| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این لبه کد نحوه ایجاد یک طبقهبندیکننده متن سفارشی شده با استفاده از تنظیم کارآمد پارامتر (PET) را نشان میدهد. روشهای PET به جای تنظیم دقیق کل مدل، تنها مقدار کمی از پارامترها را بهروزرسانی میکنند که آموزش آن را نسبتاً آسان و سریع میکند. همچنین یادگیری رفتارهای جدید با داده های آموزشی نسبتاً کمی را برای مدل آسان تر می کند. این روش به طور مفصل در Towards Agile Text Classifiers for Everyone توضیح داده شده است که نشان می دهد چگونه می توان این تکنیک ها را برای انواع وظایف ایمنی به کار برد و تنها با چند صد مثال آموزشی به بهترین عملکرد دست یافت.
این آزمایشگاه کد از روش LoRA PET و مدل کوچکتر جما ( gemma_instruct_2b_en ) استفاده می کند زیرا می تواند سریعتر و کارآمدتر اجرا شود. کولب مراحل دریافت داده ها، قالب بندی آن ها برای LLM، آموزش وزنه های LoRA و سپس ارزیابی نتایج را پوشش می دهد. این نرمافزار کد روی مجموعه داده ETHOS ، مجموعه دادهای در دسترس عموم برای تشخیص سخنان نفرتآمیز، ساخته شده از نظرات YouTube و Reddit، آموزش میدهد. هنگامی که تنها بر روی 200 نمونه (1/4 از مجموعه داده) آموزش داده شود، به F1: 0.80 و ROC-AUC: 0.78 می رسد، کمی بالاتر از SOTA که در حال حاضر در تابلوی امتیازات گزارش شده است (در زمان نگارش، 15 فوریه 2024). هنگامی که بر روی 800 نمونه کامل آموزش داده می شود، مانند آن به امتیاز F1 83.74 و امتیاز ROC-AUC 88.17 می رسد. مدلهای بزرگتر، مانند gemma_instruct_7b_en عموماً عملکرد بهتری دارند، اما هزینههای آموزش و اجرا نیز بیشتر است.
هشدار ماشه : از آنجا که این آزمایشگاه کد یک طبقهبندی ایمنی برای تشخیص سخنان نفرتآمیز ایجاد میکند، مثالها و ارزیابی نتایج حاوی برخی زبانهای وحشتناک است.
نصب و راه اندازی
برای این نرم افزار کد، به نسخه اخیر keras (3)، keras-nlp (0.8.0) و یک حساب کاربری Kaggle برای دانلود مدل Gemma نیاز دارید.
import kagglehub
kagglehub.login()
pip install -q -U keras-nlppip install -q -U keras
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
مجموعه داده ETHOS را بارگیری کنید
در این بخش مجموعه دادهای را بارگذاری میکنید که طبقهبندیکننده ما روی آن آموزش داده میشود و آن را در یک مجموعه آموزشی و آزمایشی از قبل پردازش میکنید. شما از مجموعه داده های تحقیقاتی محبوب ETHOS استفاده خواهید کرد که برای تشخیص سخنان مشوق تنفر در رسانه های اجتماعی جمع آوری شده است. میتوانید اطلاعات بیشتری درباره نحوه جمعآوری مجموعه دادهها در مقاله ETHOS: مجموعه دادههای تشخیص گفتار نفرت آنلاین پیدا کنید.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
مدل را دانلود و نمونه سازی کنید
همانطور که در مستندات توضیح داده شده است، می توانید به راحتی از مدل Gemma به طرق مختلف استفاده کنید. با Keras، این کاری است که باید انجام دهید:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
model.generate('Question: what is the capital of France? ', max_length=32)
پیش پردازش متن و نشانه های جداکننده
برای کمک به مدل برای درک بهتر مقصود ما، می توانید متن را از قبل پردازش کنید و از نشانه های جداکننده استفاده کنید. این باعث می شود که مدل کمتر بتواند متنی را تولید کند که با قالب مورد انتظار مطابقت ندارد. برای مثال، ممکن است سعی کنید با نوشتن یک اعلان مانند این، یک طبقهبندی احساسات از مدل درخواست کنید:
Classify the following text into one of the following classes:[Positive,Negative]
