
Mit den LiteRT-Benchmark-Tools werden Statistiken für die folgenden wichtigen Leistungsmesswerte gemessen und berechnet:
- Initialisierungszeit
- Inferenzzeit des Warm-up-Zustands
- Inferenzzeit des stabilen Zustands
- Arbeitsspeichernutzung während der Initialisierungszeit
- Gesamte Arbeitsspeichernutzung
Die Benchmark-Tools sind als Benchmark-Apps für Android und iOS sowie als vorkompilierte Befehlszeilen-Binärdateien verfügbar. Sie alle verwenden dieselbe Logik zur Messung der Kernleistung. Die verfügbaren Optionen und Ausgabeformate unterscheiden sich aufgrund der Unterschiede in der Laufzeitumgebung leicht.
Android-Benchmark-App
Eine Android-Benchmark-App, die auf der Interpreter API v1 basiert, ist ebenfalls verfügbar. So lässt sich besser einschätzen, wie das Modell in einer Android-App funktionieren würde. Die Zahlen aus dem Benchmark-Tool weichen jedoch immer noch leicht von den Ergebnissen ab, die beim Ausführen der Inferenz mit dem Modell in der tatsächlichen App erzielt werden.
Diese Android-Benchmark-App hat keine Benutzeroberfläche. Installieren und führen Sie es mit dem Befehl adb aus und rufen Sie die Ergebnisse mit dem Befehl adb logcat ab.
App herunterladen oder erstellen
Laden Sie die nächtlichen vorkompilierten Android-Benchmark-Apps über die folgenden Links herunter:
Für Android-Benchmark-Apps, die TF-Vorgänge über den Flex-Delegate unterstützen, verwenden Sie die folgenden Links:
Sie können die App auch aus dem Quellcode erstellen. Folgen Sie dazu dieser Anleitung.
Benchmark vorbereiten
Bevor Sie die Benchmark-App ausführen, installieren Sie die App und übertragen Sie die Modelldatei auf das Gerät:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Benchmark ausführen
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph ist ein erforderlicher Parameter.
graph:string
Der Pfad zur TFLite-Modelldatei.
Sie können weitere optionale Parameter für die Ausführung des Benchmarks angeben.
num_threads:int(Standardwert: 1)
Die Anzahl der Threads, die zum Ausführen des TFLite-Interpreters verwendet werden sollen.use_gpu:bool(Standardwert: „false“)
GPU-Delegat verwenden.use_xnnpack:bool(Standard=false)
Verwenden Sie XNNPACK-Delegate.
Je nach verwendetem Gerät sind einige dieser Optionen möglicherweise nicht verfügbar oder haben keine Auswirkungen. Weitere Leistungsparameter, die Sie mit der Benchmark-App ausführen können, finden Sie unter Parameter.
Sehen Sie sich die Ergebnisse mit dem Befehl logcat an:
adb logcat | grep "Inference timings"
Die Benchmark-Ergebnisse werden so angegeben:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
iOS-Benchmark-App
Wenn Sie Benchmarks auf einem iOS-Gerät ausführen möchten, müssen Sie die App aus dem Quellcode erstellen.
Legen Sie die LiteRT-Modelldatei in das Verzeichnis benchmark_data des Quellbaums und ändern Sie die Datei benchmark_params.json. Diese Dateien werden in der App gebündelt und die App liest Daten aus dem Verzeichnis. Eine ausführliche Anleitung finden Sie in der iOS-Benchmark-App.
Leistungsbenchmarks für bekannte Modelle
In diesem Abschnitt finden Sie LiteRT-Leistungsbenchmarks für die Ausführung bekannter Modelle auf einigen Android- und iOS-Geräten.
Android-Leistungsbenchmarks
Diese Leistungsbenchmark-Zahlen wurden mit dem nativen Benchmark-Binärprogramm generiert.
Bei Android-Benchmarks wird die CPU-Affinität so festgelegt, dass große Kerne auf dem Gerät verwendet werden, um die Varianz zu verringern (weitere Informationen).
Es wird davon ausgegangen, dass Modelle in das Verzeichnis /data/local/tmp/tflite_models heruntergeladen und entzippt wurden. Die Benchmark-Binärdatei wird gemäß dieser Anleitung erstellt und befindet sich im Verzeichnis /data/local/tmp.
