
Modèles ouverts Gemma
Une famille de modèles ouverts, légers et à la pointe de la technologie, basés sur les mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini
Conception responsable
Intégrant des mesures de sécurité complètes, ces modèles contribuent à garantir des solutions d'IA responsables et fiables grâce à des ensembles de données sélectionnés et à un réglage rigoureux.
Performances inégalées en termes de taille
Les modèles Gemma obtiennent des résultats de référence exceptionnels dans leurs tailles 2 B, 7 B, 9 B et 27 B, dépassant même certains modèles ouverts plus volumineux.
Déploiement flexible
Déployez facilement sur mobile, Web et cloud à l'aide de Keras, JAX, MediaPipe, PyTorch, Hugging Face et plus encore.
Essayer Gemma 2
Repensé pour offrir des performances exceptionnelles et une efficacité inégalée, Gemma 2 optimise l'inférence ultrarapide sur différents matériels.
5 tirs
MMLU
Le benchmark MMLU (Massive Multitask Language Understanding) est un test qui mesure l'étendue des connaissances et les capacités de résolution de problèmes acquises par les grands modèles de langage lors du pré-entraînement.
25 coups
ARC-C
Le benchmark ARC-c est un sous-ensemble plus ciblé de l'ensemble de données ARC-e. Il ne contient que des questions auxquelles des algorithmes courants (basés sur la récupération et la cooccurrence de mots) ont répondu de manière incorrecte.
5 tirs
GSM8K
Le benchmark GSM8K teste la capacité d'un modèle de langage à résoudre des problèmes mathématiques de niveau primaire qui nécessitent souvent plusieurs étapes de raisonnement.
3-5-shot
AGIEval
Le benchmark AGIEval évalue l'intelligence générale d'un modèle de langage à l'aide de questions issues d'examens réels conçus pour évaluer les capacités intellectuelles humaines.
3-shot, CoT
BBH
Le benchmark BBH (BIG-Bench Hard) se concentre sur les tâches jugées au-delà des capacités des modèles de langage actuels, en testant leurs limites dans divers domaines de raisonnement et de compréhension.
3 images, F1
DROP
DROP est un benchmark de compréhension de lecture qui nécessite un raisonnement distinct sur les paragraphes.
5 tirs
Winogrande
Le benchmark Winogrande teste la capacité d'un modèle de langage à résoudre des tâches de remplissage de blancs ambiguës avec des options binaires, ce qui nécessite un raisonnement généralisé de bon sens.
10 coups
HellaSwag
Le benchmark HellaSwag met à l'épreuve la capacité d'un modèle de langage à comprendre et à appliquer le raisonnement de bon sens en sélectionnant la fin la plus logique d'une histoire.
4 coups
MATH
MATH évalue la capacité d'un modèle de langage à résoudre des problèmes mathématiques complexes, qui nécessitent du raisonnement, la résolution de problèmes en plusieurs étapes et la compréhension de concepts mathématiques.
Zero-shot
ARC-e
Le benchmark ARC-e évalue les compétences avancées de réponse à des questions d'un modèle de langage à l'aide de questions scientifiques à choix multiples authentiques, de niveau primaire.
Zero-shot
PIQA
Le benchmark PIQA teste la capacité d'un modèle de langage à comprendre et à appliquer des connaissances de bon sens physiques en répondant à des questions sur les interactions physiques quotidiennes.
Zero-shot
SIQA
Le benchmark SIQA évalue la compréhension d'un modèle de langage des interactions sociales et du bon sens social en posant des questions sur les actions des individus et leurs implications sociales.
Zero-shot
Boolq
Le benchmark BoolQ teste la capacité d'un modèle de langage à répondre aux questions "oui/non" naturelles, ce qui permet de tester sa capacité à effectuer des tâches d'inférence en langage naturel dans le monde réel.
5 tirs
TriviaQA
Le benchmark TriviaQA évalue les compétences de compréhension de la lecture à l'aide de triples question-réponse-preuve.
5 tirs
NQ
Le benchmark NQ (Natural Questions) teste la capacité d'un modèle de langage à trouver et à comprendre des réponses dans des articles Wikipedia entiers, en simulant des scénarios de questions-réponses réels.
pass@1
HumanEval
Le benchmark HumanEval teste les capacités de génération de code d'un modèle de langage en évaluant si ses solutions passent les tests unitaires fonctionnels pour les problèmes de programmation.
3-shot
MBPP
Le benchmark MBPP teste la capacité d'un modèle de langage à résoudre des problèmes de programmation Python de base, en se concentrant sur les concepts de programmation fondamentaux et l'utilisation de la bibliothèque standard.
100 %
75 %
50 %
25 %
0 %
100 %
75 %
50 %
25 %
0 %
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
LLAMA 3
8 B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
Gemma 1
2,5 Mrds
Gemma 2
2,6 Md
Mistral
7B
Gemma 1
7B
Gemma 2
9 milliards
Gemma 2
27B
*Il s'agit des benchmarks des modèles pré-entraînés. Consultez le rapport technique pour en savoir plus sur les performances avec d'autres méthodologies.
Modèles de recherche
Découvrez la famille étendue de modèles Gemma
PaliGemma 2 Nouveau
Champ d'application de Gemma