Text: you look very nice today
Classification:
در این حالت، مدل ممکن است آنچه شما به دنبال آن هستید را خروجی دهد یا ندهد. به عنوان مثال، اگر متن حاوی کاراکترهای خط جدید باشد، احتمالاً تأثیر منفی بر عملکرد مدل خواهد داشت. یک رویکرد قوی تر، استفاده از توکن های جداکننده است. سپس اعلان تبدیل می شود:
Classify the following text into one of the following classes:[Positive,Negative]
<separator>
Text: you look very nice today
<separator>
Prediction:
این را می توان با استفاده از تابعی که متن را پیش پردازش می کند انتزاع کرد:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
حال، اگر تابع را با استفاده از همان دستور و متن قبلی اجرا کنید، باید همان خروجی را دریافت کنید:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:you look very nice today <separator> Prediction:
پس پردازش خروجی
خروجی های مدل توکن هایی با احتمالات مختلف هستند. به طور معمول، برای تولید متن، شما باید از میان چند توکن برتر و محتمل ترین نشانه ها را انتخاب کنید و جملات، پاراگراف ها یا حتی اسناد کامل بسازید. با این حال، برای طبقهبندی، آنچه در واقع اهمیت دارد این است که آیا مدل معتقد است که Positive بیشتر از Negative است یا برعکس.
با توجه به مدلی که قبلاً معرفی کردید، به این صورت است که می توانید خروجی آن را به ترتیب احتمالات مستقل Positive یا Negative بودن توکن بعدی پردازش کنید:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
شما می توانید با اجرای آن با دستوری که قبلا ایجاد کرده اید، آن عملکرد را آزمایش کنید:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
قرار دادن همه آن به عنوان یک طبقه بندی
برای سهولت استفاده، میتوانید تمام توابعی را که ایجاد کردهاید در یک طبقهبندیکننده sklearn مانند با توابع آسان و آشنا مانند predict() و predict_score() بپیچید.
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
تنظیم دقیق مدل
LoRA مخفف Low-Rank Adaptation است. این یک تکنیک تنظیم دقیق است که می تواند برای تنظیم دقیق مدل های زبان بزرگ استفاده شود. میتوانید در مقاله LoRA: سازگاری با رتبه پایین مدلهای زبان بزرگ بیشتر در مورد آن بخوانید.
پیاده سازی Keras از Gemma یک متد enable_lora() را ارائه می دهد که می توانید برای تنظیم دقیق از آن استفاده کنید:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
پس از فعال کردن LoRA، می توانید فرآیند تنظیم دقیق را شروع کنید. این تقریباً 5 دقیقه در هر دوره در Colab طول می کشد:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda x: agile_classifier.encode_for_training(*x)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Epoch 1/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 354s 703ms/step - loss: 1.1365 - sparse_categorical_accuracy: 0.5874 Epoch 2/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 338s 716ms/step - loss: 0.7579 - sparse_categorical_accuracy: 0.6662 Epoch 3/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 324s 721ms/step - loss: 0.6818 - sparse_categorical_accuracy: 0.6894 Epoch 4/4 400/400 ━━━━━━━━━━━━━━━━━━━━ 323s 725ms/step - loss: 0.5922 - sparse_categorical_accuracy: 0.7220 <keras.src.callbacks.history.History at 0x7eb7e369c490>
آموزش برای دوره های بیشتر منجر به دقت بالاتری می شود، تا زمانی که بیش از حد برازش اتفاق بیفتد.
