
每个计算器都是一个图表的节点。我们介绍了如何创建新计算器、如何初始化计算器、如何执行计算、输入和输出流、时间戳和选项。图中的每个节点都实现为 Calculator。图的批量执行在其计算器内进行。计算器可以接收零个或更多个输入流和/或旁数据包,并生成零个或多个输出流和/或旁包。
CalculatorBase
您可以通过定义 CalculatorBase 类的新子类、实现多种方法,以及向 Mediapipe 注册新的子类来创建计算器。新计算器必须至少实现以下四种方法
GetContract()- 计算器作者可以在 GetContract() 中指定计算器的预期输入和输出类型。当图表初始化时,框架会调用静态方法来验证连接的输入和输出的数据包类型是否与本规范中的信息匹配。
Open()- 在图表启动后,框架调用
Open()。此时,输入端数据包可供计算器使用。Open()可解释节点配置操作(请参阅图表)并准备计算器的每次图表运行状态。此函数也可能会将数据包写入计算器输出中。Open()期间发生的错误可能会终止图运行。
- 在图表启动后,框架调用
Process()- 对于具有输入的计算器,只要至少有一个输入流有可用的数据包,框架就会重复调用
Process()。默认情况下,框架会保证所有输入都具有相同的时间戳(如需了解详情,请参阅同步)。启用并行执行功能后,系统会同时调用多个Process()调用。如果在Process()期间发生错误,框架会调用Close(),并且图表运行终止。
- 对于具有输入的计算器,只要至少有一个输入流有可用的数据包,框架就会重复调用
Close()- 在对
Process()的所有调用均完成或当所有输入流关闭时,框架会调用Close()。如果调用Open()并成功,即使图表运行因错误而终止,也始终会调用此函数。在Close()期间,没有任何输入流经由任何输入流提供,但仍可以访问输入旁数据包,因此可能会写入输出。在Close()返回后,计算器应被视为死节点。计算器对象会在图表完成运行后立即销毁。
- 在对
以下是来自 CalculatorBase.h 的代码段。
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static absl::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual absl::Status Open(CalculatorContext* cc) {
return absl::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual absl::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual absl::Status Close(CalculatorContext* cc) {
return absl::OkStatus();
}
...
};
计算器的生命周期
在初始化 MediaPipe 图期间,框架会调用 GetContract() 静态方法来确定预期的数据包类型。
框架会针对每次图表运行构造和销毁整个计算器(例如,每个视频或图片一次)。昂贵的对象或大型对象在图表运行期间保持不变,应作为输入侧数据包提供,以便在后续运行中不重复计算。
初始化后,对于图的每次运行,都会发生以下序列:
Open()Process()(重复)Close()
框架调用 Open() 来初始化计算器。Open() 应解读所有选项并设置计算器的每次图表运行状态。Open() 可能会获取输入侧数据包并将数据包写入计算器输出结果。在适当的情况下,应调用 SetOffset() 以减少输入流的潜在数据包缓冲。
如果在 Open() 或 Process() 期间发生错误(其中一个错误返回非 Ok 状态),则图表运行将终止,且不再调用计算器的方法,并且计算器将被销毁。
对于包含输入的计算器,只要至少有一个输入有可用的数据包,框架就会调用 Process()。框架可以保证所有输入都具有相同的时间戳,时间戳会随着每次调用 Process() 而增加,并且所有数据包都已传送。因此,在调用 Process() 时,某些输入可能没有任何数据包。数据包丢失的输入似乎会生成空数据包(没有时间戳)。
框架会在对 Process() 进行所有调用后调用 Close()。所有输入都将用尽,但 Close() 可以访问输入侧数据包,并且可能会写入输出。Close 返回后,计算器将被销毁。
没有输入内容的计算器称为来源。只要返回 Ok 状态,源计算器就会继续调用 Process()。源计算器通过返回停止状态(即 mediaPipe::tool::StatusStop())表明已耗尽电量。
识别输入和输出
计算器的公共接口由一组输入流和输出流组成。在 CalculatorGraphConfiguration 中,一些计算器的输出使用命名流连接到其他计算器的输入。流名称通常小写,而输入和输出标记通常大写。在下面的示例中,标记名称为 VIDEO 的输出使用名为 video_stream 的流连接到标记名称为 VIDEO_IN 的输入。
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
输入流和输出流可以通过索引编号、标记名称或者标记名称和索引编号的组合来标识。您可以在下面的示例中查看输入和输出标识符的一些示例。SomeAudioVideoCalculator 按标记标识其视频输出,按标记和索引的组合标识其音频输出。带有 VIDEO 标记的输入会连接到名为 video_stream 的流。带有 AUDIO 标记以及索引 0 和 1 的输出会连接到名为 audio_left 和 audio_right 的流。SomeAudioCalculator 仅按索引标识其音频输入(不需要标记)。
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
在计算器实现中,输入和输出也由代码名称和索引编号标识。以下函数标识了输入和输出:
- 通过索引编号:仅通过索引
0标识组合输入流。 - 按代码名称:视频输出流由代码名称“VIDEO”进行标识。
- 按标记名称和索引编号:输出音频流由标记名称
AUDIO与索引编号0和1的组合标识。
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return absl::OkStatus();
}
正在处理