So führen Sie den Benchmark aus:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Wenn Sie den GPU-Delegate verwenden möchten, legen Sie --use_gpu=true fest.
Die Leistungsdaten unten wurden auf Android 10 gemessen.
| Modellname | Gerät | CPU, 4 Threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5,0 ms | --- | |
| NASNet Mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
iOS-Leistungsbenchmarks
Diese Leistungsbenchmarkzahlen wurden mit der iOS-Benchmark-App generiert.
Für iOS-Benchmarks wurde die Benchmark-App so geändert, dass sie das entsprechende Modell enthält, und benchmark_params.json wurde so geändert, dass num_threads auf 2 gesetzt wird. Für die Verwendung des GPU-Delegaten wurden "use_gpu" : "1"- und "gpu_wait_type" : "aggressive"-Optionen zu benchmark_params.json hinzugefügt.
| Modellname | Gerät | CPU, 2 Threads | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet Mobile | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
LiteRT-Interna verfolgen
LiteRT-Interna in Android nachverfolgen
Interne Ereignisse aus dem LiteRT-Interpreter einer Android-App können mit Android-Tracing-Tools erfasst werden. Es handelt sich um dieselben Ereignisse wie bei der Android Trace API. Die erfassten Ereignisse aus Java-/Kotlin-Code werden also zusammen mit internen LiteRT-Ereignissen angezeigt.
Beispiele für Ereignisse:
- Operatoraufruf
- Diagramm von einem Delegierten ändern lassen
- Tensor-Zuweisung
In dieser Anleitung werden der Android Studio CPU Profiler und die System Tracing App behandelt. Weitere Optionen finden Sie im Perfetto-Befehlszeilentool oder im Systrace-Befehlszeilentool.
Trace-Ereignisse in Java-Code einfügen
Dies ist ein Code-Snippet aus der Beispiel-App Bildklassifizierung. Der LiteRT-Interpreter wird im Abschnitt recognizeImage/runInference ausgeführt. Dieser Schritt ist optional, aber hilfreich, um zu sehen, wo der Inferenzaufruf erfolgt.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
LiteRT-Tracing aktivieren
Wenn Sie LiteRT-Tracing aktivieren möchten, legen Sie das Android-Systemattribut debug.tflite.trace vor dem Starten der Android-App auf 1 fest.
adb shell setprop debug.tflite.trace 1
Wenn diese Property bei der Initialisierung des LiteRT-Interpreters festgelegt wurde, werden Schlüsselereignisse (z.B. Operatoraufrufe) aus dem Interpreter protokolliert.
Nachdem Sie alle Traces erfasst haben, deaktivieren Sie das Tracing, indem Sie den Property-Wert auf 0 setzen.
adb shell setprop debug.tflite.trace 0
CPU-Profiler in Android Studio
So erfassen Sie Traces mit dem CPU Profiler von Android Studio:
Wählen Sie in den Menüs oben Run > Profile 'app' (Ausführen > Profil für „App“ erstellen) aus.
Klicken Sie im Profiler-Fenster auf eine beliebige Stelle im CPU-Zeitachsendiagramm.
Wählen Sie unter den CPU-Profiling-Modi „Systemaufrufe verfolgen“ aus.
