
7 de novembro de 2024
Supercharging AI Coding Assistants with Gemini Models' Long Context

Uma das fronteiras mais interessantes na aplicação de janelas de contexto longo é a geração e compreensão de código. Bases de código grandes exigem um entendimento profundo de relações e dependências complexas, algo que os modelos tradicionais de IA têm dificuldade de compreender. Ao aumentar a quantidade de código com grandes janelas de contexto, podemos alcançar um novo nível de precisão e utilidade na geração e compreensão de código.
Fizemos uma parceria com a Sourcegraph, criadora do assistente de programação com IA Cody, que oferece suporte a LLMs como o Gemini 1.5 Pro e Flash, para explorar o potencial de janelas de contexto longas em cenários de programação do mundo real. O foco da Sourcegraph em integrar a pesquisa e a inteligência de código à geração de código de IA, além da implantação bem-sucedida do Cody em empresas com bases de código grandes e complexas, como Palo Alto Networks e Leidos, a tornaram o parceiro ideal para essa exploração.
Abordagem e resultados da Sourcegraph
A Sourcegraph comparou a performance do Cody com uma janela de contexto de 1 milhão de tokens (usando o Gemini 1.5 Flash do Google) com a versão de produção. Essa comparação direta permitiu isolar os benefícios do contexto expandido. Eles se concentraram em respostas a perguntas técnicas, uma tarefa crucial para desenvolvedores que trabalham com grandes bases de código. Eles usaram um conjunto de dados de perguntas difíceis que exigiam um entendimento profundo do código.
