ হিসাবে একটি স্বাক্ষরের মাধ্যমে প্রতিনিধি ডেটাসেট নির্দিষ্ট করতে পারেন:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
যদি প্রদত্ত TensorFlow মডেলে একাধিক স্বাক্ষর থাকে, তাহলে আপনি স্বাক্ষর কীগুলি নির্দিষ্ট করে একাধিক ডেটাসেট নির্দিষ্ট করতে পারেন:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
আপনি একটি ইনপুট টেনসর তালিকা প্রদান করে প্রতিনিধিত্বমূলক ডেটাসেট তৈরি করতে পারেন:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 সংস্করণ থেকে, আমরা ইনপুট টেনসর তালিকা-ভিত্তিক পদ্ধতির পরিবর্তে স্বাক্ষর-ভিত্তিক পদ্ধতি ব্যবহার করার পরামর্শ দিচ্ছি কারণ ইনপুট টেনসর ক্রম সহজেই উল্টানো যেতে পারে।
পরীক্ষার উদ্দেশ্যে, আপনি নিম্নরূপ একটি ডামি ডেটাসেট ব্যবহার করতে পারেন:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
ফ্লোট ফলব্যাক সহ পূর্ণসংখ্যা (ডিফল্ট ফ্লোট ইনপুট/আউটপুট ব্যবহার করে)
একটি মডেলকে সম্পূর্ণরূপে পূর্ণসংখ্যার কোয়ান্টাইজ করার জন্য, কিন্তু যখন তাদের পূর্ণসংখ্যা বাস্তবায়ন না থাকে তখন ফ্লোট অপারেটর ব্যবহার করার জন্য (রূপান্তরটি সুষ্ঠুভাবে সম্পন্ন হয় তা নিশ্চিত করার জন্য), নিম্নলিখিত পদক্ষেপগুলি ব্যবহার করুন:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
শুধুমাত্র পূর্ণসংখ্যা
মাইক্রোকন্ট্রোলার এবং কোরাল এজ টিপিইউ- এর জন্য LiterRT- এর একটি সাধারণ ব্যবহারের ক্ষেত্রে কেবল পূর্ণসংখ্যা মডেল তৈরি করা।
অতিরিক্তভাবে, শুধুমাত্র পূর্ণসংখ্যা ডিভাইস (যেমন 8-বিট মাইক্রোকন্ট্রোলার) এবং অ্যাক্সিলারেটর (যেমন কোরাল এজ টিপিইউ) এর সাথে সামঞ্জস্য নিশ্চিত করতে, আপনি নিম্নলিখিত পদক্ষেপগুলি ব্যবহার করে ইনপুট এবং আউটপুট সহ সমস্ত অপারেশনের জন্য পূর্ণ পূর্ণসংখ্যা কোয়ান্টাইজেশন প্রয়োগ করতে পারেন:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 কোয়ান্টাইজেশন
আপনি একটি ফ্লোটিং পয়েন্ট মডেলের আকার কমাতে পারেন ওজনকে float16 এ কোয়ান্টাইজ করে, যা 16-বিট ফ্লোটিং পয়েন্ট সংখ্যার জন্য IEEE স্ট্যান্ডার্ড। ওজনের float16 কোয়ান্টাইজেশন সক্ষম করতে, নিম্নলিখিত পদক্ষেপগুলি ব্যবহার করুন:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 কোয়ান্টাইজেশনের সুবিধাগুলি নিম্নরূপ:
- এটি মডেলের আকার অর্ধেক পর্যন্ত কমিয়ে দেয় (যেহেতু সমস্ত ওজন তাদের মূল আকারের অর্ধেক হয়ে যায়)।
- এটি নির্ভুলতার ক্ষেত্রে ন্যূনতম ক্ষতি করে।
- এটি কিছু ডেলিগেট (যেমন GPU ডেলিগেট) সমর্থন করে যা সরাসরি float16 ডেটাতে কাজ করতে পারে, যার ফলে float32 কম্পিউটেশনের তুলনায় দ্রুত এক্সিকিউশন হয়।
float16 কোয়ান্টাইজেশনের অসুবিধাগুলি নিম্নরূপ:
- এটি স্থির বিন্দু গণিতে কোয়ান্টাইজেশনের মতো বিলম্বিতা কমায় না।
- ডিফল্টরূপে, একটি float16 কোয়ান্টাইজড মডেল CPU-তে চালানোর সময় ওজনের মানগুলিকে float32-তে "dequantize" করবে। (মনে রাখবেন যে GPU ডেলিগেট এই dequantization সম্পাদন করবে না, কারণ এটি float16 ডেটাতে কাজ করতে পারে।)
শুধুমাত্র পূর্ণসংখ্যা: ৮-বিট ওজন সহ ১৬-বিট সক্রিয়করণ (পরীক্ষামূলক)