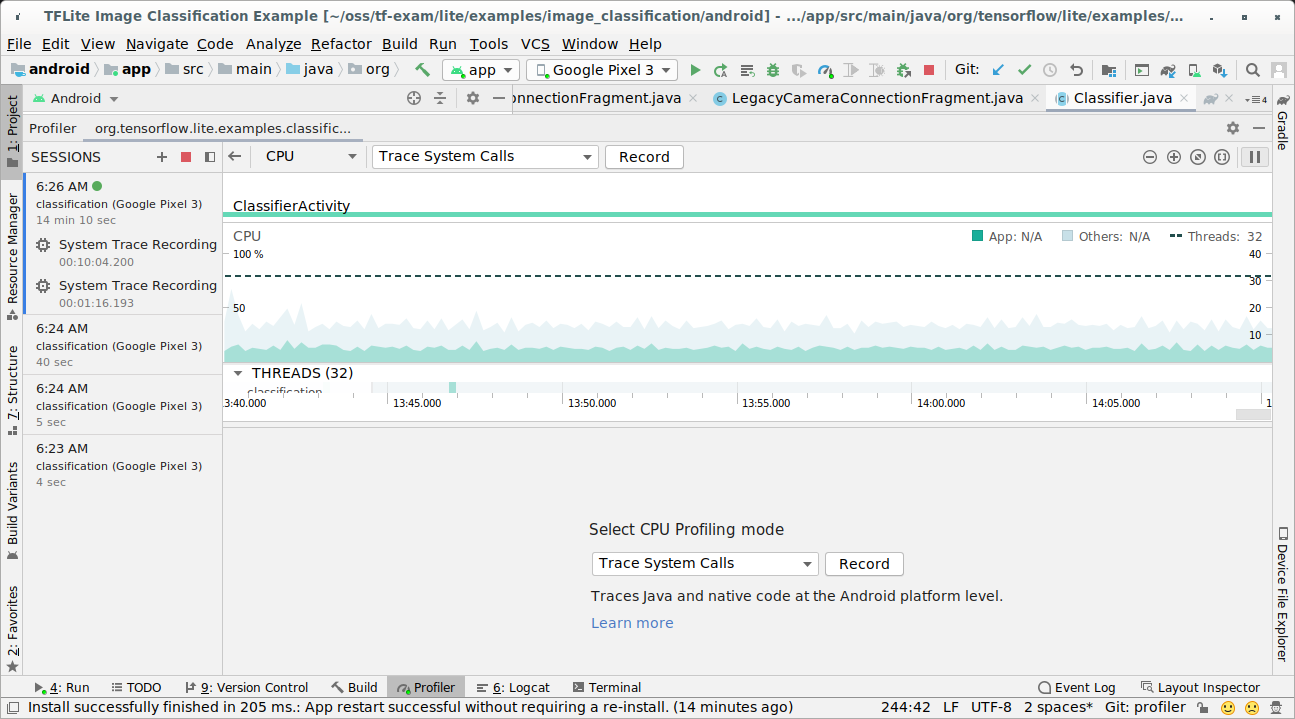
Drücken Sie die Schaltfläche „Aufzeichnen“.
Drücken Sie die Schaltfläche „Beenden“.
Untersuchen Sie das Trace-Ergebnis.
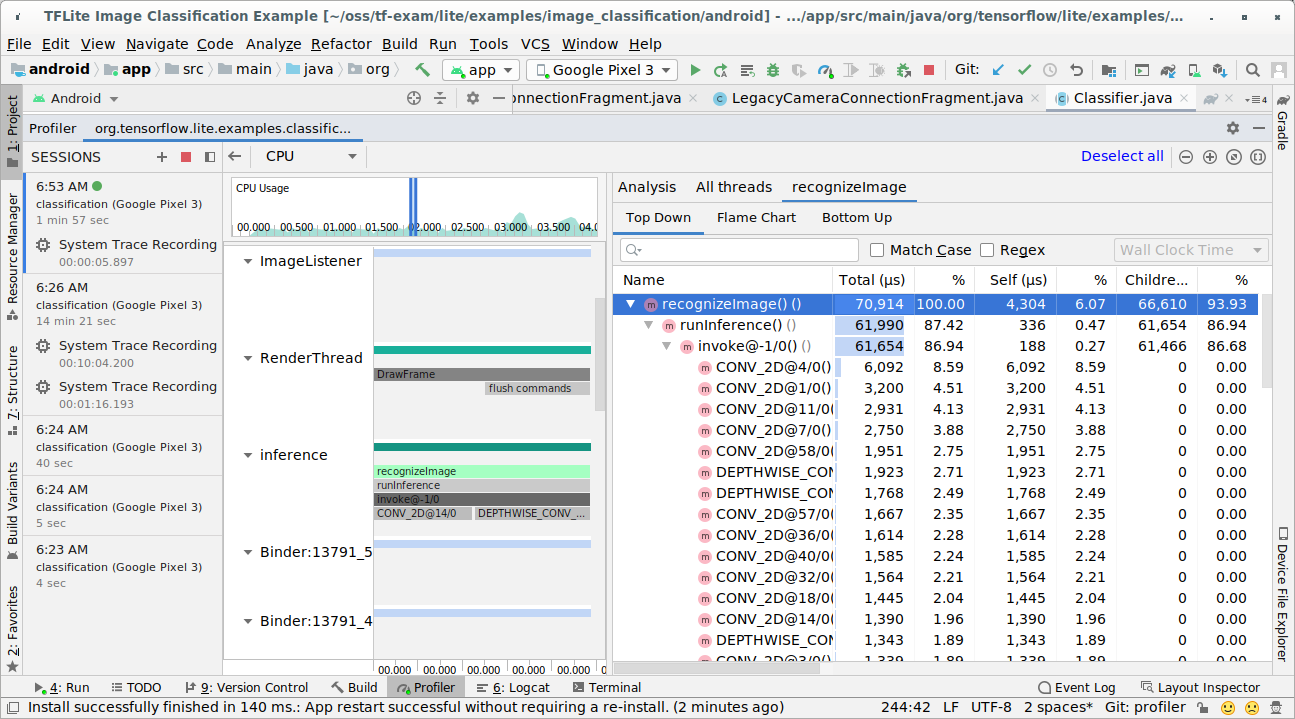
In diesem Beispiel sehen Sie die Hierarchie der Ereignisse in einem Thread und Statistiken für jede Operatorzeit sowie den Datenfluss der gesamten App zwischen den Threads.
App „Ablaufverfolgung“
Sie können auch Traces ohne Android Studio erfassen. Folgen Sie dazu der Anleitung unter System Tracing App.
