
Kuantisasi pasca-pelatihan adalah teknik konversi yang dapat mengurangi ukuran model sekaligus meningkatkan latensi CPU dan akselerator hardware, dengan sedikit penurunan akurasi model. Anda dapat menguantisasi model TensorFlow float yang sudah dilatih saat mengonversinya ke format LiteRT menggunakan LiteRT Converter.
Metode Pengoptimalan
Ada beberapa opsi kuantisasi pasca-pelatihan yang dapat dipilih. Berikut adalah tabel ringkasan pilihan dan manfaat yang diberikannya:
| Teknik | Manfaat | Hardware |
|---|---|---|
| Kuantisasi rentang dinamis | 4x lebih kecil, peningkatan kecepatan 2x-3x | CPU |
| Kuantisasi bilangan bulat penuh | 4x lebih kecil, peningkatan kecepatan 3x+ | CPU, Edge TPU, Mikrokontroler |
| Kuantisasi Float16 | 2x lebih kecil, akselerasi GPU | CPU, GPU |
Pohon keputusan berikut dapat membantu menentukan metode kuantisasi pasca-pelatihan mana yang paling sesuai untuk kasus penggunaan Anda:
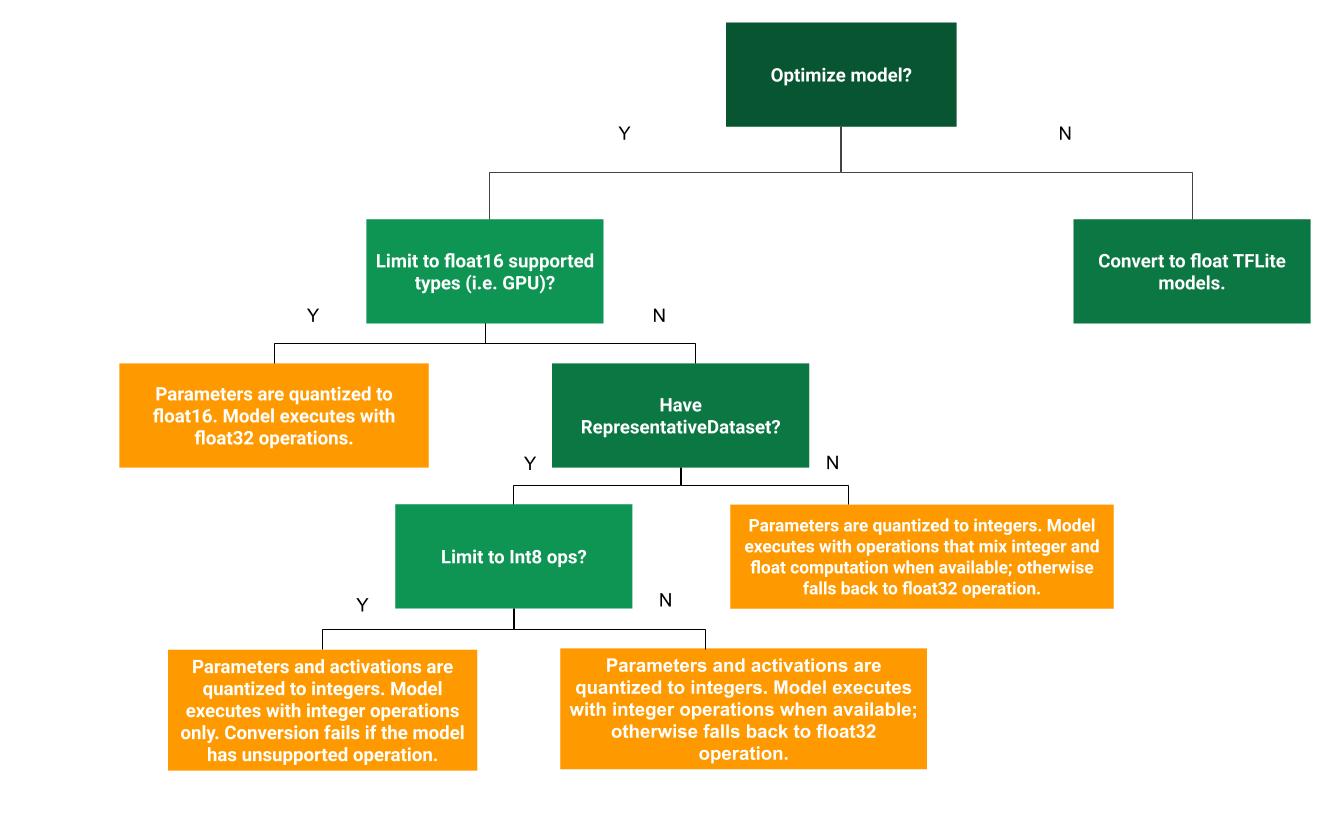
Tanpa Kuantisasi
Mengonversi ke model TFLite tanpa kuantisasi adalah titik awal yang direkomendasikan. Tindakan ini akan menghasilkan model TFLite float.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Sebaiknya lakukan hal ini sebagai langkah awal untuk memverifikasi bahwa operator model TF asli kompatibel dengan TFLite dan juga dapat digunakan sebagai dasar untuk men-debug error kuantisasi yang diperkenalkan oleh metode kuantisasi pasca-pelatihan berikutnya. Misalnya, jika model TFLite terkuantisasi menghasilkan hasil yang tidak terduga, sementara model TFLite float akurat, kita dapat mempersempit masalahnya menjadi error yang disebabkan oleh versi terkuantisasi dari operator TFLite.