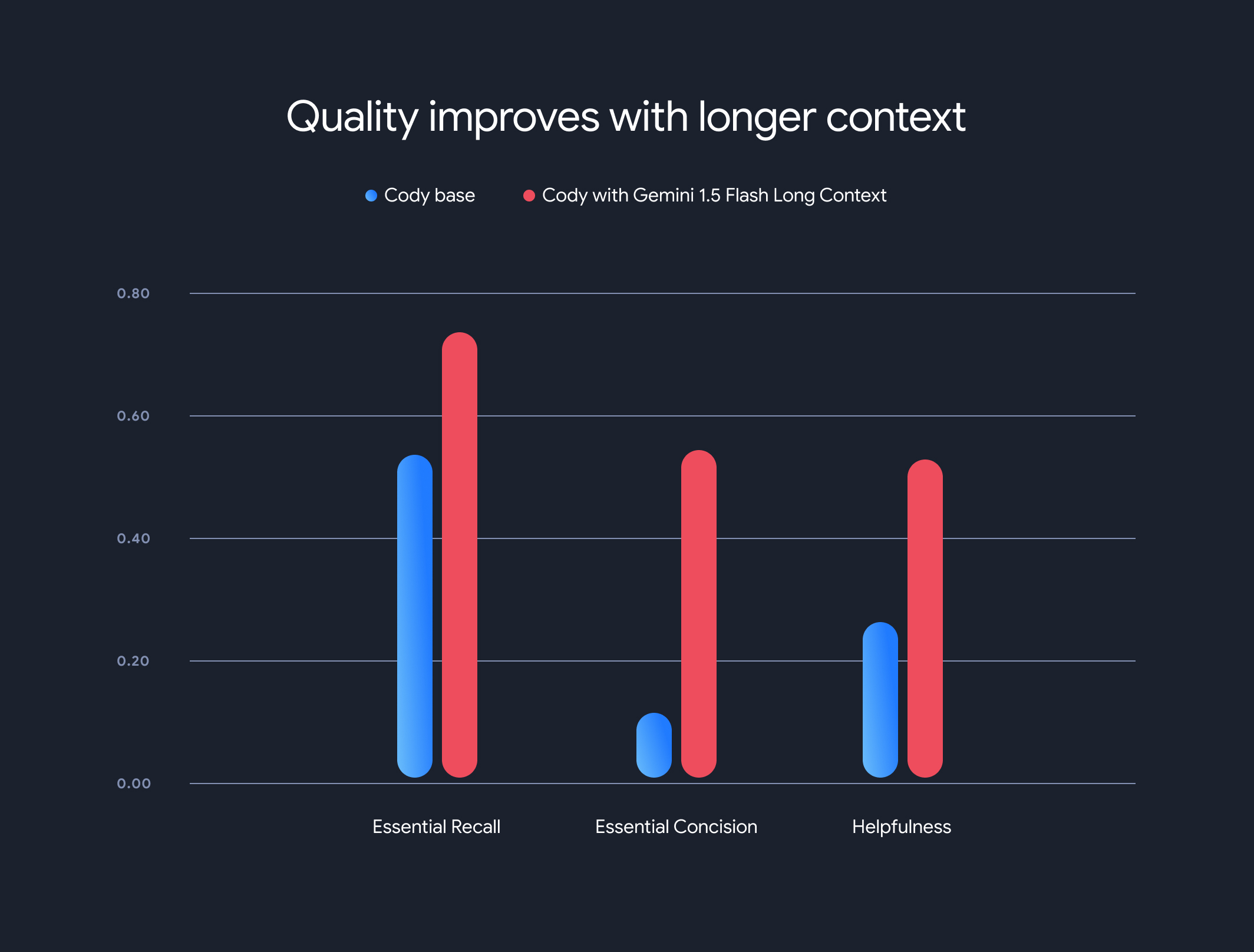
Os resultados foram impressionantes. Três dos principais comparativos de mercado do Sourcegraph (Essential Recall, Essential Concision e Helpfulness) demonstraram melhorias significativas ao usar o contexto mais longo.
Recall essencial: a proporção de fatos cruciais na resposta aumentou substancialmente.
Concisão essencial: a proporção de fatos essenciais normalizada pelo tamanho da resposta também melhorou, indicando respostas mais concisas e relevantes.
Utilidade: a pontuação geral de utilidade, normalizada pelo tamanho da resposta, aumentou significativamente, indicando uma experiência mais fácil de usar.
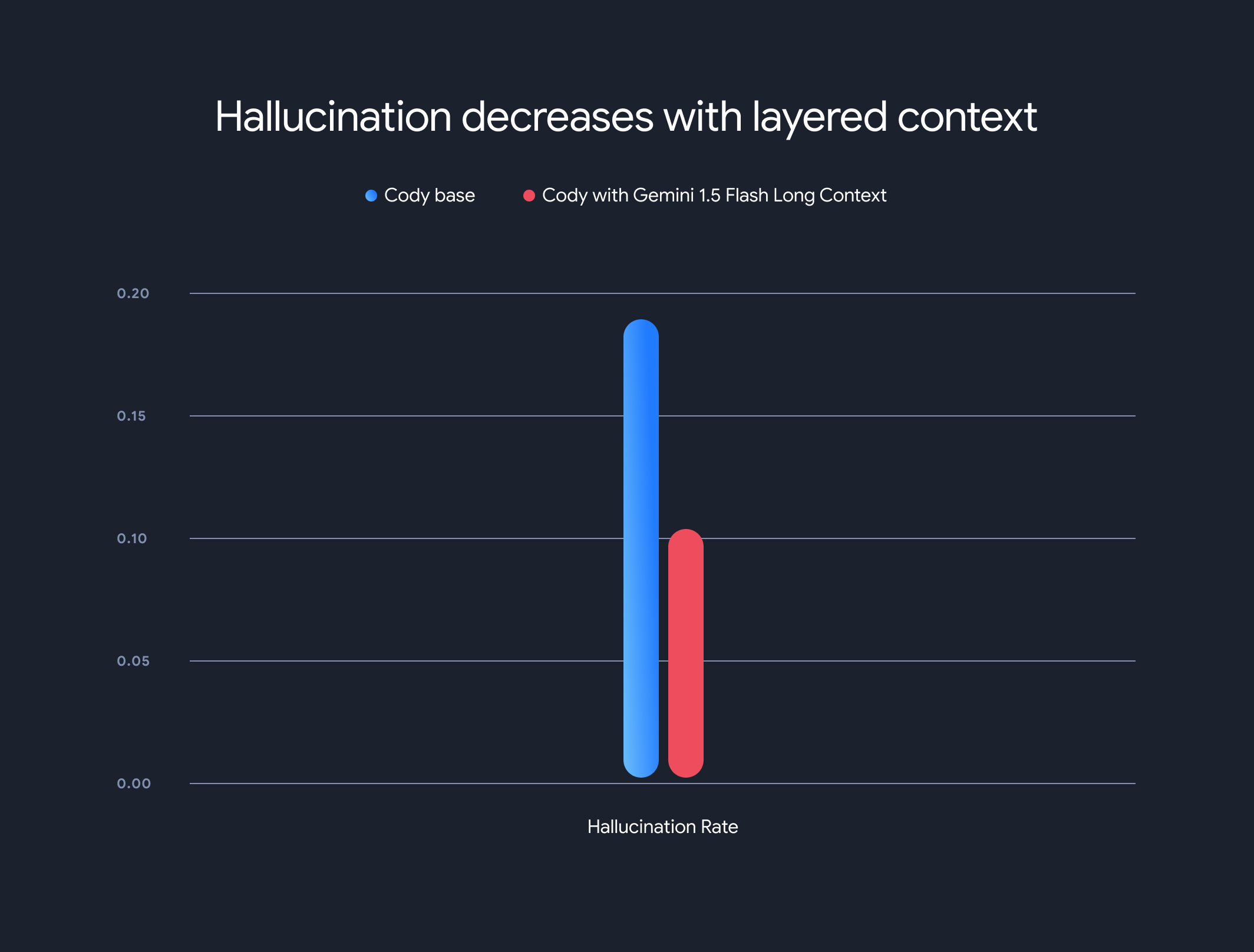
Além disso, o uso de modelos de contexto longo reduziu drasticamente a taxa geral de alucinação (a geração de informações factualmente incorretas). A taxa de alucinação diminuiu de 18,97% para 10,48%, uma melhoria significativa na acurácia e na confiabilidade.
Compensações e direção futura
