
Utiliser des processeurs graphiques (GPU) pour exécuter vos modèles de machine learning (ML) peut considérablement améliorer les performances de votre modèle et l'expérience utilisateur de vos applications compatibles avec le ML. Sur les appareils iOS, vous pouvez activer l'utilisation une exécution accélérée par le GPU de vos modèles à l'aide d'un délégué. Les délégués agissent comme pilotes matériels pour LiteRT, qui vous permet d'exécuter le code de votre modèle sur des processeurs GPU.
Cette page explique comment activer l'accélération GPU pour les modèles LiteRT dans Applications iOS. Pour en savoir plus sur l'utilisation du délégué de GPU pour LiteRT, y compris les bonnes pratiques et les techniques avancées, consultez la documentation sur les GPU délégués.
Utiliser un GPU avec l'API Interpreter
L'interprète LiteRT fournit un ensemble pour créer des applications de machine learning. Les éléments suivants : les instructions vous guident dans l'ajout de la prise en charge du GPU à une application iOS. Ce guide suppose que vous disposez déjà d'une application iOS capable d'exécuter un modèle de ML avec LiteRT.
Modifier le Podfile pour inclure la compatibilité GPU
À partir de la version LiteRT 2.3.0, le délégué de GPU est exclu
du pod pour réduire la taille binaire. Vous pouvez les inclure en spécifiant
pour le pod TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
OU
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Vous pouvez également utiliser TensorFlowLiteObjC ou TensorFlowLiteC si vous souhaitez utiliser
Objective-C, disponible pour les versions 2.4.0 et ultérieures, ou l'API C.
Initialiser et utiliser le délégué de GPU
Vous pouvez utiliser le délégué de GPU avec l'interpréteur LiteRT API avec de nombreuses possibilités de programmation langues. Swift et Objective-C sont recommandés, mais vous pouvez aussi utiliser C++ et C. L'utilisation du langage C est obligatoire si vous utilisez une version de LiteRT antérieure. supérieure à 2,4. Les exemples de code suivants décrivent comment utiliser le délégué avec chaque de ces langues.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (antérieures à la version 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Remarques sur l'utilisation de la langue de l'API GPU
- Les versions LiteRT antérieures à la version 2.4.0 ne peuvent utiliser l'API C que pour Objectif C.
- L'API C++ n'est disponible que lorsque vous utilisez Bazel ou compilez TensorFlow En mode simplifié, seul. L'API C++ ne peut pas être utilisée avec CocoaPods.
- Lorsque vous utilisez LiteRT avec le délégué de GPU en C++, obtenez le GPU.
déléguer via la fonction
TFLGpuDelegateCreate(), puis le transmettre àInterpreter::ModifyGraphWithDelegate(), au lieu d'appelerInterpreter::AllocateTensors()
Compiler et tester avec le mode de publication
Passez à un build avec les paramètres d'accélérateur appropriés de l'API Metal pour améliorer les performances et pour les tests finaux. Cette section vous explique comment activer un build et configurer le paramètre d'accélération Metal ;
Pour passer à un build:
- Modifiez les paramètres de compilation en sélectionnant Product > Schéma > Modifier le schéma... puis en sélectionnant Exécuter.
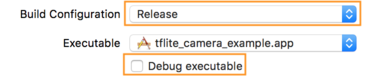
- Dans l'onglet Info, remplacez Build Configuration (Configuration de la compilation) par Release (Publier).
décochez la case Déboguer le fichier exécutable.
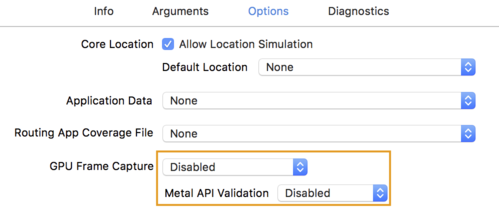
- Cliquez sur l'onglet Options et définissez Capture d'image GPU sur Désactivé.
et Validation de l'API Metal sur Désactivé.
- Veillez à sélectionner "Versions uniquement" sur une architecture 64 bits. Au-dessous
Navigateur de projets > tflite_camera_example > PROJET > nom_de_votre_projet >
Build Settings (Paramètres de compilation) définissez Build Active Architecture Only > Publier sur
Oui.

Compatibilité avancée avec les GPU
Cette section aborde les utilisations avancées du délégué de GPU pour iOS, y compris les options déléguées, les tampons d'entrée et de sortie, et l'utilisation de modèles quantifiés.
Déléguer des options pour iOS
Le constructeur du délégué de GPU accepte un struct d'options dans Swift
l'API,
Objective-C
de Google,
et C
Google Cloud.
Transmettre nullptr (API C) ou rien (API Objective-C et Swift) à la
initialiseur définit les options par défaut (détaillées dans la section "Utilisation de base"
dans l'exemple ci-dessus).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Tampons d'entrée/de sortie à l'aide de l'API C++
Le calcul sur le GPU nécessite que les données soient disponibles pour le GPU. Ce signifie souvent que vous devez effectuer une copie de la mémoire. Vous devez éviter d'avoir vos données dépassent la limite de mémoire du processeur/GPU, si possible, beaucoup de temps. En général, ce passage est inévitable, mais dans certains cas, des cas particuliers, l'un ou l'autre peut être omis.
Si l'entrée du réseau est une image déjà chargée dans la mémoire GPU (par (par exemple, une texture GPU contenant le flux de l'appareil photo), celle-ci peut rester dans la mémoire du GPU. sans jamais entrer dans la mémoire CPU. De même, si la sortie du réseau est dans la forme d'une image restituable, comme un style d'image transfert vous pouvez afficher directement le résultat à l'écran.
Pour optimiser les performances, LiteRT permet aux utilisateurs lire et écrire directement dans le tampon matériel TensorFlow, et contourner des copies de mémoire évitables.
En supposant que l'entrée de l'image se trouve dans la mémoire GPU, vous devez d'abord la convertir en
Objet MTLBuffer pour Metal. Vous pouvez associer un TfLiteTensor à un
MTLBuffer préparé par l'utilisateur avec le TFLGpuDelegateBindMetalBufferToTensor()
. Notez que cette fonction doit être appelée après
Interpreter::ModifyGraphWithDelegate() De plus, le résultat de l'inférence est
par défaut, copiées de la mémoire du GPU vers la mémoire du processeur. Vous pouvez désactiver ce comportement
en appelant Interpreter::SetAllowBufferHandleOutput(true) pendant
lors de l'initialisation.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Une fois le comportement par défaut désactivé, copier la sortie d'inférence à partir du GPU
mémoire vers la mémoire CPU
nécessite un appel explicite à
Interpreter::EnsureTensorDataIsReadable() pour chaque Tensor de sortie. Ce
fonctionne également pour les modèles quantifiés, mais vous devez tout de même
tampon de taille float32 avec des données de type float32, car il est lié au
tampon interne dé-quantifié.
Modèles quantifiés
Les bibliothèques déléguées de GPU iOS acceptent les modèles quantifiés par défaut. Vous ne devez pas modifier le code pour utiliser des modèles quantifiés avec le délégué de GPU. La La section suivante explique comment désactiver la prise en charge quantifiée pour les tests ou à des fins expérimentales.
Désactiver la compatibilité avec les modèles quantifiés
Le code suivant montre comment désactiver la prise en charge des modèles quantifiés.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Pour en savoir plus sur l'exécution de modèles quantifiés avec l'accélération GPU, consultez Présentation de la délégué de GPU.