
Narzędzia testu porównawczego LiteRT mierzą i obliczają statystyki dotyczące tych ważnych danych o skuteczności:
- Czas inicjowania
- Czas wnioskowania w stanie wczytywania danych z wyprzedzeniem
- Czas wnioskowania w stanie ustalonym
- Wykorzystanie pamięci podczas inicjowania
- Ogólne wykorzystanie pamięci
Narzędzia do testów porównawczych są dostępne jako aplikacje do testów porównawczych na Androida i iOS oraz jako gotowe pliki binarne wiersza poleceń. Wszystkie korzystają z tej samej podstawowej logiki pomiaru wydajności. Pamiętaj, że dostępne opcje i formaty wyjściowe nieco się różnią ze względu na różnice w środowisku wykonawczym.
Aplikacja do testów porównawczych na Androida
Dostępna jest też aplikacja do testów porównawczych na Androida oparta na interfejsie Interpreter API w wersji 1. To lepszy wskaźnik tego, jak model będzie działać w aplikacji na Androida. Liczby z narzędzia do testów porównawczych będą się jednak nadal nieznacznie różnić od wyników wnioskowania z użyciem modelu w rzeczywistej aplikacji.
Ta aplikacja testowa na Androida nie ma interfejsu użytkownika. Zainstaluj i uruchom go za pomocą polecenia adb, a wyniki uzyskaj za pomocą polecenia adb logcat.
Pobieranie lub tworzenie aplikacji
Pobierz gotowe aplikacje do testów porównawczych Androida z dnia poprzedniego, korzystając z tych linków:
W przypadku aplikacji do testów porównawczych na Androida, które obsługują operacje TF za pomocą delegata Flex, skorzystaj z tych linków:
Możesz też skompilować aplikację ze źródeł, postępując zgodnie z tymi instrukcjami.
Przygotuj test porównawczy
Przed uruchomieniem aplikacji testu porównawczego zainstaluj ją i prześlij plik modelu na urządzenie w ten sposób:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Przeprowadź test porównawczy
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph to wymagany parametr.
graph:string
Ścieżka do pliku modelu TFLite.
Możesz określić więcej opcjonalnych parametrów do uruchomienia testu porównawczego.
num_threads:int(domyślnie 1)
Liczba wątków do uruchomienia interpretera TFLite.use_gpu:bool(domyślnie: false)
Użyj delegata GPU.use_xnnpack:bool(domyślnie=false)
Użyj delegata XNNPACK.
W zależności od używanego urządzenia niektóre z tych opcji mogą być niedostępne lub nie działać. Więcej parametrów skuteczności, które możesz sprawdzić za pomocą aplikacji testowej, znajdziesz w sekcji Parametry.
Wyświetl wyniki za pomocą polecenia logcat:
adb logcat | grep "Inference timings"
Wyniki testu porównawczego są podawane w postaci:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Aplikacja testowa na iOS
Aby uruchomić testy porównawcze na urządzeniu z iOS, musisz skompilować aplikację ze źródła.
Umieść plik modelu LiteRT w katalogu benchmark_data w drzewie źródłowym i zmodyfikuj plik benchmark_params.json. Te pliki są spakowane w aplikacji, a aplikacja odczytuje dane z katalogu. Szczegółowe instrukcje znajdziesz w aplikacji do testów porównawczych na iOS.
Testy porównawcze dotyczące skuteczności znanych modeli
W tej sekcji znajdziesz testy wydajności LiteRT podczas uruchamiania znanych modeli na niektórych urządzeniach z Androidem i iOS.
Testy porównawcze wydajności Androida
Te wyniki testów porównawczych skuteczności zostały wygenerowane za pomocą natywnego pliku binarnego testu porównawczego.
W przypadku testów porównawczych na Androida powinowactwo procesora jest ustawione tak, aby używać dużych rdzeni na urządzeniu, co zmniejsza wariancję (szczegóły znajdziesz tutaj).
Zakłada, że modele zostały pobrane i rozpakowane do katalogu /data/local/tmp/tflite_models. Plik binarny testu porównawczego jest tworzony zgodnie z tymi instrukcjami i zakłada się, że znajduje się w katalogu /data/local/tmp.
Aby uruchomić test porównawczy:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Aby uruchomić delegata GPU, ustaw --use_gpu=true.
