
Os metadados do LiteRT fornecem um padrão para descrições de modelos. Os metadados são uma fonte importante de conhecimento sobre o que o modelo faz e as informações de entrada / saída. Os metadados consistem em
- partes legíveis por humanos que transmitem a prática recomendada ao usar o modelo e
- partes legíveis por máquina que podem ser usadas por geradores de código, como o gerador de código Android LiteRT e o recurso de vinculação de ML do Android Studio.
Todos os modelos de imagem publicados no Kaggle Models foram preenchidos com metadados.
Modelo com formato de metadados
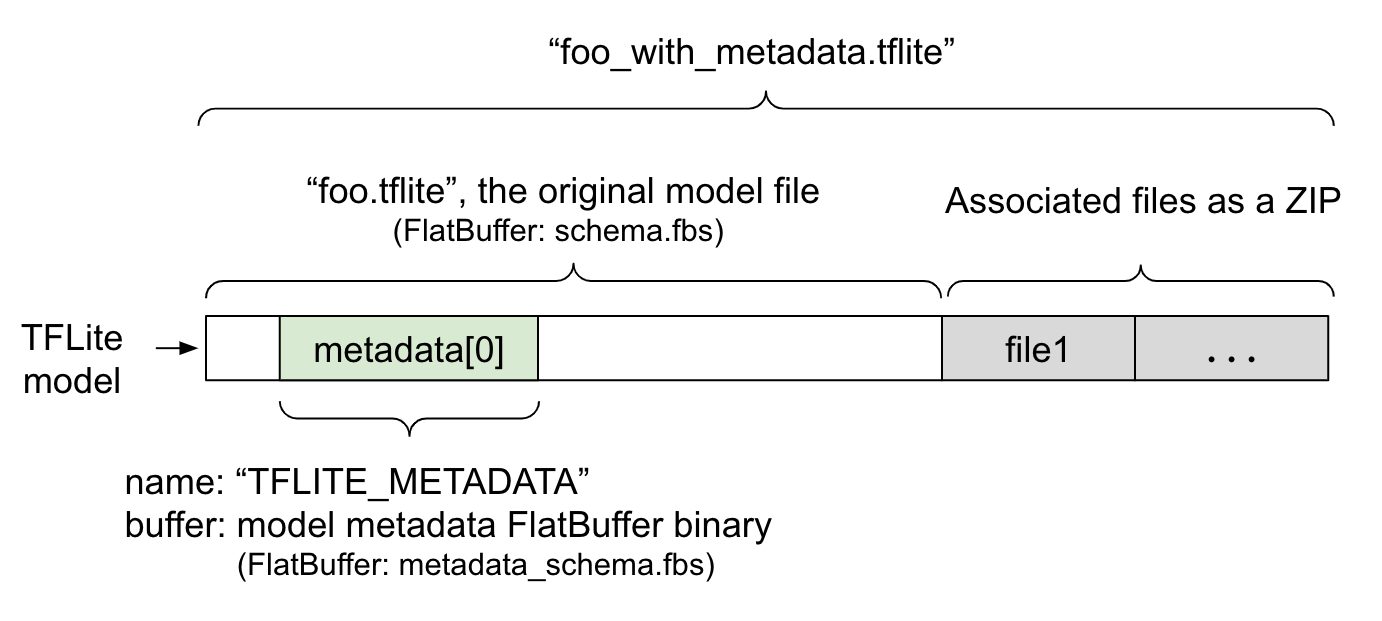
Os metadados do modelo são definidos em
metadata_schema.fbs,
um arquivo
FlatBuffer. Conforme mostrado na Figura 1, ele é armazenado no campo metadata do esquema do modelo TFLite, com o nome "TFLITE_METADATA". Alguns modelos podem vir com arquivos associados, como arquivos de marcador de classificação.
Esses arquivos são concatenados ao final do arquivo do modelo original como um ZIP
usando o modo "append"
do ZipFile (modo 'a'). O interpretador do TFLite
pode consumir o novo formato de arquivo da mesma maneira que antes. Consulte Empacotar os arquivos associados para mais informações.
Confira abaixo as instruções sobre como preencher, visualizar e ler metadados.
Configurar as ferramentas de metadados
Antes de adicionar metadados ao modelo, você precisa configurar um ambiente de programação em Python para executar o TensorFlow. Confira um guia detalhado sobre como fazer essa configuração aqui.
