
पोस्ट-ट्रेनिंग क्वांटाइज़ेशन, मॉडल को बदलने की एक ऐसी तकनीक है जिससे मॉडल का साइज़ कम किया जा सकता है. साथ ही, इससे सीपीयू और हार्डवेयर ऐक्सलरेटर के इंतज़ार के समय को कम किया जा सकता है. हालांकि, इससे मॉडल की परफ़ॉर्मेंस पर थोड़ा असर पड़ सकता है. LiteRT Converter का इस्तेमाल करके, पहले से ट्रेन किए गए फ़्लोट TensorFlow मॉडल को LiteRT फ़ॉर्मैट में बदलते समय, उसे क्वांटाइज़ किया जा सकता है.
ऑप्टिमाइज़ेशन के तरीके
ट्रेनिंग के बाद क्वानटाइज़ेशन के कई विकल्प उपलब्ध हैं. यहां विकल्पों और उनसे मिलने वाले फ़ायदों की खास जानकारी देने वाली टेबल दी गई है:
| तकनीक | फ़ायदे | हार्डवेयर |
|---|---|---|
| डाइनैमिक रेंज क्वांटाइज़ेशन | चार गुना छोटा, दो से तीन गुना तेज़ | सीपीयू |
| पूर्णांक की पूरी वैल्यू का इस्तेमाल करके क्वांटाइज़ेशन | 4 गुना छोटी, 3 गुना ज़्यादा तेज़ | सीपीयू, Edge TPU, माइक्रोकंट्रोलर |
| Float16 क्वानटाइज़ेशन | 2 गुना छोटा, जीपीयू ऐक्सेलरेटेड | सीपीयू, जीपीयू |
नीचे दिए गए फ़्लोचार्ट से, यह तय करने में मदद मिल सकती है कि ट्रेनिंग के बाद क्वानटाइज़ेशन करने का कौनसा तरीका आपके इस्तेमाल के उदाहरण के लिए सबसे सही है:
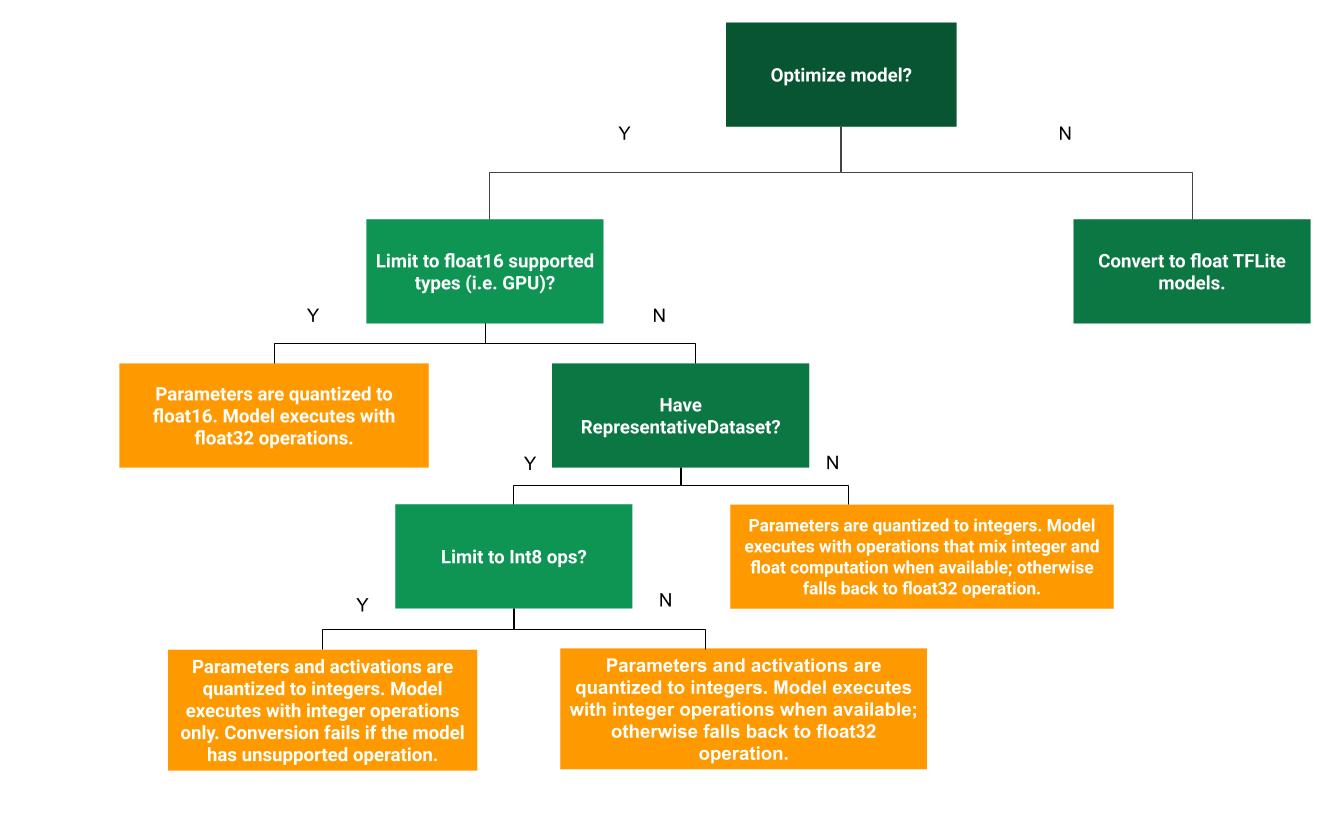
क्वांटाइज़ेशन नहीं
क्वांटाइज़ेशन के बिना टीएफ़लाइट मॉडल में बदलना, शुरुआती बिंदु के तौर पर सुझाया जाता है. इससे फ़्लोट टीएफ़लाइट मॉडल जनरेट होगा.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
