
Cada calculadora é um nó de um gráfico. Descrevemos como criar
calculadora, como inicializar uma calculadora, como realizar seus cálculos,
streams de entrada e saída,
carimbos de data/hora e opções. Cada nó do gráfico é
implementado como um Calculator. A maior parte da execução de gráficos acontece dentro
calculadoras. Uma calculadora pode receber zero ou mais fluxos de entrada e/ou lados
e produz zero ou mais fluxos de saída e/ou pacotes laterais.
CalculatorBase
Uma calculadora é criada definindo uma nova subclasse da
CalculatorBase
, implementando diversos métodos e registrando a nova subclasse com
Mediapipe: No mínimo, uma nova calculadora precisa implementar os quatro métodos abaixo
GetContract()- Os autores da calculadora podem especificar os tipos esperados de entradas e saídas de uma calculadora em GetContract(). Quando um gráfico é inicializado, framework chama um método estático para verificar se os tipos de pacote da e as entradas e saídas conectadas correspondem às informações especificação.
Open()- Depois que um gráfico é iniciado, o framework chama
Open(). O lado da entrada pacotes estão disponíveis para a calculadora neste momento.Open()Interpreta as operações de configuração do nó (consulte Gráficos) e prepara o estado por gráfico da calculadora. Essa função pode gravar pacotes nas saídas da calculadora. Um erro duranteOpen()pode encerrar a execução do gráfico.
- Depois que um gráfico é iniciado, o framework chama
Process()- Para uma calculadora com entradas, o framework chama
Process()repetidamente sempre que pelo menos um stream de entrada tiver um pacote disponível. A estrutura por padrão, garante que todas as entradas tenham o mesmo carimbo de data/hora (consulte Sincronização para mais informações). Vários status ChamadasProcess()podem ser invocadas simultaneamente quando a execução paralela está ativado. Se ocorrer um erro duranteProcess(), o framework vai chamarClose()e a execução do gráfico é encerrada.
- Para uma calculadora com entradas, o framework chama
Close()- Após todas as chamadas para
Process()terminarem ou quando todos os streams de entrada forem fechados, o framework chamaClose(). Essa função é sempre chamada seOpen()foi chamado e bem-sucedido, mesmo que a execução do gráfico seja encerrada devido a um erro. Não há entradas disponíveis por fluxos de entrada duranteClose(), mas ainda tem acesso a pacotes do lado de entrada e pode gravar saídas. Depois queClose()retornar, a calculadora deve ser considerado um nó morto. O objeto da calculadora é destruído quando assim que a execução do gráfico for concluída.
- Após todas as chamadas para
A seguir estão os snippets de código CalculatorBase.h padrão.
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static absl::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual absl::Status Open(CalculatorContext* cc) {
return absl::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual absl::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual absl::Status Close(CalculatorContext* cc) {
return absl::OkStatus();
}
...
};
O ciclo de uma calculadora
Durante a inicialização de um gráfico do MediaPipe, a estrutura chama um
Método estático GetContract() para determinar que tipos de pacotes são esperados.
O framework constrói e destrói toda a calculadora para cada execução de gráfico. (por exemplo, uma vez por vídeo ou por imagem). Objetos caros ou grandes que permanecem constante entre execuções de grafo deve ser fornecida como pacotes de entrada, os cálculos não são repetidos em execuções subsequentes.
Após a inicialização, para cada execução do gráfico, ocorre a seguinte sequência:
Open()Process()(repetidamente)Close()
O framework chama Open() para inicializar a calculadora. Open() deveria
interpretar as opções e configurar o estado por gráfico da calculadora. Open()
pode receber pacotes do lado de entrada e gravar pacotes nas saídas da calculadora. Se
apropriado, ele deve chamar SetOffset() para reduzir o possível buffering de pacotes
de fluxos de entrada.
Se ocorrer um erro durante Open() ou Process() (conforme indicado por uma delas).
retornar um status diferente de Ok), a execução do gráfico será encerrada sem outras chamadas
aos métodos da calculadora, e ela será destruída.