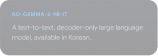

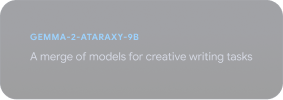
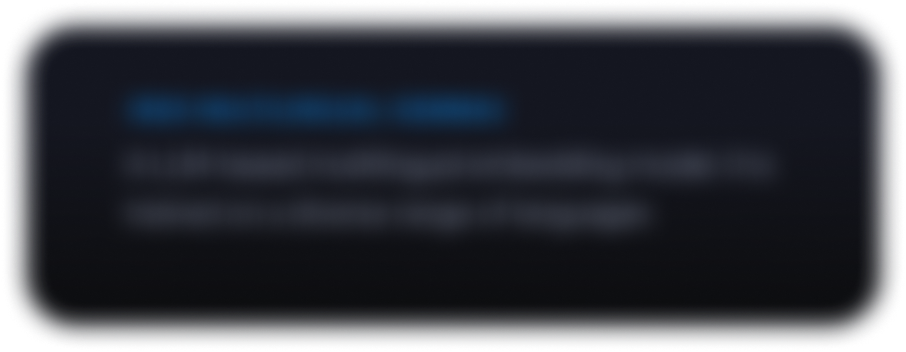
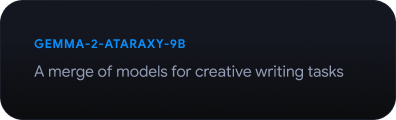

Explorer le Gemmaverse
Un vaste écosystème de modèles et d'outils Gemma créés par la communauté, prêts à alimenter et à inspirer votre innovation
Build
Commencer à créer avec Gemma




Déployer des modèles
Choisir votre cible de déploiement
![]() Mobile
Mobile
Déployer sur l'appareil avec Google AI Edge
Déployez directement sur les appareils pour bénéficier d'une fonctionnalité hors connexion à faible latence. Idéal pour les applications nécessitant une réactivité et une confidentialité en temps réel, telles que les applications mobiles, les appareils IoT et les systèmes embarqués.
![]() Web
Web
Intégration parfaite aux applications Web
Donnez à vos sites Web et services Web des fonctionnalités avancées d'IA, qui vous permettront de proposer des fonctionnalités interactives, du contenu personnalisé et une automatisation intelligente.
![]() Cloud
Cloud
Évoluez sans effort avec une infrastructure cloud
Exploitez l'évolutivité et la flexibilité du cloud pour gérer les déploiements à grande échelle, les charges de travail exigeantes et les applications d'IA complexes.