In diesem Beispiel wurden dieselben TFLite-Ereignisse erfasst und je nach Version des Android-Geräts im Perfetto- oder Systrace-Format gespeichert. Die erfassten Trace-Dateien können in der Perfetto-UI geöffnet werden.
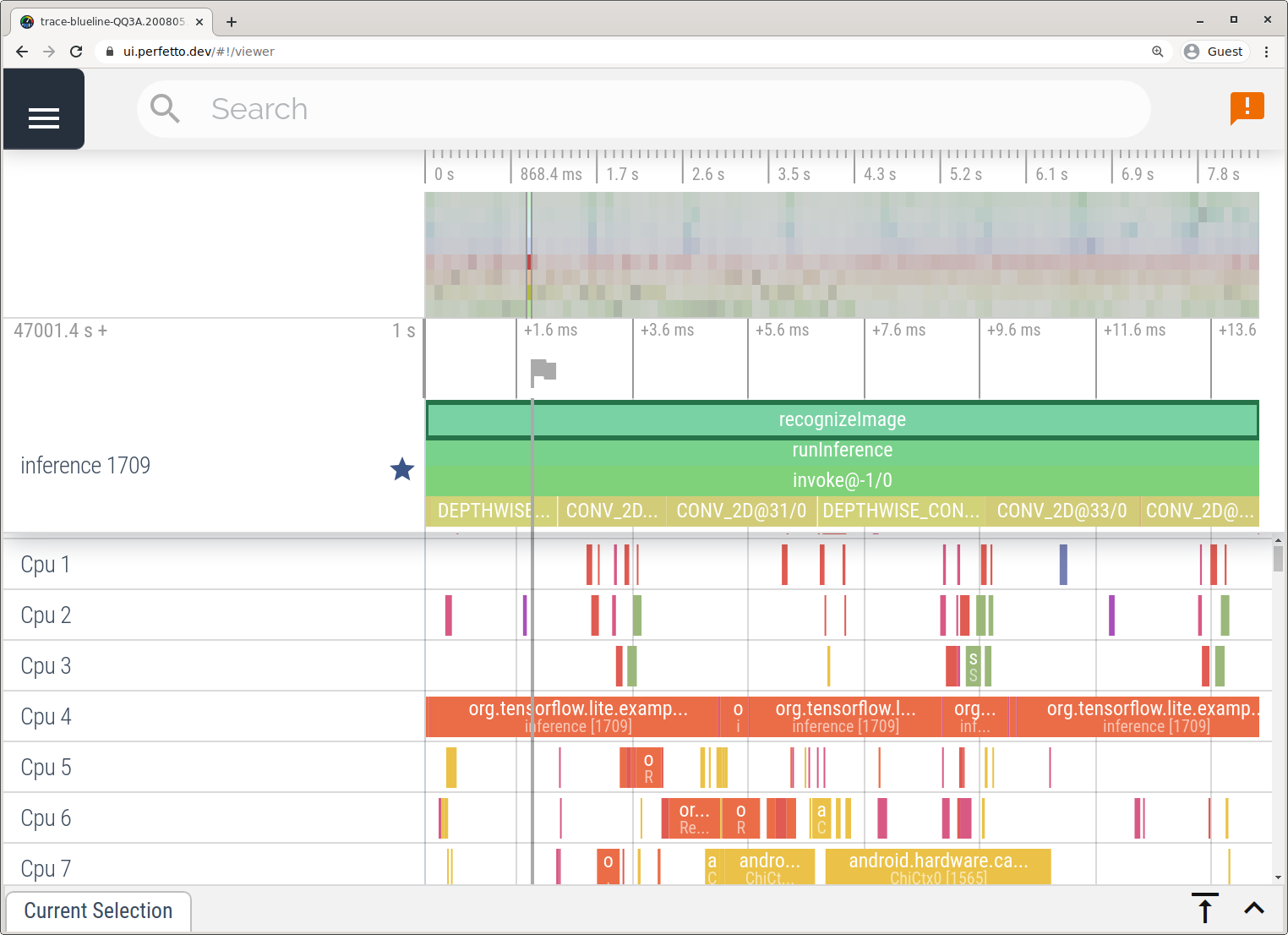
LiteRT-Interna in iOS nachverfolgen
Interne Ereignisse aus dem LiteRT-Interpreter einer iOS-App können mit dem Instruments-Tool erfasst werden, das in Xcode enthalten ist. Es handelt sich um die iOS-signpost-Ereignisse. Die erfassten Ereignisse aus Swift-/Objective-C-Code werden also zusammen mit internen LiteRT-Ereignissen angezeigt.
Beispiele für Ereignisse:
- Operatoraufruf
- Diagramm von einem Delegierten ändern lassen