Kuantisasi rentang dinamis
Kuantisasi rentang dinamis memberikan penggunaan memori yang lebih rendah dan komputasi yang lebih cepat tanpa Anda harus memberikan set data representatif untuk kalibrasi. Jenis kuantisasi ini, secara statis hanya menguantisasi bobot dari floating point ke bilangan bulat pada waktu konversi, yang memberikan presisi 8-bit:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Untuk lebih mengurangi latensi selama inferensi, operator "rentang dinamis" menguantisasi aktivasi secara dinamis berdasarkan rentangnya menjadi 8-bit dan melakukan komputasi dengan bobot dan aktivasi 8-bit. Pengoptimalan ini memberikan latensi yang mendekati inferensi titik tetap sepenuhnya. Namun, output masih disimpan menggunakan floating point sehingga peningkatan kecepatan operasi rentang dinamis kurang dari komputasi fixed-point penuh.
Kuantisasi bilangan bulat penuh
Anda bisa mendapatkan peningkatan latensi lebih lanjut, pengurangan penggunaan memori puncak, dan kompatibilitas dengan perangkat atau akselerator hardware khusus bilangan bulat dengan memastikan semua matematika model dikuantisasi bilangan bulat.
Untuk kuantisasi bilangan bulat penuh, Anda perlu mengalibrasi atau memperkirakan rentang,
yaitu, (min, maks) semua tensor floating point dalam model. Tidak seperti tensor konstanta seperti bobot dan bias, tensor variabel seperti input model, aktivasi (output lapisan perantara), dan output model tidak dapat dikalibrasi kecuali jika kita menjalankan beberapa siklus inferensi. Akibatnya, konverter
memerlukan set data representatif untuk mengalibrasinya. Set data ini dapat berupa subset kecil (sekitar ~100-500 sampel) dari data pelatihan atau validasi. Lihat fungsi representative_dataset() di bawah.
Mulai dari versi TensorFlow 2.7, Anda dapat menentukan set data representatif melalui signature seperti contoh berikut:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Jika ada lebih dari satu tanda tangan dalam model TensorFlow tertentu, Anda dapat menentukan beberapa set data dengan menentukan kunci tanda tangan:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Anda dapat membuat set data perwakilan dengan memberikan daftar tensor input:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Sejak versi TensorFlow 2.7, sebaiknya gunakan pendekatan berbasis tanda tangan daripada pendekatan berbasis daftar tensor input karena urutan tensor input dapat dengan mudah dibalik.
Untuk tujuan pengujian, Anda dapat menggunakan set data dummy sebagai berikut:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Integer dengan penggantian float (menggunakan input/output float default)
Untuk menguantisasi model bilangan bulat sepenuhnya, tetapi menggunakan operator float jika tidak memiliki implementasi bilangan bulat (untuk memastikan konversi terjadi dengan lancar), gunakan langkah-langkah berikut:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Hanya bilangan bulat
Membuat model khusus bilangan bulat adalah kasus penggunaan umum untuk LiteRT for Microcontrollers dan Coral Edge TPU.
