
Perangkat edge sering kali memiliki memori atau daya komputasi yang terbatas. Berbagai pengoptimalan dapat diterapkan pada model sehingga model dapat dijalankan dalam batasan ini. Selain itu, beberapa pengoptimalan memungkinkan penggunaan hardware khusus untuk inferensi yang dipercepat.
LiteRT dan TensorFlow Model Optimization Toolkit menyediakan alat untuk meminimalkan kompleksitas pengoptimalan inferensi.
Sebaiknya Anda mempertimbangkan pengoptimalan model selama proses pengembangan aplikasi. Dokumen ini menguraikan beberapa praktik terbaik untuk mengoptimalkan model TensorFlow untuk deployment ke hardware edge.
Mengapa model harus dioptimalkan
Ada beberapa cara utama pengoptimalan model dapat membantu pengembangan aplikasi.
Pengurangan ukuran
Beberapa bentuk pengoptimalan dapat digunakan untuk mengurangi ukuran model. Model yang lebih kecil memiliki manfaat berikut:
- Ukuran penyimpanan yang lebih kecil: Model yang lebih kecil menempati ruang penyimpanan yang lebih sedikit di perangkat pengguna Anda. Misalnya, aplikasi Android yang menggunakan model yang lebih kecil akan menggunakan lebih sedikit ruang penyimpanan di perangkat seluler pengguna.
- Ukuran download yang lebih kecil: Model yang lebih kecil memerlukan lebih sedikit waktu dan bandwidth untuk didownload ke perangkat pengguna.
- Penggunaan memori yang lebih sedikit: Model yang lebih kecil menggunakan lebih sedikit RAM saat dijalankan, sehingga membebaskan memori untuk digunakan oleh bagian lain aplikasi Anda, dan dapat menghasilkan performa dan stabilitas yang lebih baik.
Kuantisasi dapat mengurangi ukuran model dalam semua kasus ini, berpotensi dengan mengorbankan akurasi. Pemangkasan dan pengelompokan dapat mengurangi ukuran model yang akan didownload dengan membuatnya lebih mudah dikompresi.
Pengurangan latensi
Latensi adalah jumlah waktu yang diperlukan untuk menjalankan satu inferensi dengan model tertentu. Beberapa bentuk pengoptimalan dapat mengurangi jumlah komputasi yang diperlukan untuk menjalankan inferensi menggunakan model, sehingga menghasilkan latensi yang lebih rendah. Latensi juga dapat memengaruhi konsumsi daya.
Saat ini, kuantisasi dapat digunakan untuk mengurangi latensi dengan menyederhanakan kalkulasi yang terjadi selama inferensi, yang berpotensi mengurangi akurasi.
Kompatibilitas akselerator
Beberapa akselerator hardware, seperti Edge TPU, dapat menjalankan inferensi dengan sangat cepat menggunakan model yang telah dioptimalkan dengan benar.
Biasanya, jenis perangkat ini memerlukan model untuk dikuantisasi dengan cara tertentu. Lihat dokumentasi setiap akselerator hardware untuk mempelajari lebih lanjut persyaratannya.
Kompromi
Pengoptimalan berpotensi menghasilkan perubahan akurasi model, yang harus dipertimbangkan selama proses pengembangan aplikasi.
Perubahan akurasi bergantung pada model individual yang dioptimalkan, dan sulit diprediksi sebelumnya. Umumnya, model yang dioptimalkan untuk ukuran atau latensi akan kehilangan sedikit akurasi. Bergantung pada aplikasi Anda, hal ini dapat atau tidak dapat memengaruhi pengalaman pengguna Anda. Dalam kasus yang jarang terjadi, model tertentu mungkin mendapatkan akurasi sebagai hasil dari proses pengoptimalan.
Jenis pengoptimalan
Saat ini LiteRT mendukung pengoptimalan melalui kuantisasi, pemangkasan, dan pengelompokan.
Teknik ini adalah bagian dari TensorFlow Model Optimization Toolkit, yang menyediakan sumber daya untuk teknik pengoptimalan model yang kompatibel dengan TensorFlow Lite.
Kuantisasi
Kuantisasi berfungsi dengan mengurangi presisi angka yang digunakan untuk merepresentasikan parameter model, yang secara default adalah angka floating point 32-bit. Hal ini menghasilkan ukuran model yang lebih kecil dan komputasi yang lebih cepat.