- Tensor-Zuweisung
LiteRT-Tracing aktivieren
Legen Sie die Umgebungsvariable debug.tflite.trace mit den folgenden Schritten fest:
Wählen Sie in den oberen Menüs von Xcode Product > Scheme > Edit Scheme… (Produkt > Schema > Schema bearbeiten…) aus.
Klicken Sie im linken Bereich auf „Profil“.
Deaktivieren Sie das Kästchen „Use the Run action's arguments and environment variables“ (Argumente und Umgebungsvariablen der Run-Aktion verwenden).
Fügen Sie
debug.tflite.traceim Abschnitt „Umgebungsvariablen“ hinzu.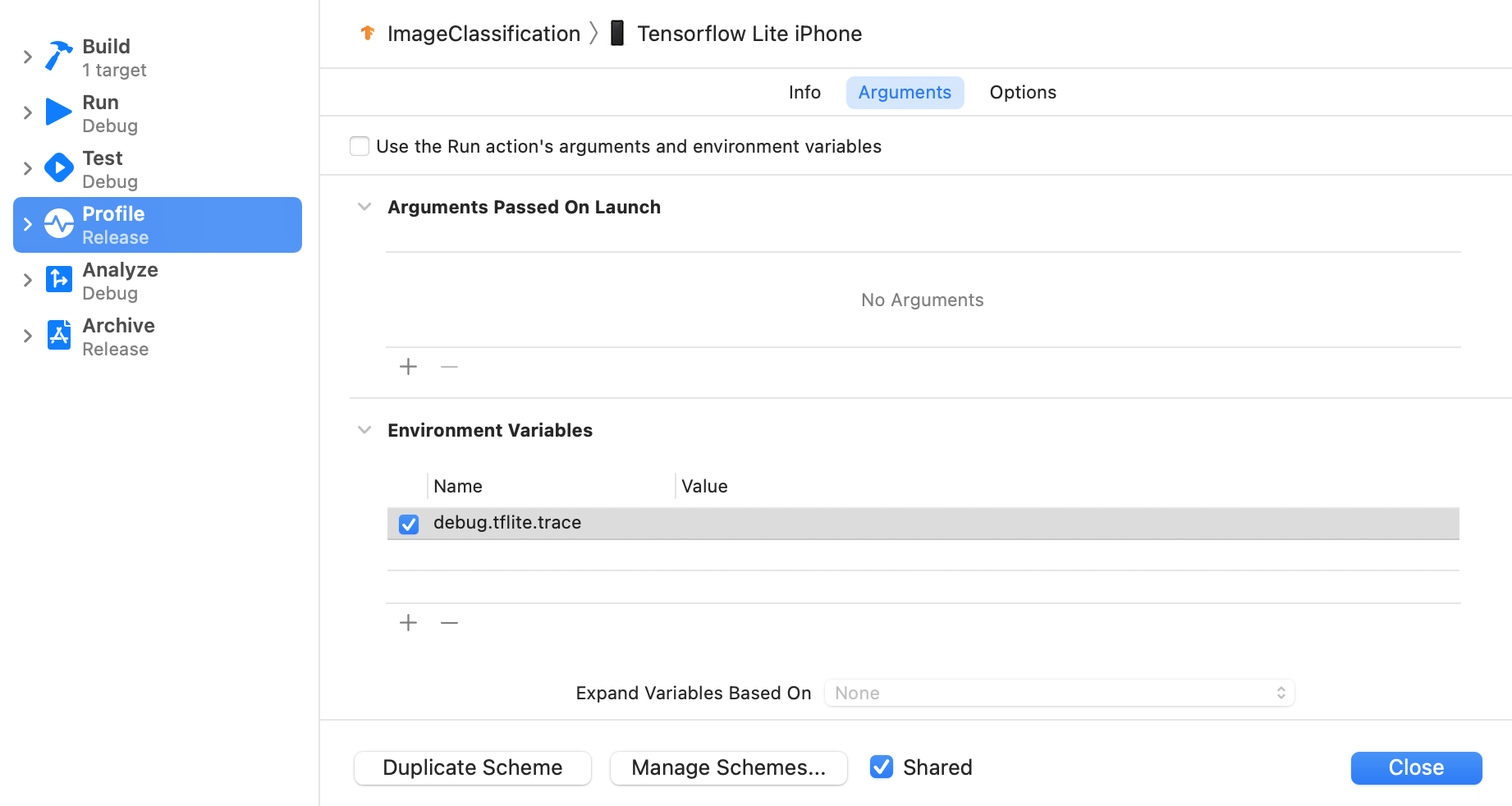
Wenn Sie LiteRT-Ereignisse beim Profiling der iOS-App ausschließen möchten, deaktivieren Sie die Ablaufverfolgung, indem Sie die Umgebungsvariable entfernen.
Xcode Instruments
So erfassen Sie Traces:
Wählen Sie in den oberen Menüs von Xcode Product > Profile aus.
Klicken Sie beim Starten des Instruments-Tools unter Profiling-Vorlagen auf Logging (Protokollierung).
Drücken Sie die Schaltfläche „Start“.
Drücken Sie die Schaltfläche „Beenden“.
Klicken Sie auf „os_signpost“, um die Elemente des OS Logging-Subsystems zu maximieren.
Klicken Sie auf das Betriebssystem-Subsystem „org.tensorflow.lite“.
Untersuchen Sie das Trace-Ergebnis.
