
La cuantización posterior al entrenamiento es una técnica de conversión que puede reducir el tamaño del modelo y, al mismo tiempo, mejorar la latencia de aceleración de CPU y hardware, con poca degradación en la exactitud del modelo. Puedes cuantificar un modelo de TensorFlow de punto flotante ya entrenado cuando lo conviertes al formato de LiteRT con el conversor de LiteRT.
Métodos de optimización
Hay varias opciones de cuantización posterior al entrenamiento para elegir. A continuación, se incluye una tabla de resumen de las opciones y los beneficios que proporcionan:
| Técnica | Beneficios | Hardware |
|---|---|---|
| Cuantificación del rango dinámico | 4 veces más pequeño y de 2 a 3 veces más rápido | CPU |
| Cuantización de números enteros | 4 veces más pequeño y 3 veces más rápido | CPU, Edge TPU y microcontroladores |
| Cuantización de Float16 | 2 veces más pequeño, aceleración por GPU | CPU, GPU |
El siguiente árbol de decisión puede ayudarte a determinar qué método de cuantización posterior al entrenamiento es mejor para tu caso de uso:
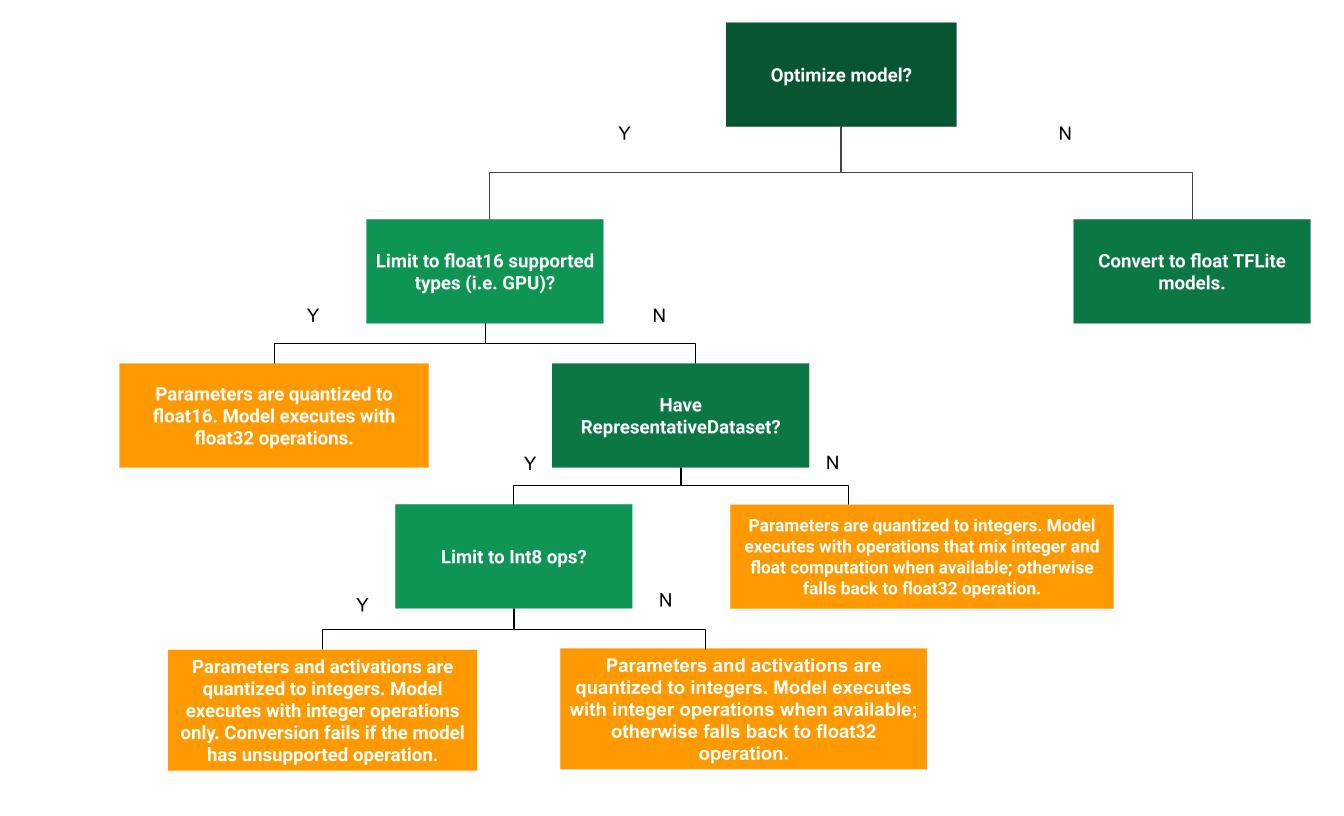
Sin cuantización
Se recomienda comenzar con la conversión a un modelo de TFLite sin cuantización. Esto generará un modelo de TFLite de números de punto flotante.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Te recomendamos que lo hagas como paso inicial para verificar que los operadores del modelo de TF original sean compatibles con TFLite y también se puedan usar como referencia para depurar los errores de cuantización que introducen los métodos posteriores de cuantización posterior al entrenamiento. Por ejemplo, si un modelo de TFLite cuantizado produce resultados inesperados, mientras que el modelo de TFLite de punto flotante es preciso, podemos reducir el problema a errores introducidos por la versión cuantizada de los operadores de TFLite.