Depois de configurar o ambiente de programação Python, instale ferramentas adicionais:
pip install tflite-support
As ferramentas de metadados do LiteRT são compatíveis com o Python 3.
Como adicionar metadados usando a API Python do Flatbuffers
Os metadados do modelo no esquema têm três partes:
- Informações do modelo: descrição geral do modelo e itens como termos de licença. Consulte ModelMetadata. 2. Informações de entrada: descrição das entradas e do pré-processamento necessário, como normalização. Consulte SubGraphMetadata.input_tensor_metadata. 3. Informações de saída: descrição da saída e pós-processamento necessário, como mapeamento para rótulos. Consulte SubGraphMetadata.output_tensor_metadata.
Como o LiteRT só oferece suporte a um único subgrafo no momento, o gerador de código do LiteRT e o recurso de vinculação de ML do Android Studio vão usar ModelMetadata.name e ModelMetadata.description, em vez de SubGraphMetadata.name e SubGraphMetadata.description, ao mostrar metadados e gerar código.
Tipos de entrada / saída compatíveis
Os metadados do LiteRT para entrada e saída não são projetados com tipos de modelos específicos em mente, mas sim tipos de entrada e saída. Não importa o que o modelo faz funcionalmente. Desde que os tipos de entrada e saída consistam no seguinte ou em uma combinação do seguinte, ele será compatível com os metadados do TensorFlow Lite:
- Recurso: números que são inteiros sem sinal ou float32.
- Imagem: os metadados atualmente aceitam imagens RGB e em escala de cinza.
- Caixa delimitadora: caixas delimitadoras de forma retangular. O esquema é compatível com vários esquemas de numeração.
Empacotar os arquivos associados
Os modelos LiteRT podem vir com diferentes arquivos associados. Por exemplo, os modelos de linguagem natural geralmente têm arquivos de vocabulário que mapeiam partes de palavras para IDs de palavras. Os modelos de classificação podem ter arquivos de rótulos que indicam categorias de objetos. Sem os arquivos associados (se houver), um modelo não vai funcionar bem.
Agora, os arquivos associados podem ser agrupados com o modelo usando a biblioteca Python de metadados. O novo modelo LiteRT se torna um arquivo zip que contém o modelo e os arquivos associados. Ele pode ser descompactado com ferramentas zip comuns. Esse
novo formato de modelo continua usando a mesma extensão de arquivo, .tflite. Ele é compatível com o framework e o intérprete do TFLite. Consulte Empacotar metadados e arquivos associados no modelo para mais detalhes.
As informações do arquivo associado podem ser registradas nos metadados. Dependendo do tipo de arquivo e de onde ele está anexado (ou seja, ModelMetadata, SubGraphMetadata e TensorMetadata), o gerador de código Android LiteRT pode aplicar automaticamente o pré/pós-processamento correspondente ao objeto. Consulte a seção <Uso de geração de código> de
cada tipo de
arquivo associado
no esquema para mais detalhes.
Parâmetros de normalização e quantização
A normalização é uma técnica comum de pré-processamento de dados em machine learning. O objetivo da normalização é mudar os valores para uma escala comum, sem distorcer as diferenças nos intervalos de valores.
A quantização de modelo é uma técnica que permite representações de precisão reduzida de pesos e, opcionalmente, ativações para armazenamento e computação.