Embora os benefícios do contexto longo sejam significativos, há desvantagens. O tempo até o primeiro token aumenta linearmente com o tamanho do contexto. Para reduzir esse problema, o Sourcegraph implementou um mecanismo de pré-busca e uma arquitetura de modelo de contexto em camadas para o armazenamento em cache do estado de execução do modelo. Com os modelos de contexto longo do Gemini 1.5 Flash e Pro, isso otimizou o tempo até o primeiro token de 30 a 40 segundos para cerca de 5 segundos em contextos de 1 MB, uma melhoria considerável para geração de código em tempo real e assistência técnica.
Essa colaboração mostra o potencial transformador dos modelos de contexto longo na revolução da compreensão e geração de código. Estamos animados em fazer parceria com empresas como a Sourcegraph para continuar desbloqueando ainda mais aplicativos e paradigmas inovadores com grandes janelas de contexto.
Para saber mais sobre as metodologias de avaliação, comparativos de mercado e análises detalhadas do Sourcegraph, incluindo exemplos ilustrativos, confira a postagem detalhada no blog (em inglês).
Estudos de caso relacionados

AgentOps
Saiba como a AgentOps oferece observabilidade de agentes econômicos e eficientes com tecnologia de LLM para empresas que usam a API Gemini.

Subcamada
Saiba como a estrutura de agente de IA baseada em Ruby capacita as equipes de desenvolvedores a serem mais produtivas com o poder dos modelos do Gemini.

Salas
Aproveite interações mais ricas com avatares usando os recursos de texto e áudio do Gemini 2.0