Cuantización de rango dinámico
La cuantización del rango dinámico proporciona un uso reducido de la memoria y un cálculo más rápido sin que tengas que proporcionar un conjunto de datos representativo para la calibración. Este tipo de cuantización cuantiza de forma estática solo los pesos de punto flotante a número entero en el momento de la conversión, lo que proporciona 8 bits de precisión:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Para reducir aún más la latencia durante la inferencia, los operadores de "rango dinámico" cuantifican de forma dinámica las activaciones según su rango en 8 bits y realizan cálculos con pesos y activaciones de 8 bits. Esta optimización proporciona latencias cercanas a las inferencias de punto fijo completamente fijas. Sin embargo, los resultados aún se almacenan con números de punto flotante, por lo que el aumento de velocidad de las operaciones de rango dinámico es menor que el de un cálculo completo de punto fijo.
Cuantización de números enteros completa
Puedes obtener más mejoras en la latencia, reducciones en el uso máximo de memoria y compatibilidad con aceleradores o dispositivos de hardware solo con números enteros si te aseguras de que todas las operaciones matemáticas del modelo estén cuantificadas como números enteros.
Para la cuantificación de números enteros completa, debes calibrar o estimar el rango, es decir, (mín., máx.) de todos los tensores de punto flotante en el modelo. A diferencia de los tensores constantes, como los pesos y los sesgos, los tensores variables, como la entrada del modelo, las activaciones (salidas de las capas intermedias) y la salida del modelo, no se pueden calibrar a menos que ejecutemos algunos ciclos de inferencia. Como resultado, el convertidor requiere un conjunto de datos representativo para calibrarlos. Este conjunto de datos puede ser un subconjunto pequeño (alrededor de 100 a 500 muestras) de los datos de entrenamiento o validación. Consulta la función representative_dataset() a continuación.
A partir de la versión 2.7 de TensorFlow, puedes especificar el conjunto de datos representativo a través de una firma, como en el siguiente ejemplo:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Si hay más de una firma en el modelo de TensorFlow determinado, puedes especificar el conjunto de datos múltiple especificando las claves de firma:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Puedes generar el conjunto de datos representativo proporcionando una lista de tensores de entrada:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Desde la versión 2.7 de TensorFlow, recomendamos usar el enfoque basado en firmas en lugar del enfoque basado en listas de tensores de entrada, ya que el orden de los tensores de entrada se puede invertir fácilmente.
Para realizar pruebas, puedes usar un conjunto de datos simulado de la siguiente manera:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Número entero con respaldo de número de punto flotante (con entrada y salida de punto flotante predeterminadas)
Para cuantificar completamente un modelo con números enteros, pero usar operadores de números de punto flotante cuando no tienen una implementación de números enteros (para garantizar que la conversión se realice sin problemas), sigue estos pasos:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Solo números enteros
Crear modelos solo con números enteros es un caso de uso común para LiteRT para microcontroladores y TPUs de borde de Coral.