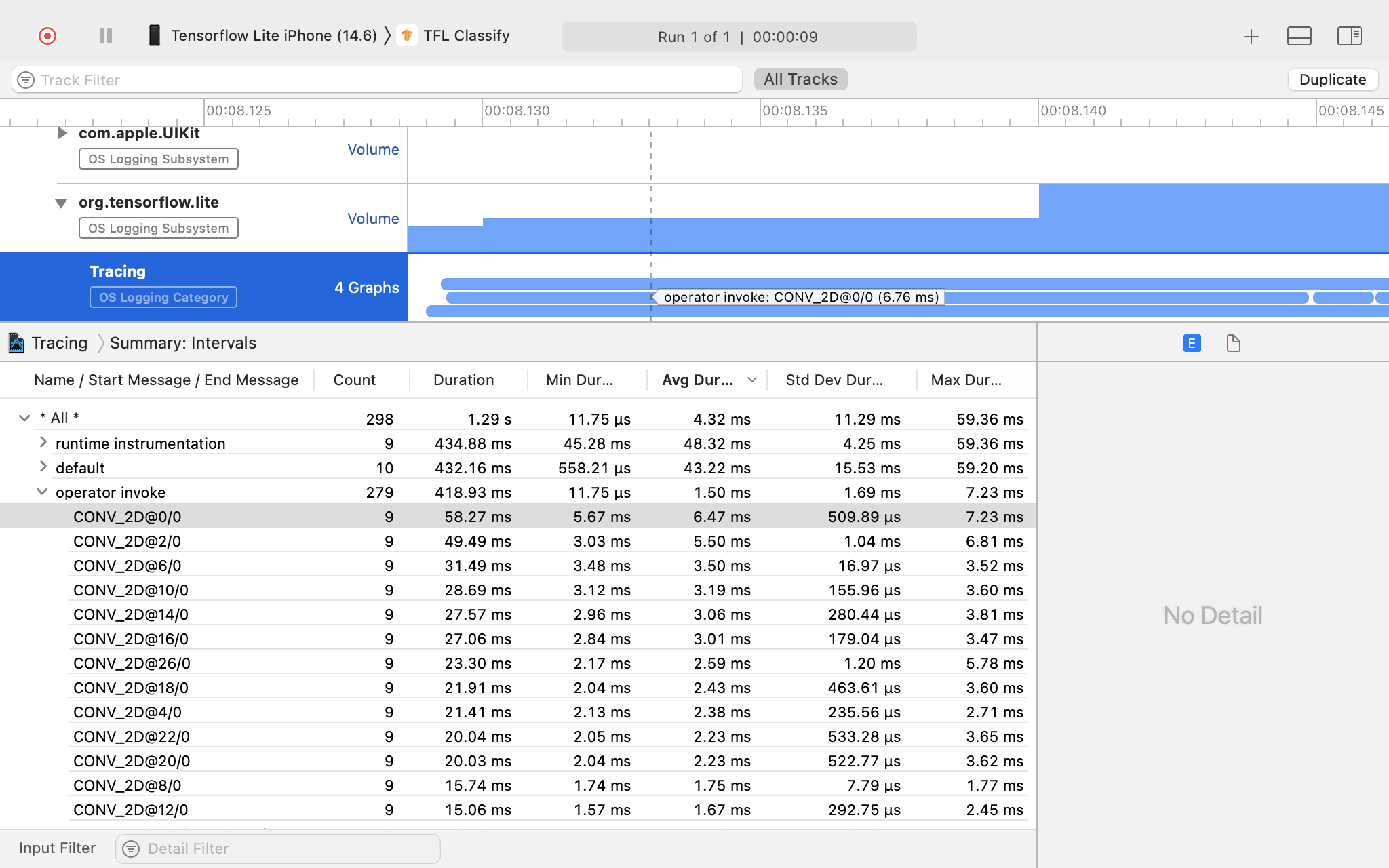
In diesem Beispiel sehen Sie die Hierarchie der Ereignisse und Statistiken für jede Bedienerzeit.
Tracing-Daten verwenden
Mithilfe der Tracing-Daten können Sie Leistungsengpässe identifizieren.
Hier sind einige Beispiele für Statistiken, die Sie aus dem Profiler erhalten können, und potenzielle Lösungen zur Leistungsverbesserung:
- Wenn die Anzahl der verfügbaren CPU-Kerne kleiner ist als die Anzahl der Inferenz-Threads, kann der CPU-Planungsaufwand zu einer schlechten Leistung führen. Sie können andere CPU-intensive Aufgaben in Ihrer Anwendung neu planen, um Überschneidungen mit der Modellinferenz zu vermeiden, oder die Anzahl der Interpreter-Threads anpassen.
- Wenn die Operatoren nicht vollständig delegiert werden, werden einige Teile des Modellgraphen auf der CPU anstelle des erwarteten Hardwarebeschleunigers ausgeführt. Sie können die nicht unterstützten Operatoren durch ähnliche unterstützte Operatoren ersetzen.