
訓練後量化是一種轉換技術,可縮減模型大小,同時改善 CPU 和硬體加速器延遲,且模型準確度不會大幅降低。使用 LiteRT 轉換工具將已訓練的浮點 TensorFlow 模型轉換為 LiteRT 格式時,可以量化模型。
最佳化方法
您可以選擇幾種訓練後量化選項。下表摘要列出各項選擇及其優點:
| 做法 | 優點 | 硬體 |
|---|---|---|
| 動態範圍量化 | 體積縮小 4 倍,速度提升 2 到 3 倍 | CPU |
| 全整數 量化 | 體積縮小 4 倍,速度提升 3 倍以上 | CPU、Edge TPU、 微控制器 |
| Float16 量化 | 體積縮小 2 倍,GPU 加速 | CPU、GPU |
下方的決策樹可協助您判斷哪種訓練後量化方法最適合您的用途:
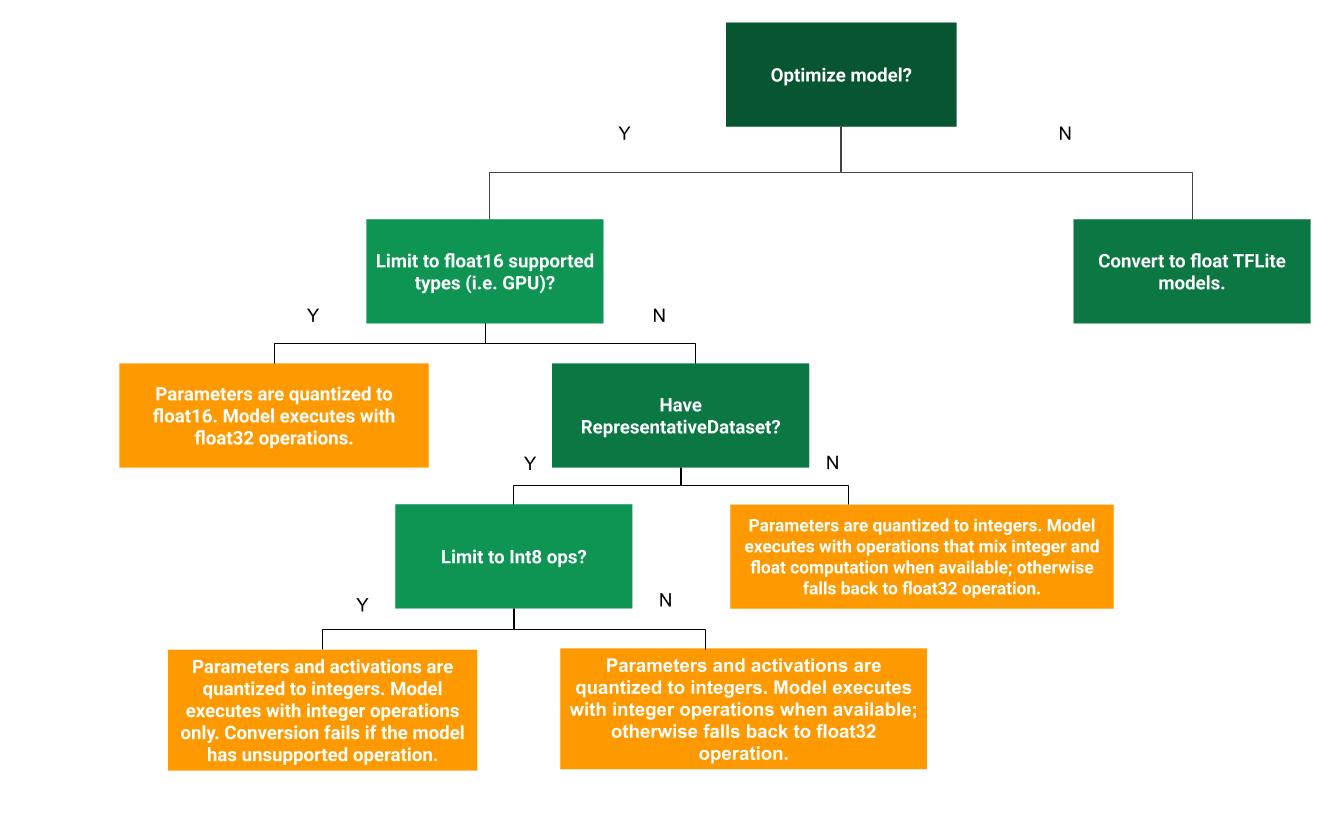
無量化
建議先轉換成未量化的 TFLite 模型。這樣就會產生浮點 TFLite 模型。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
建議您先執行這項操作,確認原始 TF 模型的運算子與 TFLite 相容,並將其做為基準,偵錯後續訓練後量化方法導入的量化錯誤。舉例來說,如果量化 TFLite 模型產生非預期結果,但浮點 TFLite 模型準確無誤,我們就能將問題範圍縮小至 TFLite 運算子量化版本所導入的錯誤。
動態範圍量化
動態範圍量化可減少記憶體用量並加快運算速度,您不必提供代表性資料集進行校正。這類量化會在轉換時,僅將權重從浮點數靜態量化為整數,提供 8 位元的精確度:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
為進一步縮短推論期間的延遲時間,「動態範圍」運算子會根據啟動範圍,將啟動動態量化為 8 位元,並使用 8 位元權重和啟動執行計算。這項最佳化作業可提供接近完全定點推論的延遲時間。不過,輸出內容仍會以浮點數儲存,因此動態範圍作業的速度提升幅度,會小於完整的定點計算。
完整整數量化
如要進一步改善延遲情況、減少尖峰記憶體用量,以及與僅支援整數的硬體裝置或加速器相容,請確保所有模型數學運算都經過整數量化。
如要進行完整整數量化,您需要校正或估算範圍,模型中所有浮點張量的 (最小值、最大值)。與權重和偏差等常數張量不同,模型輸入、活化 (中間層的輸出) 和模型輸出等變數張量無法校準,除非我們執行幾個推論週期。因此,轉換器需要代表性資料集進行校正。這個資料集可以是訓練或驗證資料的一小部分 (約 100 到 500 個樣本)。請參閱下方的 representative_dataset() 函式。
從 TensorFlow 2.7 版開始,您可以透過簽章指定代表性資料集,如下例所示:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
如果指定的 TensorFlow 模型有多個簽名,您可以指定簽名金鑰,藉此指定多個資料集:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
您可以提供輸入張量清單,產生代表性資料集:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
自 TensorFlow 2.7 版起,我們建議使用以簽章為基礎的方法,而非以輸入張量清單為基礎的方法,因為輸入張量順序很容易翻轉。
如要進行測試,可以使用虛擬資料集,如下所示:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
整數 (使用預設的浮點數輸入/輸出)
如要將模型完全量化為整數,但使用沒有整數實作的浮點運算子 (確保轉換順利進行),請按照下列步驟操作:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