نتایج را بررسی کنید
اکنون می توانید خروجی طبقه بندی کننده چابکی را که به تازگی آموزش داده اید بررسی کنید. این کد امتیاز کلاس پیش بینی شده را با توجه به یک متن خروجی می دهد:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
ارزیابی مدل
در نهایت، عملکرد مدل ما را با استفاده از دو معیار رایج، امتیاز F1 و AUC-ROC ارزیابی خواهید کرد. امتیاز F1 خطاهای منفی کاذب و مثبت کاذب را با ارزیابی میانگین هارمونیک دقت و یادآوری در یک آستانه طبقه بندی مشخص می گیرد. از طرف دیگر AUC-ROC مبادله بین نرخ مثبت واقعی و نرخ مثبت کاذب را در آستانه های مختلف ثبت می کند و مساحت زیر این منحنی را محاسبه می کند.
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
from sklearn.metrics import f1_score, roc_auc_score
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: 0.88
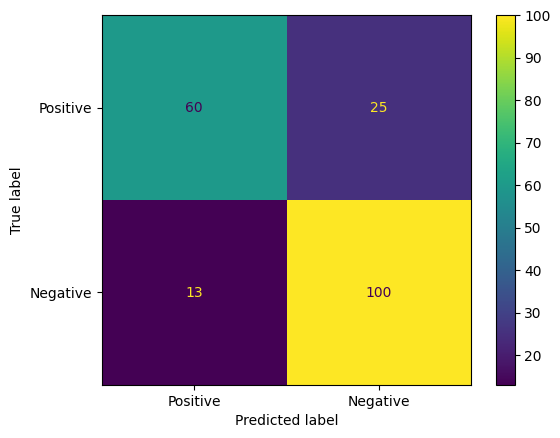
روش جالب دیگر برای ارزیابی پیشبینیهای مدل، ماتریسهای سردرگمی هستند. یک ماتریس سردرگمی به صورت بصری انواع مختلف خطاهای پیش بینی را به تصویر می کشد.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7eb7e2d29ab0>
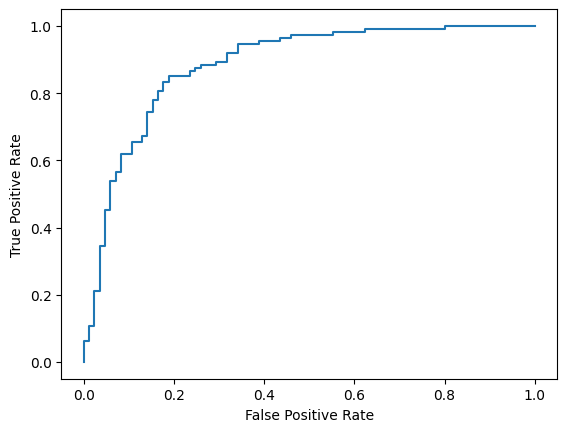
در نهایت، میتوانید به منحنی ROC نیز نگاه کنید تا با استفاده از آستانههای امتیازدهی مختلف، خطاهای احتمالی پیشبینی را دریافت کنید.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
<sklearn.metrics._plot.roc_curve.RocCurveDisplay at 0x7eb4d130ef20>
ضمیمه
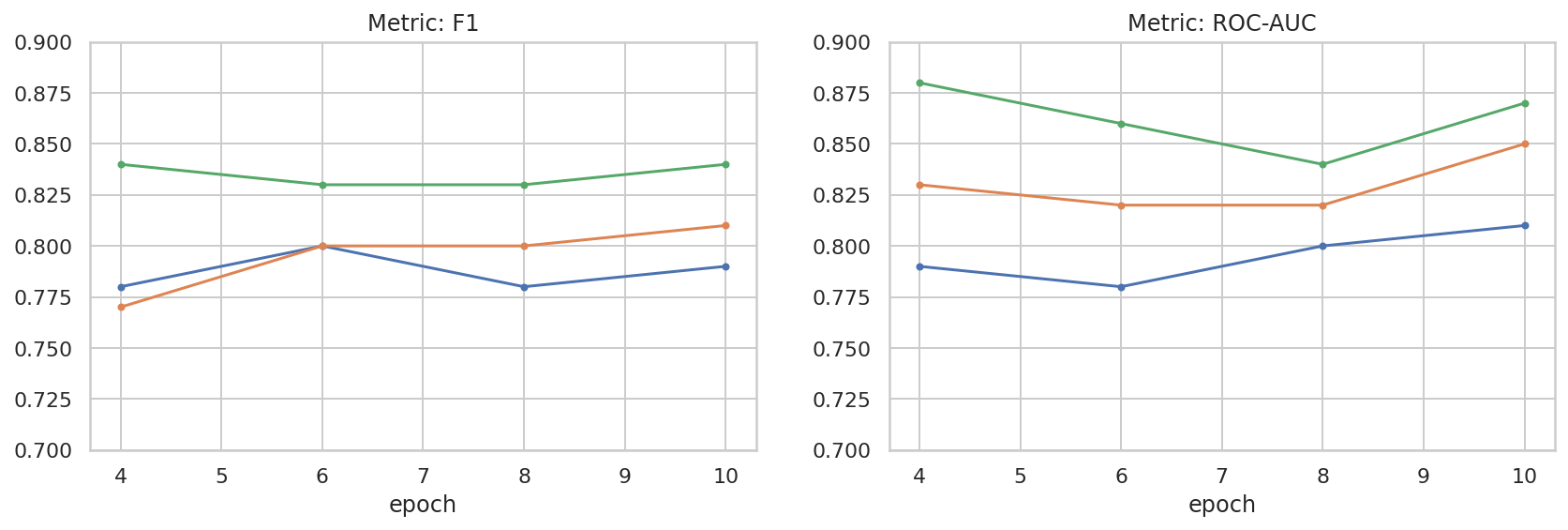
ما برخی از کاوش های اساسی در فضای فراپارامتر انجام داده ایم تا به درک بهتری از رابطه بین اندازه مجموعه داده و عملکرد کمک کنیم. طرح زیر را ببینید.
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid")
results_f1 = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'f1', 'score': 0.84},
{'training_size': 800, 'epoch': 6, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 8, 'metric': 'f1', 'score': 0.83},