Jenis kuantisasi berikut tersedia di LiteRT:
| Teknik | Persyaratan data | Pengurangan ukuran | Akurasi | Hardware yang didukung |
|---|---|---|---|---|
| Kuantisasi float16 pasca-pelatihan | Tidak ada data | Hingga 50% | Penurunan akurasi yang tidak signifikan | CPU, GPU |
| Kuantisasi rentang dinamis setelah pelatihan | Tidak ada data | Hingga 75% | Kehilangan akurasi terkecil | CPU, GPU (Android) |
| Kuantisasi bilangan bulat pasca-pelatihan | Sampel representatif yang tidak berlabel | Hingga 75% | Sedikit kehilangan akurasi | CPU, GPU (Android), EdgeTPU |
| Pelatihan yang kompatibel dengan kuantisasi | Data pelatihan berlabel | Hingga 75% | Kehilangan akurasi terkecil | CPU, GPU (Android), EdgeTPU |
Pohon keputusan berikut membantu Anda memilih skema kuantisasi yang mungkin ingin Anda gunakan untuk model, hanya berdasarkan ukuran dan akurasi model yang diharapkan.
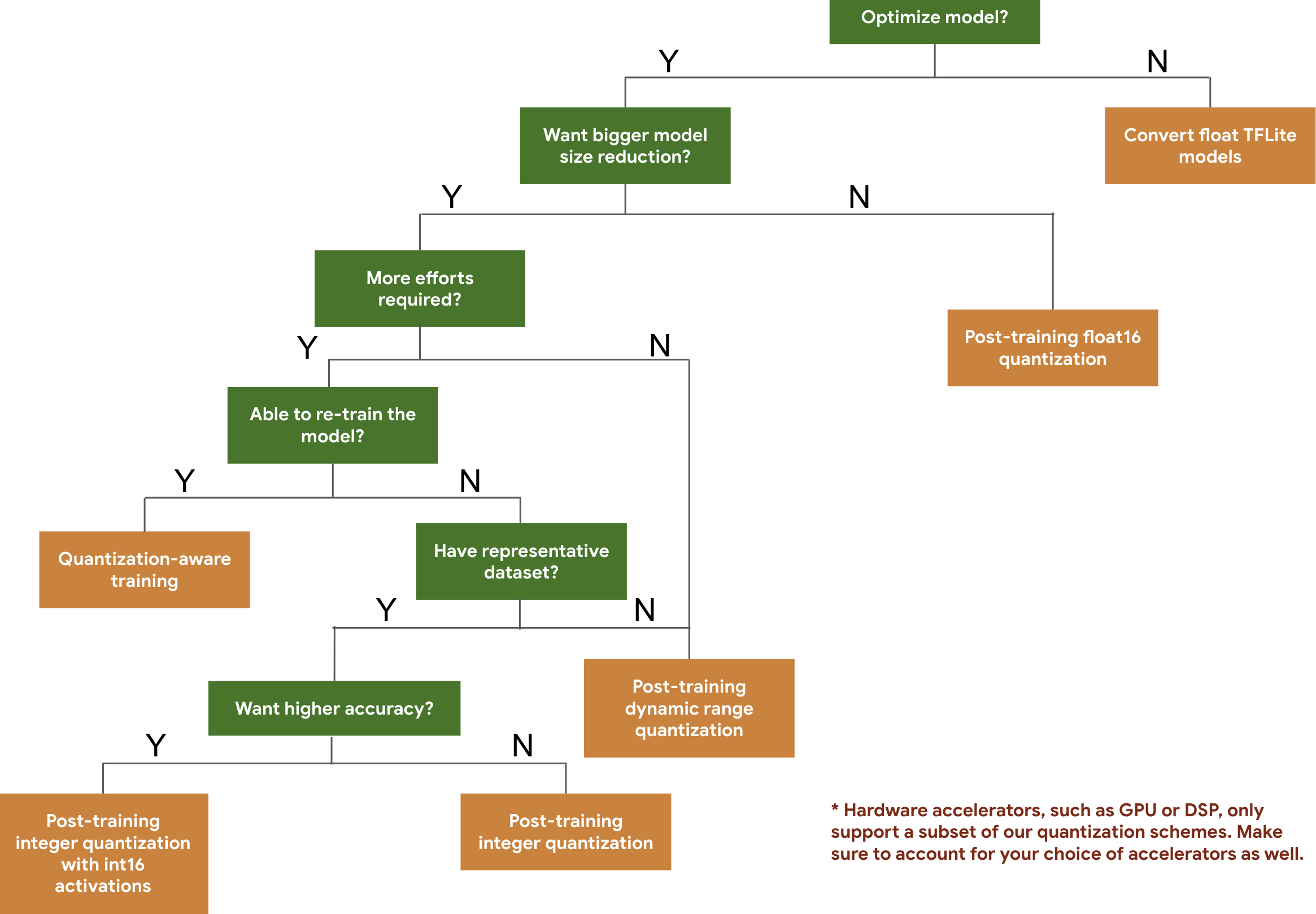
Berikut adalah hasil latensi dan akurasi untuk kuantisasi pasca-pelatihan dan pelatihan yang mendukung kuantisasi pada beberapa model. Semua angka latensi diukur di perangkat Pixel 2 menggunakan CPU inti besar tunggal. Seiring peningkatan kualitas toolkit, angka di sini juga akan meningkat:
| Model | Akurasi Top-1 (Asli) | Akurasi Top-1 (Dikuantisasi Pasca-Pelatihan) | Akurasi Top-1 (Pelatihan dengan Sadar Kuantisasi) | Latensi (Asli) (md) | Latensi (Post Training Quantized) (md) | Latensi (Pelatihan yang Mendukung Kuantisasi) (md) | Ukuran (Asli) (MB) | Ukuran (Dioptimalkan) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3,6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0,768 | T/A | 3973 | 2868 | T/A | 178.3 | 44,9 |
Kuantisasi bilangan bulat penuh dengan aktivasi int16 dan bobot int8
Kuantisasi dengan aktivasi int16 adalah skema kuantisasi bilangan bulat penuh dengan aktivasi dalam int16 dan bobot dalam int8. Mode ini dapat meningkatkan akurasi model yang dikuantisasi dibandingkan dengan skema kuantisasi bilangan bulat penuh dengan aktivasi dan bobot dalam int8 yang mempertahankan ukuran model yang serupa. Direkomendasikan jika aktivasi sensitif terhadap kuantisasi.
CATATAN: Saat ini, hanya implementasi kernel referensi yang tidak dioptimalkan yang tersedia di TFLite untuk skema kuantisasi ini, sehingga secara default performanya akan lambat dibandingkan dengan kernel int8. Keunggulan penuh mode ini saat ini dapat diakses melalui hardware khusus, atau software kustom.