只能輸入整數
建立僅限整數的模型,是 LiteRT for Microcontrollers 和 Coral Edge TPU 的常見用途。
此外,為確保與僅支援整數的裝置 (例如 8 位元微控制器) 和加速器 (例如 Coral Edge TPU) 相容,您可以按照下列步驟,對所有作業 (包括輸入和輸出) 強制執行完整整數量化:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 量化
您可以將權重量化為 float16 (IEEE 16 位元浮點數標準),藉此縮減浮點模型的大小。如要啟用權重的 float16 量化,請按照下列步驟操作:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 量化的優點如下:
- 這樣一來,模型大小最多可縮減一半 (因為所有權重都會變成原本大小的一半)。
- 準確度只會略微下降。
- 支援部分委派 (例如 GPU 委派),可直接對 float16 資料執行作業,因此執行速度比 float32 運算更快。
float16 量化的缺點如下:
- 與量化至定點數學相比,這項技術減少的延遲時間較少。
- 根據預設,在 CPU 上執行時,float16 量化模型會將權重值「取消量化」為 float32。(請注意,GPU 委派不會執行這項去量化作業,因為它可以處理 float16 資料)。
僅限整數:16 位元啟動,8 位元權重 (實驗性)
這是實驗性質的量化機制。這與「僅限整數」的配置類似,但活化函數會根據其範圍量化為 16 位元,權重會量化為 8 位元整數,偏誤則會量化為 64 位元整數。這就是所謂的 16x8 量化。
這種量化的主要優點是可大幅提升準確度,但模型大小只會略微增加。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
如果模型中的某些運算子不支援 16x8 量化,模型仍可量化,但系統會將不支援的運算子保留在浮點數中。應將下列選項新增至 target_spec,以允許這項操作。
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
這項量化機制可提升準確度,適用於下列用途:
- 超高解析度
- 音訊信號處理,例如降噪和波束成形,
- 圖片去噪、
- 從單一圖片重建 HDR。
這種量化方式的缺點是:
- 由於缺乏最佳化核心實作,目前的推論速度明顯慢於 8 位元完整整數。
- 目前與現有的硬體加速 TFLite 委派不相容。
如需這項量化模式的教學課程,請參閱這個頁面。
模型準確率
由於權重是在訓練後量化,因此可能會造成準確度損失,尤其是較小的網路。Kaggle 模型提供特定網路的預先訓練全量化模型。請務必檢查量化模型的準確度,確認準確度下降幅度在可接受的範圍內。您可以透過工具評估 LiteRT 模型準確度。
或者,如果準確度降幅過高,請考慮使用量化感知訓練。不過,這樣做需要在模型訓練期間進行修改,才能新增虛假的量化節點,而本頁的訓練後量化技術則使用現有的預先訓練模型。
量化張量的表示法
8 位元量化會使用下列公式,估算浮點值。
\[real\_value = (int8\_value - zero\_point) \times scale\]
這個表示法包含兩個主要部分:
以 int8 二補數值表示的每軸 (又稱每通道) 或每張量權重,範圍為 [-127, 127],零點等於 0。
以 int8 二補數值表示的每個張量啟動/輸入,範圍為 [-128, 127],零點範圍為 [-128, 127]。
如要詳細瞭解量化配置,請參閱量化規格。我們建議想插入 TensorFlow Lite 委派介面的硬體供應商,實作該處說明的量化配置。