Poniższe wartości wydajności zostały zmierzone na urządzeniu z Androidem 10.
| Nazwa modelu | Urządzenie | Procesor, 4 wątki | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5,0 ms | --- | |
| NASNet mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
Testy porównawcze dotyczące skuteczności w systemie iOS
Te wartości testu porównawczego skuteczności zostały wygenerowane za pomocą aplikacji testowej na iOS.
Aby przeprowadzić testy porównawcze na urządzeniach z iOS, zmodyfikowano aplikację testową, aby uwzględniała odpowiedni model, a w benchmark_params.json zmieniono wartość num_threads na 2. Aby używać delegata GPU, do benchmark_params.json dodano też opcje "use_gpu" : "1" i "gpu_wait_type" : "aggressive".
| Nazwa modelu | Urządzenie | Procesor, 2 wątki | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet mobile | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
Wewnętrzne działanie Trace LiteRT
Śledzenie wewnętrznych elementów LiteRT na Androidzie
Wewnętrzne zdarzenia z interpretera LiteRT w aplikacji na Androida mogą być rejestrowane przez narzędzia do śledzenia na Androidzie. Są to te same zdarzenia co w przypadku interfejsu Android Trace API, więc zarejestrowane zdarzenia z kodu w języku Java lub Kotlin są widoczne razem ze zdarzeniami wewnętrznymi LiteRT.
Przykłady zdarzeń:
- Wywołanie operatora
- Modyfikowanie wykresu przez delegata
- Przydzielanie tensorów
Wśród różnych opcji rejestrowania śladów ten przewodnik omawia Profiler CPU w Android Studio i aplikację Śledzenie systemu. Inne opcje znajdziesz w narzędziu wiersza poleceń Perfetto lub narzędziu wiersza poleceń Systrace.
Dodawanie zdarzeń logu czasu w kodzie Java
To fragment kodu z przykładowej aplikacji Klasyfikacja obrazów. Interpreter LiteRT działa w sekcji recognizeImage/runInference. Ten krok jest opcjonalny, ale przydaje się, aby zauważyć, gdzie jest wykonywane wywołanie wnioskowania.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Włącz śledzenie LiteRT
Aby włączyć śledzenie LiteRT, przed uruchomieniem aplikacji na Androida ustaw właściwość systemu Android debug.tflite.trace na 1.
adb shell setprop debug.tflite.trace 1
Jeśli ta właściwość została ustawiona podczas inicjowania interpretera LiteRT, będą śledzone kluczowe zdarzenia (np. wywołanie operatora) z interpretera.
Po zarejestrowaniu wszystkich śladów wyłącz śledzenie, ustawiając wartość właściwości na 0.
adb shell setprop debug.tflite.trace 0
CPU Profiler w Android Studio
Rejestruj ślady za pomocą profilera procesora w Android Studio, wykonując te czynności:
W menu u góry wybierz Uruchom > Profil „aplikacja”.
Gdy pojawi się okno Profilera, kliknij dowolne miejsce na osi czasu procesora.
Wybierz „Śledź wywołania systemowe” w trybach profilowania procesora.
Naciśnij przycisk „Nagrywaj”.
Naciśnij przycisk „Zatrzymaj”.
Sprawdź wynik śledzenia.