हमारा सुझाव है कि आप इसे शुरुआती चरण के तौर पर करें. इससे यह पुष्टि की जा सकेगी कि ओरिजनल TF मॉडल के ऑपरेटर, TFLite के साथ काम करते हैं. साथ ही, इसका इस्तेमाल ट्रेनिंग के बाद लागू होने वाले क्वानटाइज़ेशन के तरीकों से जुड़ी गड़बड़ियों को डीबग करने के लिए भी किया जा सकता है. उदाहरण के लिए, अगर किसी क्वॉन्टाइज़्ड TFLite मॉडल से उम्मीद के मुताबिक नतीजे नहीं मिलते हैं, जबकि फ़्लोट TFLite मॉडल से सटीक नतीजे मिलते हैं, तो हम इस समस्या को TFLite ऑपरेटर के क्वॉन्टाइज़्ड वर्शन की वजह से हुई गड़बड़ियों तक सीमित कर सकते हैं.
डाइनैमिक रेंज क्वांटाइज़ेशन
डाइनैमिक रेंज क्वांटाइज़ेशन से, मेमोरी का इस्तेमाल कम होता है और तेज़ी से कंप्यूटेशन होता है. इसके लिए, आपको कैलिब्रेशन के लिए कोई प्रतिनिधि डेटासेट देने की ज़रूरत नहीं होती. इस तरह के क्वांटाइज़ेशन में, कन्वर्ज़न के समय सिर्फ़ फ़्लोटिंग पॉइंट से पूर्णांक तक के वज़न को स्टैटिक तौर पर क्वांटाइज़ किया जाता है. इससे 8 बिट की सटीक जानकारी मिलती है:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
अनुमान लगाने के दौरान लेटेन्सी को और कम करने के लिए, "डाइनैमिक-रेंज" ऑपरेटर, अपनी रेंज के आधार पर ऐक्टिवेशन को डाइनैमिक तौर पर 8-बिट में बदलते हैं. साथ ही, 8-बिट वज़न और ऐक्टिवेशन के साथ कंप्यूटेशन करते हैं. इस ऑप्टिमाइज़ेशन से, फ़्लोटिंग पॉइंट इन्फ़रेंस के मुकाबले फ़िक्स्ड पॉइंट इन्फ़रेंस के लिए कम समय लगता है. हालांकि, आउटपुट अब भी फ़्लोटिंग पॉइंट का इस्तेमाल करके सेव किए जाते हैं. इसलिए, डाइनैमिक-रेंज ऑपरेशंस की बढ़ी हुई स्पीड, फ़ुल फ़िक्स्ड-पॉइंट कंप्यूटेशन से कम होती है.