Em termos de pré e pós-processamento, a normalização e a quantização são duas etapas independentes. Veja os detalhes abaixo:
| Normalização | Quantização | |
|---|---|---|
Um exemplo dos valores de parâmetro da imagem de entrada na MobileNet para modelos de ponto flutuante e quantizados, respectivamente. |
Modelo de ponto flutuante: - média: 127,5 - desvio padrão: 127,5 Modelo quantizado: - média: 127,5 - desvio padrão: 127,5 |
Modelo de ponto flutuante: - zeroPoint: 0 - scale: 1.0 Modelo quantizado: - zeroPoint: 128.0 - scale:0.0078125f |
Quando invocar? |
Entradas: se os dados de entrada forem normalizados no treinamento, os dados de entrada da inferência também precisarão ser normalizados. Saídas: os dados de saída não serão normalizados em geral. |
Os modelos de ponto flutuante não precisam de quantização. O modelo quantizado pode ou não precisar de quantização no pré/pós- processamento. Isso depende do tipo de dados dos tensores de entrada/saída. - tensores de ponto flutuante: não é necessário quantização no pré/pós- processamento. As operações Quant e dequant são incorporadas ao gráfico do modelo. - tensores int8/uint8: precisam de quantização no pré/pós-processamento. |
Fórmula |
normalized_input = (input - mean) / std |
Quantização para entradas:
q = f / scale + zeroPoint Dequantização para saídas: f = (q - zeroPoint) * scale |
Onde estão os parâmetros |
Preenchido pelo criador do modelo e armazenado nos metadados do modelo como NormalizationOptions. |
Preenchido automaticamente pelo conversor do TFLite e armazenado no arquivo do modelo do TFLite. |
| Como conseguir os parâmetros? | Pela API
MetadataExtractor
[2]
|
Pela API Tensor do TFLite [1] ou pela API MetadataExtractor [2] |
| Os modelos de ponto flutuante e quant compartilham o mesmo valor? | Sim, os modelos de ponto flutuante e quant têm os mesmos parâmetros de normalização. | Não, o modelo de ponto flutuante não precisa de quantização. |
| O gerador de código do TFLite ou a vinculação de ML do Android Studio geram automaticamente no processamento de dados? | Sim |
Sim |
[1] A API Java do LiteRT e a API C++ do LiteRT.
[2] A biblioteca de extração de metadados
Ao processar dados de imagem para modelos uint8, às vezes a normalização e a quantização são ignoradas. Isso é aceitável quando os valores de pixel estão no intervalo [0, 255]. Mas, em geral, sempre processe os dados de acordo com os parâmetros de normalização e quantização, quando aplicável.
Exemplos
Confira exemplos de como os metadados devem ser preenchidos para diferentes tipos de modelos aqui:
Classificação de imagens
Faça o download do script aqui, que preenche os metadados em mobilenet_v1_0.75_160_quantized.tflite. Execute o script assim:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Para preencher metadados de outros modelos de classificação de imagens, adicione as especificações do modelo como esta ao script. O restante deste guia vai destacar algumas das principais seções no exemplo de classificação de imagens para ilustrar os elementos principais.
Análise detalhada do exemplo de classificação de imagens
Informações do modelo
Os metadados começam criando novas informações do modelo:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informações de entrada / saída
Nesta seção, mostramos como descrever a assinatura de entrada e saída do modelo. Esses metadados podem ser usados por geradores de código automáticos para criar código de pré e pós-processamento. Para criar informações de entrada ou saída sobre um tensor:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Entrada de imagem
A imagem é um tipo de entrada comum para machine learning. Os metadados do LiteRT oferecem suporte a informações como espaço de cores e pré-processamento, como normalização. A dimensão da imagem não requer especificação manual, já que é fornecida pela forma do tensor de entrada e pode ser inferida automaticamente.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Saída de rótulo
O marcador pode ser mapeado para um tensor de saída usando um arquivo associado com
TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Criar os Flatbuffers de metadados
O código a seguir combina as informações do modelo com as informações de entrada e saída:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Empacotar metadados e arquivos associados no modelo
Depois que os Flatbuffers de metadados forem criados, os metadados e o arquivo de rótulo serão
gravados no arquivo TFLite usando o método populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Você pode compactar quantos arquivos associados quiser no modelo usando load_associated_files. No entanto, é necessário empacotar pelo menos os arquivos
documentados nos metadados. Neste exemplo, o empacotamento do arquivo de rótulos é
obrigatório.
Visualizar os metadados
Use o Netron para visualizar os metadados ou leia os metadados de um modelo LiteRT em um formato JSON usando MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
O Android Studio também permite mostrar metadados usando o recurso de vinculação do Android Studio ML.
Controle de versões de metadados
O esquema de metadados é versionado pelo número de controle de versões semântico, que rastreia as mudanças do arquivo de esquema, e pela identificação do arquivo Flatbuffers, que indica a compatibilidade real da versão.
O número de controle de versão semântico
O esquema de metadados é versionado pelo número de controle de versões semântico, como PRINCIPAL.SECUNDÁRIA.PATCH. Ele rastreia mudanças de esquema de acordo com as regras aqui.
Consulte o histórico de campos adicionados após a versão 1.0.0.