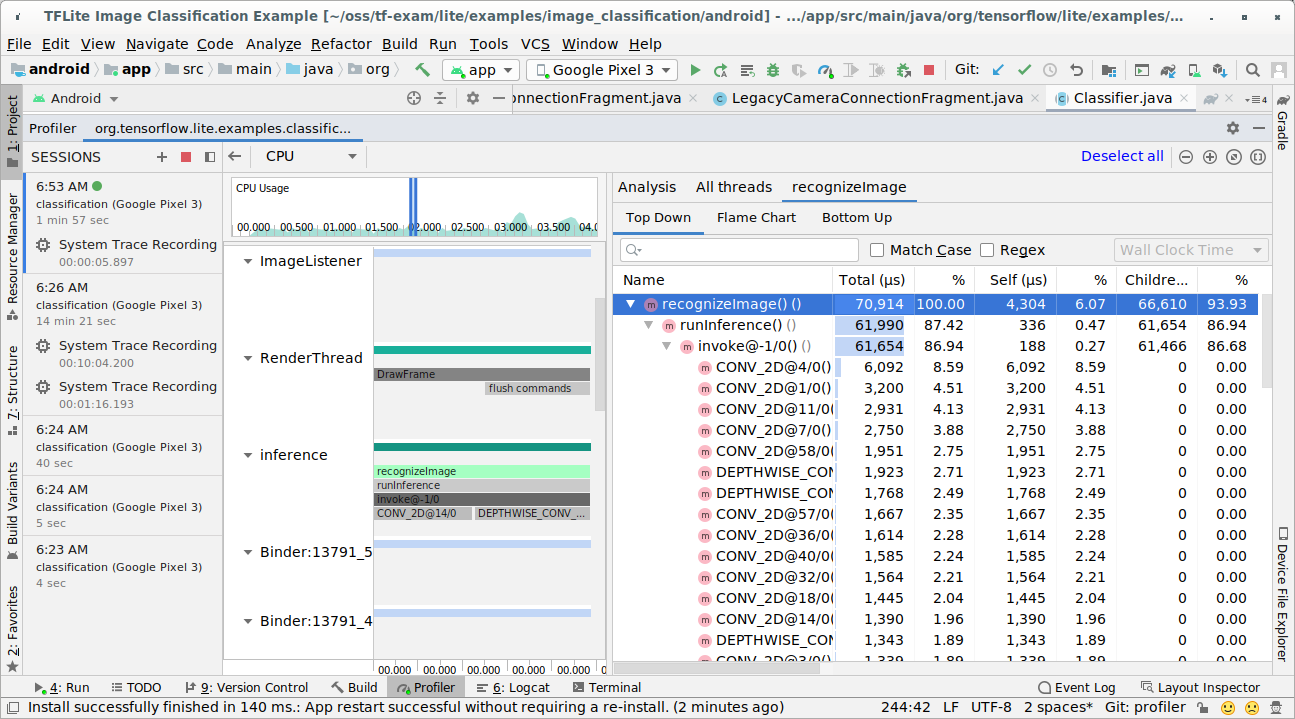
W tym przykładzie możesz zobaczyć hierarchię zdarzeń w wątku i statystyki dla każdego czasu operatora, a także przepływ danych w całej aplikacji między wątkami.
Aplikacja Śledzenie systemu
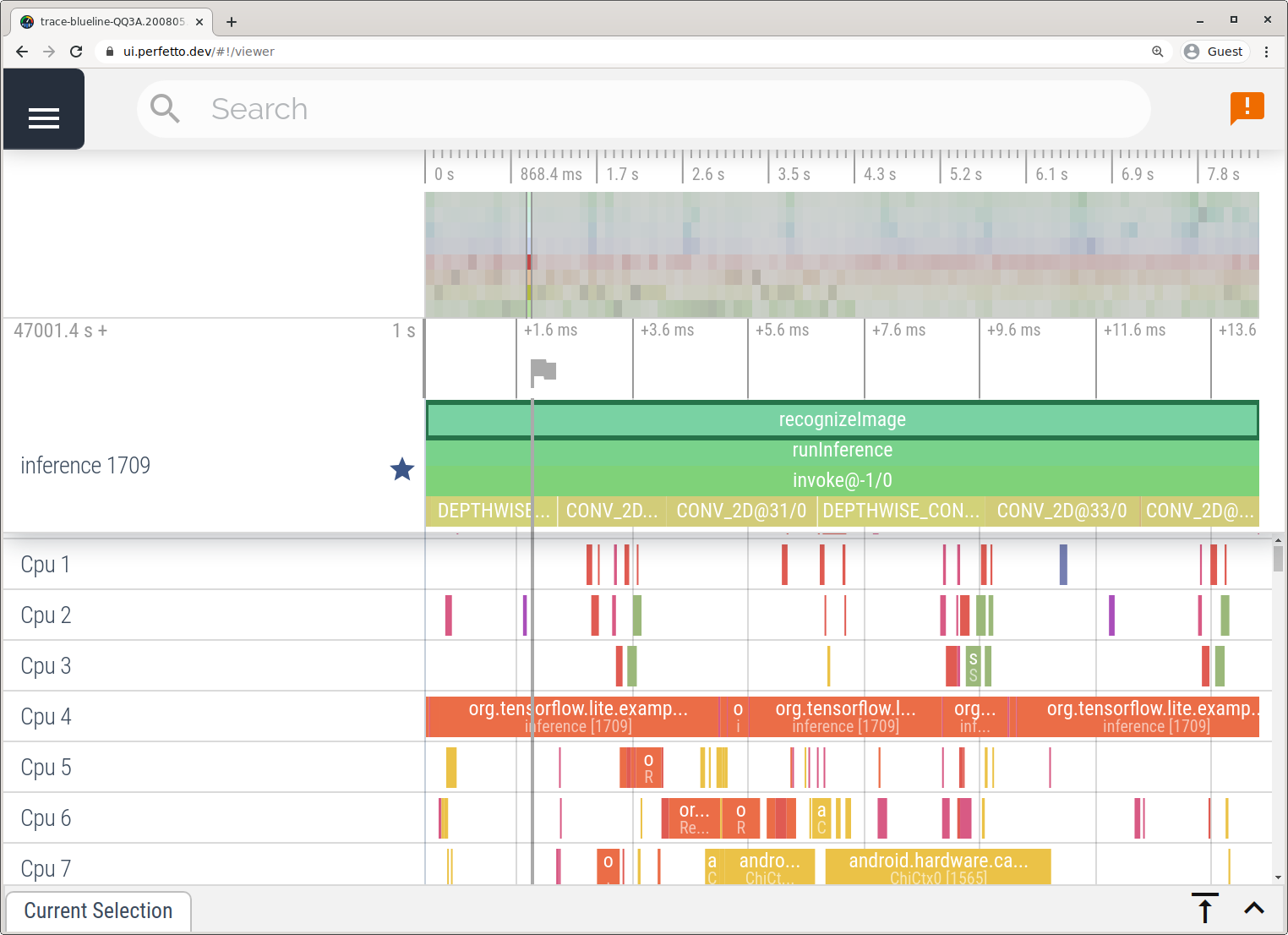
Rejestruj ślady bez użycia Android Studio, wykonując czynności opisane w artykule Aplikacja System Tracing.
W tym przykładzie te same zdarzenia TFLite zostały zarejestrowane i zapisane w formacie Perfetto lub Systrace w zależności od wersji urządzenia z Androidem. Zapisane pliki śledzenia można otwierać w Perfetto UI.
Śledzenie wewnętrznych elementów LiteRT na iOS
Wewnętrzne zdarzenia z interpretera LiteRT aplikacji na iOS można rejestrować za pomocą narzędzia Instruments dołączonego do Xcode. Są to zdarzenia signpost iOS, więc przechwycone zdarzenia z kodu Swift/Objective-C są widoczne razem ze zdarzeniami wewnętrznymi LiteRT.
Przykłady zdarzeń:
- Wywołanie operatora
- Modyfikowanie wykresu przez delegata