Selain itu, untuk memastikan kompatibilitas dengan perangkat khusus bilangan bulat (seperti mikrokontroler 8-bit) dan akselerator (seperti Coral Edge TPU), Anda dapat menerapkan kuantisasi bilangan bulat penuh untuk semua operasi termasuk input dan output, dengan menggunakan langkah-langkah berikut:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Kuantisasi Float16
Anda dapat mengurangi ukuran model floating point dengan menguantisasi bobot ke float16, standar IEEE untuk bilangan floating point 16-bit. Untuk mengaktifkan kuantisasi bobot float16, ikuti langkah-langkah berikut:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Keuntungan kuantisasi float16 adalah sebagai berikut:
- Metode ini mengurangi ukuran model hingga setengahnya (karena semua bobot menjadi setengah dari ukuran aslinya).
- Hal ini menyebabkan sedikit penurunan akurasi.
- Fitur ini mendukung beberapa delegasi (misalnya, delegasi GPU) yang dapat beroperasi langsung pada data float16, sehingga menghasilkan eksekusi yang lebih cepat daripada komputasi float32.
Kekurangan kuantisasi float16 adalah sebagai berikut:
- Hal ini tidak mengurangi latensi sebanyak kuantisasi ke matematika titik tetap.
- Secara default, model terkuantisasi float16 akan "mendekuantisasi" nilai bobot ke float32 saat dijalankan di CPU. (Perhatikan bahwa delegasi GPU tidak akan melakukan dekuantisasi ini, karena dapat beroperasi pada data float16.)
Khusus bilangan bulat: Aktivasi 16-bit dengan bobot 8-bit (eksperimental)
Ini adalah skema kuantisasi eksperimental. Skema ini mirip dengan skema "khusus bilangan bulat", tetapi aktivasi dikuantisasi berdasarkan rentangnya menjadi 16-bit, bobot dikuantisasi dalam bilangan bulat 8-bit, dan bias dikuantisasi menjadi bilangan bulat 64-bit. Ini disebut sebagai kuantisasi 16x8 lebih lanjut.
Keuntungan utama kuantisasi ini adalah dapat meningkatkan akurasi secara signifikan, tetapi hanya sedikit meningkatkan ukuran model.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Jika kuantisasi 16x8 tidak didukung untuk beberapa operator dalam model, maka model masih dapat dikuantisasi, tetapi operator yang tidak didukung tetap dalam float. Opsi berikut harus ditambahkan ke target_spec untuk mengizinkan hal ini.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Contoh kasus penggunaan yang akurasinya ditingkatkan oleh skema kuantisasi ini meliputi:
- resolusi super,
- pemrosesan sinyal audio seperti peredam bising dan pembentukan berkas,
- penghilangan derau gambar,
- Rekonstruksi HDR dari satu gambar.
Kekurangan kuantisasi ini adalah:
- Saat ini, inferensi jauh lebih lambat daripada bilangan bulat penuh 8-bit karena kurangnya penerapan kernel yang dioptimalkan.
- Saat ini, fitur ini tidak kompatibel dengan delegasi TFLite yang dipercepat hardware yang ada.
Tutorial untuk mode kuantisasi ini dapat ditemukan di sini.
Akurasi model
Karena bobot dikuantisasi setelah pelatihan, akurasi dapat berkurang, terutama untuk jaringan yang lebih kecil. Model yang sepenuhnya terkuantisasi dan telah dilatih disediakan untuk jaringan tertentu di Kaggle Models . Penting untuk memeriksa akurasi model yang dikuantisasi untuk memverifikasi bahwa penurunan akurasi berada dalam batas yang dapat diterima. Ada alat untuk mengevaluasi akurasi model LiteRT.
Atau, jika penurunan akurasi terlalu tinggi, pertimbangkan untuk menggunakan pelatihan yang kompatibel dengan kuantisasi . Namun, melakukannya memerlukan modifikasi selama pelatihan model untuk menambahkan node kuantisasi palsu, sedangkan teknik kuantisasi pasca-pelatihan di halaman ini menggunakan model terlatih yang sudah ada.
Representasi untuk tensor terkuantisasi
Kuantisasi 8-bit memperkirakan nilai floating point menggunakan formula berikut.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Representasi memiliki dua bagian utama:
Bobot per-sumbu (alias per-saluran) atau per-tensor yang diwakili oleh nilai komplemen dua int8 dalam rentang [-127, 127] dengan titik nol sama dengan 0.
Aktivasi/input per-tensor yang direpresentasikan oleh nilai komplemen dua int8 dalam rentang [-128, 127], dengan titik nol dalam rentang [-128, 127].
Untuk melihat skema kuantisasi kami secara mendetail, lihat spesifikasi kuantisasi kami. Vendor hardware yang ingin terhubung ke antarmuka delegasi TensorFlow Lite dianjurkan untuk menerapkan skema kuantisasi yang dijelaskan di sana.