{'training_size': 800, 'epoch': 10, 'metric': 'f1', 'score': 0.84},
{'training_size': 400, 'epoch': 4, 'metric': 'f1', 'score': 0.77},
{'training_size': 400, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 8, 'metric': 'f1', 'score': 0.80},
{'training_size': 400, 'epoch': 10,'metric': 'f1', 'score': 0.81},
{'training_size': 200, 'epoch': 4, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 6, 'metric': 'f1', 'score': 0.80},
{'training_size': 200, 'epoch': 8, 'metric': 'f1', 'score': 0.78},
{'training_size': 200, 'epoch': 10, 'metric': 'f1', 'score': 0.79},
])
results_roc_auc = pd.DataFrame([
{'training_size': 800, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.88},
{'training_size': 800, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.86},
{'training_size': 800, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.84},
{'training_size': 800, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.87},
{'training_size': 400, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.83},
{'training_size': 400, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.82},
{'training_size': 400, 'epoch': 10,'metric': 'roc-auc', 'score': 0.85},
{'training_size': 200, 'epoch': 4, 'metric': 'roc-auc', 'score': 0.79},
{'training_size': 200, 'epoch': 6, 'metric': 'roc-auc', 'score': 0.78},
{'training_size': 200, 'epoch': 8, 'metric': 'roc-auc', 'score': 0.80},
{'training_size': 200, 'epoch': 10, 'metric': 'roc-auc', 'score': 0.81},
])
plot_opts = dict(style='.-', ylim=(0.7, 0.9))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4))
process_results_df = lambda df: df.set_index('epoch').groupby('training_size')['score']
process_results_df(results_f1).plot(title='Metric: F1', ax=ax1, **plot_opts)
process_results_df(results_roc_auc).plot(title='Metric: ROC-AUC', ax=ax2, **plot_opts)
fig.show()