- Przydzielanie tensorów
Włącz śledzenie LiteRT
Ustaw zmienną środowiskową debug.tflite.trace, wykonując te czynności:
W menu u góry Xcode kliknij Product (Produkt) > Scheme (Schemat) > Edit Scheme (Edytuj schemat)….
W panelu po lewej stronie kliknij „Profil”.
Odznacz pole wyboru „Użyj argumentów i zmiennych środowiskowych działania Uruchom”.
Dodaj
debug.tflite.tracew sekcji „Zmienne środowiskowe”.
Jeśli podczas profilowania aplikacji na iOS chcesz wykluczyć zdarzenia LiteRT, wyłącz śledzenie, usuwając zmienną środowiskową.
XCode Instruments
Aby zarejestrować ślady, wykonaj te czynności:
W menu u góry w Xcode kliknij Product (Produkt) > Profile (Profil).
Gdy uruchomi się narzędzie Instruments, kliknij Logging (Logowanie) w szablonach profilowania.
Naciśnij przycisk „Start”.
Naciśnij przycisk „Zatrzymaj”.
Kliknij „os_signpost”, aby rozwinąć elementy podsystemu rejestrowania systemu operacyjnego.
Kliknij podsystem rejestrowania systemu operacyjnego „org.tensorflow.lite”.
Sprawdź wynik śledzenia.