Además, para garantizar la compatibilidad con dispositivos y aceleradores solo de números enteros (como microcontroladores de 8 bits y la Coral Edge TPU), puedes aplicar la cuantificación de números enteros completa para todas las operaciones, incluidas las de entrada y salida, siguiendo estos pasos:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Cuantización de Float16
Puedes reducir el tamaño de un modelo de punto flotante cuantificando los pesos en float16, el estándar IEEE para números de punto flotante de 16 bits. Para habilitar la cuantificación de pesos en float16, sigue estos pasos:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Las ventajas de la cuantización de float16 son las siguientes:
- Reduce el tamaño del modelo hasta la mitad (ya que todos los pesos se reducen a la mitad de su tamaño original).
- Causa una pérdida mínima de precisión.
- Admite algunos delegados (p.ej., el delegado de GPU) que pueden operar directamente en datos de float16, lo que genera una ejecución más rápida que los cálculos de float32.
Las desventajas de la cuantización de float16 son las siguientes:
- No reduce la latencia tanto como una cuantificación a matemáticas de punto fijo.
- De forma predeterminada, un modelo cuantizado de float16 "descuantizará" los valores de los pesos a float32 cuando se ejecute en la CPU. (Ten en cuenta que el delegado de la GPU no realizará esta desencuantización, ya que puede operar con datos de punto flotante de 16 bits).
Solo números enteros: activaciones de 16 bits con pesos de 8 bits (experimental)
Este es un esquema de cuantificación experimental. Es similar al esquema de "solo números enteros", pero las activaciones se cuantifican según su rango a 16 bits, los pesos se cuantifican en números enteros de 8 bits y el sesgo se cuantifica en números enteros de 64 bits. Esto se conoce como cuantificación de 16 x 8.
La principal ventaja de esta cuantización es que puede mejorar la precisión de forma significativa, pero solo aumenta ligeramente el tamaño del modelo.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Si la cuantificación de 16 x 8 no se admite para algunos operadores del modelo, este se puede cuantificar, pero los operadores no admitidos se mantienen en coma flotante. Para permitir esto, se debe agregar la siguiente opción a target_spec.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Estos son algunos ejemplos de los casos de uso en los que las mejoras en la precisión que proporciona este esquema de cuantificación incluyen los siguientes:
- superresolución,
- Procesamiento de señales de audio, como cancelación de ruido y formación de haces
- Reducción de ruido en imágenes
- Reconstrucción de HDR a partir de una sola imagen.
La desventaja de esta cuantificación es la siguiente:
- Actualmente, la inferencia es notablemente más lenta que la inferencia de números enteros completos de 8 bits debido a la falta de una implementación del kernel optimizada.
- Actualmente, no es compatible con los delegados de TFLite acelerados por hardware existentes.
Aquí puedes encontrar un instructivo para este modo de cuantización.
Precisión del modelo
Dado que los pesos se cuantifican después del entrenamiento, podría haber una pérdida de precisión, en especial para las redes más pequeñas. Se proporcionan modelos completamente cuantizados previamente entrenados para redes específicas en Kaggle Models. Es importante verificar la precisión del modelo cuantificado para comprobar que cualquier degradación en la precisión esté dentro de los límites aceptables. Existen herramientas para evaluar la precisión del modelo de LiteRT.
Como alternativa, si la disminución de la precisión es demasiado alta, considera usar el entrenamiento con reconocimiento de la cuantización. Sin embargo, para hacerlo, se requieren modificaciones durante el entrenamiento del modelo para agregar nodos de cuantización falsos, mientras que las técnicas de cuantización posterior al entrenamiento de esta página usan un modelo previamente entrenado existente.
Representación de tensores cuantificados
La cuantificación de 8 bits aproxima los valores de punto flotante con la siguiente fórmula.
\[real\_value = (int8\_value - zero\_point) \times scale\]
La representación tiene dos partes principales:
Son pesos por eje (también conocidos como por canal) o por tensor representados por valores de complemento a dos de int8 en el rango [-127, 127] con un punto cero igual a 0.
Activaciones o entradas por tensor representadas por valores de complemento a dos de int8 en el rango [-128, 127], con un punto cero en el rango [-128, 127].
Para obtener una vista detallada de nuestro esquema de cuantización, consulta nuestra especificación de cuantización. Se recomienda a los proveedores de hardware que deseen conectarse a la interfaz de delegados de TensorFlow Lite que implementen el esquema de cuantización que se describe allí.