A identificação do arquivo Flatbuffers
A versão semântica garante a compatibilidade se as regras forem seguidas, mas não implica a incompatibilidade real. Ao aumentar o número MAJOR, isso não significa necessariamente que a compatibilidade com versões anteriores foi interrompida. Portanto, usamos a identificação de arquivo Flatbuffers, file_identifier, para indicar a compatibilidade real do esquema de metadados. O identificador do arquivo tem exatamente quatro caracteres. Ele é fixado em um determinado esquema de metadados e não está sujeito a mudanças pelos usuários. Se a compatibilidade com versões anteriores do esquema de metadados precisar ser interrompida por algum motivo, o file_identifier será incrementado, por exemplo, de "M001" para "M002". Espera-se que o file_identifier seja alterado com muito menos frequência do que o metadata_version.
A versão mínima necessária do analisador de metadados
A versão mínima necessária do analisador de metadados é a versão mínima do analisador de metadados (o código gerado pelo Flatbuffers) que pode ler os Flatbuffers de metadados por completo. A versão é efetivamente o maior número entre as versões de todos os campos preenchidos e a menor versão compatível indicada pelo identificador de arquivo. A versão mínima necessária do analisador de metadados é preenchida automaticamente pelo MetadataPopulator quando os metadados são inseridos em um modelo do TFLite. Consulte o extrator de metadados para mais informações sobre como a versão mínima necessária do analisador de metadados é usada.
Ler os metadados dos modelos
A biblioteca Metadata Extractor é uma ferramenta conveniente para ler os metadados e arquivos associados de modelos em diferentes plataformas. Consulte a versão em Java e a versão em C++. Você pode criar sua própria ferramenta de extração de metadados em outros idiomas usando a biblioteca Flatbuffers.
Ler os metadados em Java
Para usar a biblioteca Metadata Extractor no seu app Android, recomendamos usar
o AAR de metadados do LiteRT hospedado no
MavenCentral.
Ele contém a classe MetadataExtractor, além das vinculações Java do FlatBuffers para o esquema de metadados e o esquema de modelo.
Você pode especificar isso nas dependências do build.gradle da seguinte maneira:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Para usar snapshots noturnos, adicione o repositório de snapshots do Sonatype.
É possível inicializar um objeto MetadataExtractor com um ByteBuffer que aponta
para o modelo:
public MetadataExtractor(ByteBuffer buffer);
O ByteBuffer precisa permanecer inalterado durante toda a vida útil do objeto MetadataExtractor. A inicialização pode falhar se o identificador do arquivo Flatbuffers dos metadados do modelo não corresponder ao do analisador de metadados. Consulte Controle de versão de metadados para mais informações.
Com identificadores de arquivo correspondentes, o extrator de metadados vai ler metadados gerados de todos os esquemas passados e futuros devido ao mecanismo de compatibilidade com versões anteriores e posteriores do Flatbuffers. No entanto, campos de esquemas futuros não podem ser extraídos por extratores de metadados mais antigos. A versão mínima necessária do analisador de metadados indica a versão mínima do analisador de metadados que pode ler os Flatbuffers de metadados por completo. Use o método a seguir para verificar se a condição mínima necessária da versão do analisador é atendida:
public final boolean isMinimumParserVersionSatisfied();
É permitido transmitir um modelo sem metadados. No entanto, invocar métodos que
leem os metadados vai causar erros de execução. Para verificar se um modelo tem
metadados, invoque o método hasMetadata:
public boolean hasMetadata();
O MetadataExtractor oferece funções convenientes para você receber os metadados dos tensores de entrada/saída. Por exemplo,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Embora o esquema do modelo LiteRT seja compatível com vários subgrafos, o interpretador do TFLite atualmente só aceita um único subgrafo. Portanto, MetadataExtractor omite o índice de subgrafo como um argumento de entrada nos métodos dele.
Ler os arquivos associados dos modelos
O modelo LiteRT com metadados e arquivos associados é essencialmente um arquivo ZIP que pode ser descompactado com ferramentas comuns para acessar os arquivos associados. Por exemplo, é possível descompactar mobilenet_v1_0.75_160_quantized e extrair o arquivo de rótulo no modelo da seguinte maneira:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Também é possível ler arquivos associados usando a biblioteca Metadata Extractor.
Em Java, transmita o nome do arquivo para o método MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Da mesma forma, em C++, isso pode ser feito com o método
ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;