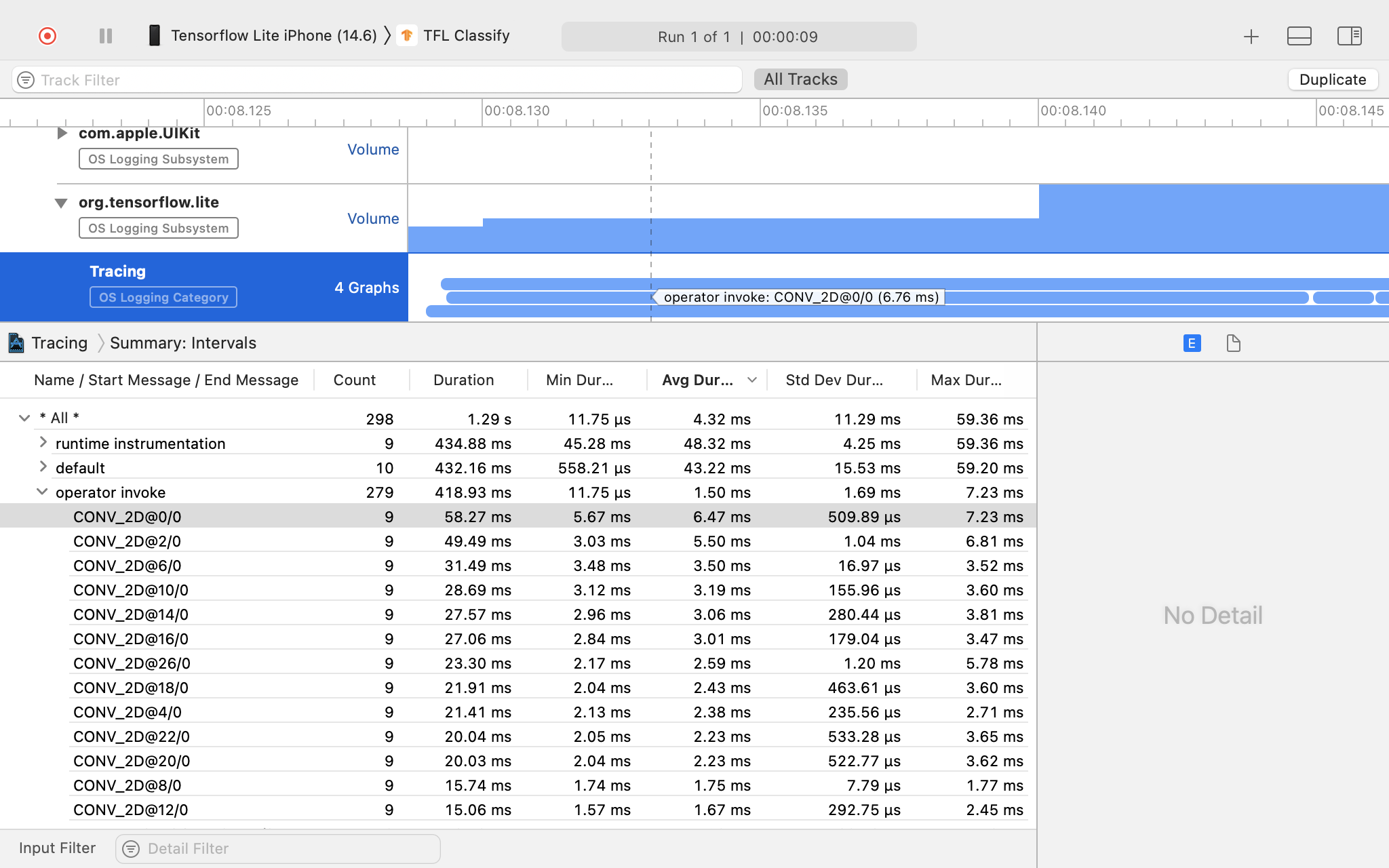
W tym przykładzie możesz zobaczyć hierarchię zdarzeń i statystyki dla każdego czasu operatora.
Korzystanie z danych śledzenia
Dane śledzenia umożliwiają identyfikowanie wąskich gardeł wydajności.
Oto kilka przykładów statystyk, które możesz uzyskać z profilera, oraz potencjalnych rozwiązań poprawiających wydajność:
- Jeśli liczba dostępnych rdzeni procesora jest mniejsza niż liczba wątków wnioskowania, obciążenie związane z planowaniem procesora może prowadzić do gorszej wydajności. Możesz zmienić harmonogram innych zadań obciążających procesor w aplikacji, aby uniknąć nakładania się ich z wnioskowaniem modelu, lub dostosować liczbę wątków interpretera.
- Jeśli operatory nie są w pełni delegowane, niektóre części wykresu modelu są wykonywane na procesorze, a nie na oczekiwanym akceleratorze sprzętowym. Możesz zastąpić nieobsługiwane operatory podobnymi obsługiwanymi operatorami.