এটি একটি পরীক্ষামূলক কোয়ান্টাইজেশন স্কিম। এটি "শুধুমাত্র পূর্ণসংখ্যা" স্কিমের অনুরূপ, তবে অ্যাক্টিভেশনগুলিকে তাদের পরিসরের উপর ভিত্তি করে 16-বিটে কোয়ান্টাইজ করা হয়, ওজন 8-বিট পূর্ণসংখ্যায় কোয়ান্টাইজ করা হয় এবং বায়াসকে 64-বিট পূর্ণসংখ্যায় কোয়ান্টাইজ করা হয়। এটিকে আরও 16x8 কোয়ান্টাইজেশন বলা হয়।
এই কোয়ান্টাইজেশনের প্রধান সুবিধা হল এটি নির্ভুলতা উল্লেখযোগ্যভাবে উন্নত করতে পারে, তবে মডেলের আকার সামান্যই বৃদ্ধি করতে পারে।
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
যদি মডেলের কিছু অপারেটরের জন্য 16x8 কোয়ান্টাইজেশন সমর্থিত না হয়, তাহলেও মডেলটি কোয়ান্টাইজ করা যেতে পারে, কিন্তু অসমর্থিত অপারেটরগুলিকে ফ্লোটে রাখা যেতে পারে। এটি করার জন্য target_spec-এ নিম্নলিখিত বিকল্পটি যোগ করা উচিত।
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
এই কোয়ান্টাইজেশন স্কিম দ্বারা প্রদত্ত নির্ভুলতার উন্নতির ক্ষেত্রে ব্যবহারের উদাহরণগুলির মধ্যে রয়েছে:
- অতি-রেজোলিউশন,
- শব্দ বাতিলকরণ এবং বিমফর্মিংয়ের মতো অডিও সিগন্যাল প্রক্রিয়াকরণ,
- ছবির শব্দ নিরোধক,
- একটি একক ছবি থেকে HDR পুনর্গঠন।
এই পরিমাণ নির্ধারণের অসুবিধা হল:
- বর্তমানে অপ্টিমাইজড কার্নেল বাস্তবায়নের অভাবের কারণে অনুমান 8-বিট পূর্ণ পূর্ণসংখ্যার তুলনায় লক্ষণীয়ভাবে ধীর।
- বর্তমানে এটি বিদ্যমান হার্ডওয়্যার অ্যাক্সিলারেটেড TFLite ডেলিগেটগুলির সাথে বেমানান।
এই কোয়ান্টাইজেশন মোডের জন্য একটি টিউটোরিয়াল এখানে পাওয়া যাবে।
মডেলের নির্ভুলতা
যেহেতু প্রশিক্ষণের পরে ওজন পরিমাপ করা হয়, তাই নির্ভুলতা হ্রাস পেতে পারে, বিশেষ করে ছোট নেটওয়ার্কগুলির জন্য। Kaggle মডেলগুলিতে নির্দিষ্ট নেটওয়ার্কগুলির জন্য পূর্ব-প্রশিক্ষিত সম্পূর্ণরূপে পরিমাপ করা মডেল সরবরাহ করা হয়। নির্ভুলতার কোনও অবনতি গ্রহণযোগ্য সীমার মধ্যে আছে কিনা তা যাচাই করার জন্য পরিমাপ করা মডেলের নির্ভুলতা পরীক্ষা করা গুরুত্বপূর্ণ। LiterRT মডেলের নির্ভুলতা মূল্যায়নের জন্য সরঞ্জাম রয়েছে।
বিকল্পভাবে, যদি নির্ভুলতা হ্রাস খুব বেশি হয়, তাহলে কোয়ান্টাইজেশন সচেতন প্রশিক্ষণ ব্যবহার করার কথা বিবেচনা করুন। তবে, এটি করার জন্য মডেল প্রশিক্ষণের সময় নকল কোয়ান্টাইজেশন নোড যোগ করার জন্য পরিবর্তন প্রয়োজন, যেখানে এই পৃষ্ঠায় প্রশিক্ষণ-পরবর্তী কোয়ান্টাইজেশন কৌশলগুলি একটি বিদ্যমান পূর্ব-প্রশিক্ষিত মডেল ব্যবহার করে।
কোয়ান্টাইজড টেনসরের প্রতিনিধিত্ব
৮-বিট কোয়ান্টাইজেশন নিম্নলিখিত সূত্র ব্যবহার করে ভাসমান বিন্দুর মানগুলির আনুমানিক হিসাব করে।
\[real\_value = (int8\_value - zero\_point) \times scale\]
উপস্থাপনার দুটি প্রধান অংশ রয়েছে:
প্রতি-অক্ষ (ওরফে প্রতি-চ্যানেল) অথবা প্রতি-টেনসরের ওজন, int8 টু-এর পরিপূরক মান দ্বারা প্রতিনিধিত্ব করা হয় [-127, 127] পরিসরে যেখানে শূন্য-বিন্দু 0 এর সমান।
[-128, 127] পরিসরে int8 টু-এর পরিপূরক মান দ্বারা প্রতিনিধিত্ব করা প্রতি-টেনসর সক্রিয়করণ/ইনপুট, যেখানে [-128, 127] পরিসরে শূন্য-বিন্দু রয়েছে।
আমাদের কোয়ান্টাইজেশন স্কিমের বিস্তারিত জানার জন্য, অনুগ্রহ করে আমাদের কোয়ান্টাইজেশন স্পেক দেখুন। যেসব হার্ডওয়্যার বিক্রেতারা TensorFlow Lite এর ডেলিগেট ইন্টারফেসে প্লাগ ইন করতে চান তাদের সেখানে বর্ণিত কোয়ান্টাইজেশন স্কিম বাস্তবায়নের জন্য উৎসাহিত করা হচ্ছে।