फ़ुल इंटिजर क्वांटाइज़ेशन
यह पक्का करके कि मॉडल के सभी गणितीय फ़ंक्शन पूर्णांकों में क्वांटाइज़ किए गए हैं, आपको इंतज़ार के समय में और सुधार मिल सकता है. साथ ही, पीक मेमोरी के इस्तेमाल में कमी और सिर्फ़ पूर्णांक वाले हार्डवेयर डिवाइसों या ऐक्सलरेटर के साथ काम करने की सुविधा मिल सकती है.
पूर्णांक क्वांटाइज़ेशन के लिए, आपको रेंज को कैलिब्रेट या अनुमानित करना होगा. जैसे, मॉडल में मौजूद सभी फ़्लोटिंग-पॉइंट टेंसर का (कम से कम, ज़्यादा से ज़्यादा) मान. वज़न और बायस जैसे कॉन्स्टेंट टेंसर के उलट, मॉडल इनपुट, ऐक्टिवेशन (इंटरमीडिएट लेयर के आउटपुट), और मॉडल आउटपुट जैसे वैरिएबल टेंसर को तब तक कैलिब्रेट नहीं किया जा सकता, जब तक हम कुछ अनुमान साइकल नहीं चलाते. इस वजह से, कन्वर्ज़न ट्रैकिंग को कैलिब्रेट करने के लिए, प्रतिनिधि डेटासेट की ज़रूरत होती है. यह डेटासेट, ट्रेनिंग या पुष्टि करने के डेटा का छोटा सबसेट (लगभग ~100 से 500 सैंपल) हो सकता है. नीचे दिए गए representative_dataset() फ़ंक्शन के बारे में पढ़ें.
TensorFlow 2.7 वर्शन से, सिग्नेचर के ज़रिए, प्रतिनिधि डेटासेट तय किया जा सकता है. इसका उदाहरण यहां दिया गया है:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
अगर दिए गए TensorFlow मॉडल में एक से ज़्यादा सिग्नेचर हैं, तो सिग्नेचर कुंजियां तय करके एक से ज़्यादा डेटासेट तय किए जा सकते हैं:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
इनपुट टेंसर की सूची देकर, प्रतिनिधि डेटासेट जनरेट किया जा सकता है:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 वर्शन के बाद से, हमारा सुझाव है कि इनपुट टेंसर लिस्ट के आधार पर काम करने वाले तरीके के बजाय, सिग्नेचर के आधार पर काम करने वाले तरीके का इस्तेमाल करें. ऐसा इसलिए, क्योंकि इनपुट टेंसर के क्रम को आसानी से बदला जा सकता है.
जांच के लिए, डमी डेटासेट का इस्तेमाल इस तरह किया जा सकता है:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
फ़्लोट फ़ॉलबैक के साथ पूर्णांक (डिफ़ॉल्ट फ़्लोट इनपुट/आउटपुट का इस्तेमाल करके)
किसी मॉडल को पूरी तरह से पूर्णांक में बदलने के लिए, लेकिन फ़्लोट ऑपरेटर का इस्तेमाल तब करें, जब उनमें पूर्णांक लागू न किया गया हो (ताकि कन्वर्ज़न आसानी से हो सके), तो यह तरीका अपनाएं:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
सिर्फ़ पूर्णांक
सिर्फ़ पूर्णांक वाले मॉडल बनाना, माइक्रोकंट्रोलर के लिए LiteRT और Coral Edge TPU के लिए एक सामान्य इस्तेमाल का उदाहरण है.