在非源节点上调用的 Process() 必须返回 absl::OkStatus() 以表示一切顺利,或返回任何其他状态代码来指示错误
如果非来源计算器返回 tool::StatusStop(),则表示图表被提前取消。在这种情况下,所有源计算器和图表输入流都将被关闭(其余数据包将在图中传播)。
只要图表中的源节点返回 absl::OkStatus(,它就会继续对其调用 Process()。如需指示没有更多要生成的数据,则返回 tool::StatusStop()。任何其他状态都表示发生错误。
Close() 会返回 absl::OkStatus() 以表示成功。任何其他状态都表示失败。
以下是基本的 Process() 函数。它使用 Input() 方法(仅当计算器只有一个输入时才可以使用)来请求其输入数据。然后,它使用 std::unique_ptr 来分配输出数据包所需的内存,并执行计算。完成后,它会在将指针添加到输出流时释放指针。
absl::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return absl::OkStatus();
}
计算器选项
计算器通过 (1) 输入流数据包 (2) 输入侧数据包和 (3) 计算器选项接受处理参数。计算器选项(如果指定)将以字面量值的形式显示在 CalculatorGraphConfiguration.Node 消息的 node_options 字段中。
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
node_options 字段接受 proto3 语法。或者,也可以使用 proto2 语法在 options 字段中指定计算器选项。
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
并非所有计算器都支持计算器选项。为了接受选项,计算器通常会定义一个新的 protobuf 消息类型来表示其选项,例如 PacketClonerCalculatorOptions。然后,计算器将在其 CalculatorBase::Open 方法中读取该 protobuf 消息,也可能会在其 CalculatorBase::GetContract 函数或 CalculatorBase::Process 方法中读取该消息。通常,新的 protobuf 消息类型将使用“.proto”文件和 mediapipe_proto_library() 构建规则定义为 protobuf 架构。
mediapipe_proto_library(
name = "packet_cloner_calculator_proto",
srcs = ["packet_cloner_calculator.proto"],
visibility = ["//visibility:public"],
deps = [
"//mediapipe/framework:calculator_options_proto",
"//mediapipe/framework:calculator_proto",
],
)
示例计算器
本部分介绍了 PacketClonerCalculator 的实现,该实现是一项相对简单的工作,可用于许多计算器图表。PacketClonerCalculator 只会按需生成其最新输入数据包的副本。
当到达数据包的时间戳没有精确匹配时,PacketClonerCalculator 非常有用。假设我们有一个配有麦克风、光传感器和用于收集感官数据的摄像机的房间。每个传感器独立运行,间歇性地收集数据。假设每个传感器的输出为:
- 麦克风 = 房间内的声音音量(整数)
- 光传感器 = 房间亮度(整数)
- 摄像机 = 房间的 RGB 图片帧 (ImageFrame)
我们简单的感知管道旨在处理来自这 3 种传感器的感官数据,以便在摄像头拍摄的图像帧数据与上次收集的麦克风音量数据和光传感器亮度数据同步时,就可以随时执行。为了使用 MediaPipe 实现这一点,我们的感知流水线有 3 个输入流:
- Room_mic_signal - 此输入流中的每个数据包都是整数数据,表示房间内音频的音量以及时间戳。
- Room_lightening_sensor - 此输入流中的每个数据包都是整数数据,表示带有时间戳的房间照明亮度。
- Room_video_tick_signal - 此输入流中的每个数据包都是视频数据的图像帧,表示从房间内的摄像头收集的带有时间戳的视频。
下面是 PacketClonerCalculator 的实现。您可以看到 GetContract()、Open() 和 Process() 方法,以及保存最新输入数据包的实例变量 current_。
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return absl::OkStatus();
}
absl::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return absl::OkStatus();
}
absl::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return absl::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
通常,计算器只有 .cc 文件。不需要 .h,因为 mediapipe 使用注册来让计算器知道。定义计算器类后,请通过宏调用 REGISTER_CALCULATOR(calculator_class_name) 注册它。
下面是一个简单的 MediaPipe 图,其中包含 3 个输入流、1 个节点 (PacketClonerCalculator) 和 2 个输出流。
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
下图显示了 PacketClonerCalculator 如何根据其一系列输入数据包(顶部)定义其输出数据包(底部)。
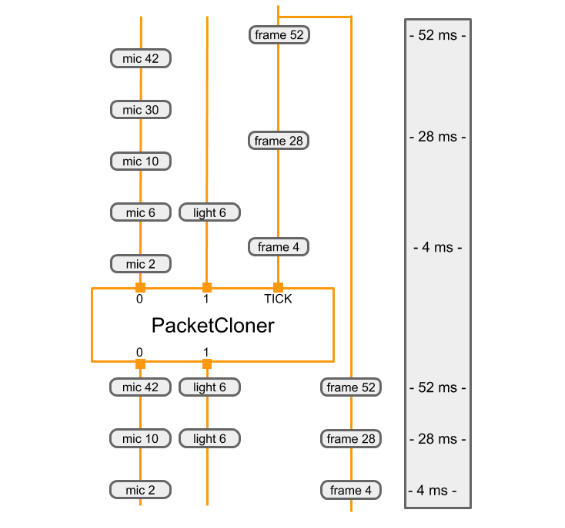 |
|---|
| 每次在其 TICK 输入流上收到数据包时,PacketClonerCalculator 都会输出其每个输入流中的最新数据包。输出数据包的顺序(底部)由输入数据包序列(顶部)及其时间戳确定。时间戳显示在图表的右侧。 |