Berikut adalah hasil akurasi untuk beberapa model yang diuntungkan dari mode ini.
| Model | Jenis metrik akurasi | Akurasi (aktivasi float32) | Akurasi (aktivasi int8) | Akurasi (aktivasi int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7% | 7,7% | 7,2% |
| DeepSpeech 0.5.1 (tidak di-unroll) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0.5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | Akurasi Top-1 | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | Akurasi Top-1 | 0,718 | 0,7126 | 0.7137 |
| MobileBert | F1(Pencocokan persis) | 88.81(81.23) | 2.08(0) | 88,73(81,15) |
Pemangkasan
Pemangkasan dilakukan dengan menghapus parameter dalam model yang hanya memiliki dampak kecil pada prediksinya. Model yang dipangkas memiliki ukuran yang sama di disk, dan memiliki latensi runtime yang sama, tetapi dapat dikompresi secara lebih efektif. Hal ini menjadikan pemangkasan sebagai teknik yang berguna untuk mengurangi ukuran download model.
Pada masa mendatang, LiteRT akan memberikan pengurangan latensi untuk model yang di-pruning.
Pengelompokan
Pengelompokan berfungsi dengan mengelompokkan bobot setiap lapisan dalam model ke dalam sejumlah kluster yang telah ditentukan sebelumnya, lalu membagikan nilai centroid untuk bobot yang termasuk dalam setiap kluster individual. Hal ini mengurangi jumlah nilai bobot unik dalam model, sehingga mengurangi kompleksitasnya.
Hasilnya, model yang dikelompokkan dapat dikompresi secara lebih efektif, sehingga memberikan manfaat deployment yang serupa dengan pemangkasan.
Alur kerja pengembangan
Sebagai titik awal, periksa apakah model di model yang dihosting dapat berfungsi untuk aplikasi Anda. Jika tidak, sebaiknya pengguna memulai dengan alat kuantisasi pasca-pelatihan karena alat ini dapat diterapkan secara luas dan tidak memerlukan data pelatihan.
Untuk kasus ketika target akurasi dan latensi tidak terpenuhi, atau dukungan akselerator hardware penting, pelatihan yang kompatibel dengan kuantisasi adalah opsi yang lebih baik. Lihat teknik pengoptimalan tambahan di bagian TensorFlow Model Optimization Toolkit.
Jika ingin mengurangi ukuran model lebih lanjut, Anda dapat mencoba pemangkasan dan/atau pengelompokan sebelum menguantisasi model.