इसके अलावा, सिर्फ़ पूर्णांक वाले डिवाइसों (जैसे कि 8-बिट माइक्रोकंट्रोलर) और ऐक्सलरेटर (जैसे कि Coral Edge TPU) के साथ काम करने की सुविधा को पक्का करने के लिए, इनपुट और आउटपुट सहित सभी ऑप्स के लिए, पूर्णांक क्वांटाइज़ेशन लागू किया जा सकता है. इसके लिए, यह तरीका अपनाएं:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 क्वानटाइज़ेशन
फ़्लोटिंग पॉइंट मॉडल के साइज़ को कम किया जा सकता है. इसके लिए, वज़न को float16 में बदला जाता है. यह 16-बिट फ़्लोटिंग पॉइंट नंबर के लिए IEEE स्टैंडर्ड है. वज़न के float16 क्वांटाइज़ेशन को चालू करने के लिए, यह तरीका अपनाएं:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 क्वानटाइज़ेशन के ये फ़ायदे हैं:
- इससे मॉडल का साइज़ आधा हो जाता है, क्योंकि सभी वेट का साइज़ उनके ओरिजनल साइज़ का आधा हो जाता है.
- इससे सटीक जानकारी मिलने की संभावना कम हो जाती है.
- यह कुछ डेलिगेट (जैसे, GPU डेलिगेट) के साथ काम करता है.ये डेलिगेट, सीधे तौर पर float16 डेटा पर काम कर सकते हैं. इससे float32 कंप्यूटेशन की तुलना में, मॉडल को कम समय में एक्ज़ीक्यूट किया जा सकता है.
float16 क्वांटाइज़ेशन के ये नुकसान हैं:
- यह फ़्लोटिंग पॉइंट गणित के बजाय फ़िक्स्ड पॉइंट गणित का इस्तेमाल करने से, इंतज़ार के समय को उतना कम नहीं करता.
- डिफ़ॉल्ट रूप से, CPU पर चलाने के दौरान, float16 क्वांटाइज़्ड मॉडल, वज़न की वैल्यू को float32 में "डीक्वांटाइज़" करेगा. (ध्यान दें कि जीपीयू डेलिगेट, इस डीक्वांटाइज़ेशन को पूरा नहीं करेगा, क्योंकि यह फ़्लोट16 डेटा पर काम कर सकता है.)
सिर्फ़ पूर्णांक: 8-बिट वज़न के साथ 16-बिट ऐक्टिवेशन (एक्सपेरिमेंट के लिए)
यह एक एक्सपेरिमेंटल क्वांटाइज़ेशन स्कीम है. यह "सिर्फ़ पूर्णांक" स्कीम की तरह ही है. हालांकि, इसमें ऐक्टिवेशन को 16-बिट की रेंज के हिसाब से, वज़न को 8-बिट पूर्णांक के हिसाब से, और बायस को 64-बिट पूर्णांक के हिसाब से बांटा जाता है. इसे 16x8 क्वांटाइज़ेशन भी कहा जाता है.
इस क्वांटाइज़ेशन का मुख्य फ़ायदा यह है कि इससे सटीकता में काफ़ी सुधार किया जा सकता है. हालांकि, इससे मॉडल का साइज़ थोड़ा ही बढ़ता है.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
अगर मॉडल में कुछ ऑपरेटर के लिए 16x8 क्वांटाइज़ेशन की सुविधा उपलब्ध नहीं है, तो भी मॉडल को क्वांटाइज़ किया जा सकता है. हालाँकि, जिन ऑपरेटर के लिए यह सुविधा उपलब्ध नहीं है उन्हें फ़्लोट में रखा जाता है. इसकी अनुमति देने के लिए, टारगेट स्पेसिफ़िकेशन में यह विकल्प जोड़ें.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
क्वांटाइज़ेशन की इस स्कीम से, सटीकता को बेहतर बनाने के लिए इस्तेमाल किए जाने वाले उदाहरणों में ये शामिल हैं:
- सुपर-रिज़ॉल्यूशन,
- ऑडियो सिग्नल प्रोसेसिंग, जैसे कि नॉइज़ कैंसलिंग और बीमफ़ॉर्मिंग,
- इमेज से नॉइज़ हटाना,
- किसी एक इमेज से एचडीआर इमेज को फिर से बनाना.
इस क्वांटाइज़ेशन का नुकसान यह है कि:
- फ़िलहाल, ऑप्टिमाइज़ किए गए कर्नल को लागू न करने की वजह से, 8-बिट फ़ुल इंटिजर की तुलना में अनुमान लगाने की प्रोसेस काफ़ी धीमी है.
- फ़िलहाल, यह हार्डवेयर की मदद से तेज़ी से काम करने वाले मौजूदा TFLite डेलिगेट के साथ काम नहीं करता है.
इस क्वानटाइज़ेशन मोड का ट्यूटोरियल यहां देखा जा सकता है.
मॉडल की सटीक जानकारी
ट्रेनिंग के बाद, वज़न को क्वांटाइज़ किया जाता है. इसलिए, सटीकता में कमी आ सकती है. ऐसा खास तौर पर छोटे नेटवर्क के लिए होता है. पूरी तरह से क्वांटाइज़ किए गए पहले से ट्रेन किए गए मॉडल, Kaggle Models पर कुछ खास नेटवर्क के लिए उपलब्ध कराए जाते हैं . क्वांटाइज़ किए गए मॉडल की सटीकता की जांच करना ज़रूरी है. इससे यह पुष्टि की जा सकती है कि सटीकता में कोई भी गिरावट, स्वीकार्य सीमाओं के अंदर है. LiteRT मॉडल की सटीकता का आकलन करने के लिए टूल उपलब्ध हैं.
इसके अलावा, अगर सटीक नतीजे मिलने की दर बहुत ज़्यादा कम हो जाती है, तो क्वांटाइज़ेशन अवेयर ट्रेनिंग का इस्तेमाल करें . हालांकि, ऐसा करने के लिए मॉडल ट्रेनिंग के दौरान बदलाव करने पड़ते हैं, ताकि फ़र्ज़ी क्वानटाइज़ेशन नोड जोड़े जा सकें. वहीं, इस पेज पर ट्रेनिंग के बाद क्वानटाइज़ेशन की तकनीकें, पहले से ट्रेन किए गए मॉडल का इस्तेमाल करती हैं.
क्वांटाइज़ किए गए टेंसर के लिए रिप्रेजेंटेशन
8-बिट क्वांटाइज़ेशन, फ़्लोटिंग पॉइंट वैल्यू का अनुमान लगाने के लिए इस फ़ॉर्मूले का इस्तेमाल करता है.
\[real\_value = (int8\_value - zero\_point) \times scale\]
इस प्रज़ेंटेशन के दो मुख्य हिस्से हैं:
हर ऐक्सिस (इसे हर चैनल भी कहा जाता है) या हर टेंसर के लिए, int8 के दो कॉम्प्लिमेंट वैल्यू के तौर पर दिखाए गए वज़न. इनकी रेंज [-127, 127] होती है और ज़ीरो-पॉइंट 0 के बराबर होता है.
हर टेंसर के लिए ऐक्टिवेशन/इनपुट, int8 के दो कॉम्प्लिमेंट वैल्यू के तौर पर दिखाए जाते हैं. इनकी रेंज [-128, 127] होती है. साथ ही, ज़ीरो-पॉइंट की रेंज [-128, 127] होती है.
क्वांटाइज़ेशन स्कीम के बारे में ज़्यादा जानने के लिए, कृपया हमारा क्वांटाइज़ेशन स्पेसिफ़िकेशन देखें. हार्डवेयर वेंडर जो TensorFlow Lite के डेलिगेट इंटरफ़ेस का इस्तेमाल करना चाहते हैं उन्हें वहां बताई गई क्वांटाइज़ेशन स्कीम को लागू करने का सुझाव दिया जाता है.