Para uma calculadora com entradas, o framework chama Process() sempre que, pelo menos,
uma entrada tem um pacote disponível. O framework garante que todas as entradas tenham
o mesmo carimbo de data/hora, que os carimbos de data/hora aumentam a cada chamada para Process() e
que todos os pacotes sejam entregues. Como consequência, algumas entradas podem não ter
pacotes quando Process() é chamado. Uma entrada com um pacote faltando parece
e produza um pacote vazio (sem carimbo de data/hora).
O framework chama Close() depois de todas as chamadas para Process(). Todas as entradas vão
foram esgotados, mas Close() tem acesso a pacotes do lado de entrada e pode
gravar dados. Depois que Close retornar, a calculadora será destruída.
Calculadoras sem entradas são chamadas de origens. Uma calculadora de origem
A função Process() continua sendo chamada, desde que retorne um status Ok. Um
a calculadora de origem indica que se esgotou ao retornar um status de parada
Por exemplo, mediaPipe::tool::StatusStop().
Identificar entradas e saídas
A interface pública de uma calculadora consiste em um conjunto de fluxos de entrada e
streams de saída. Em uma CalculatorGraphConfiguration, as saídas de alguns
calculadoras são conectadas às entradas de outras calculadoras usando
córregos. Os nomes dos fluxos normalmente ficam em letras minúsculas, enquanto as tags de entrada e saída
normalmente LETRAS MAIÚSCULAS. No exemplo abaixo, a saída com o nome de tag VIDEO é
conectado à entrada com o nome de tag VIDEO_IN usando o fluxo chamado
video_stream
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
Os streams de entrada e saída podem ser identificados por número de índice, nome de tag ou
combinação de nome de tag e número de índice. Você pode conferir alguns exemplos de
identificadores de saída no exemplo abaixo. SomeAudioVideoCalculator identifica
sua saída de vídeo por tag e suas saídas de áudio pela combinação de tag e
índice. A entrada com a tag VIDEO está conectada ao fluxo chamado
video_stream. As saídas com a tag AUDIO e os índices 0 e 1 são
conectado aos streams chamados audio_left e audio_right.
SomeAudioCalculator identifica as entradas de áudio somente por índice (nenhuma tag é necessária).
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
Na implementação da calculadora, as entradas e saídas também são identificadas por tags. nome e número do índice. Na função abaixo, a entrada e a saída são identificadas:
- Por número de índice: o fluxo de entrada combinado é identificado simplesmente pelo índice.
0: - Por nome da tag: o stream de saída de vídeo é identificado pelo nome da tag "VIDEO".
- Por nome de tag e número de índice: os streams de áudio de saída são identificados pelo
combinação do nome de tag
AUDIOe os números de índice0e1.
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return absl::OkStatus();
}
Processando
Process() chamado em um nó que não seja de origem precisa retornar absl::OkStatus() para
indicar que tudo correu bem ou qualquer outro código de status para sinalizar um erro
Se uma calculadora que não seja de origem retornar tool::StatusStop(), isso vai sinalizar:
gráfico está sendo cancelado antecipadamente. Neste caso, todas as calculadoras de origem e gráficos
os fluxos de entrada serão fechados, e os pacotes restantes se propagarão pela
gráfico).
Um nó de origem em um gráfico continuará a ter Process() chamado enquanto
já que retorna absl::OkStatus(). Para indicar que não há mais dados a serem
o retorno gerado tool::StatusStop(). Qualquer outro status indica que um erro
o incidente.
Close() retorna absl::OkStatus() para indicar o sucesso. Qualquer outro status
indica uma falha.
Esta é a função Process() básica. Ela usa o método Input(), que pode
ser usada apenas se a calculadora tiver uma única entrada) para solicitar seus dados de entrada. Ela
usa std::unique_ptr para alocar a memória necessária para o pacote de saída;
e faz os cálculos. Quando terminar, ele libera o ponteiro ao adicioná-lo ao
no stream de saída.
absl::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return absl::OkStatus();
}
Opções da calculadora
As calculadoras aceitam parâmetros de processamento usando (1) pacotes de stream de entrada (2)
pacotes de entrada, e (3) opções de calculadora. Opções da calculadora, se
especificado, aparecem como valores literais no campo node_options do
CalculatorGraphConfiguration.Node mensagem.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
O campo node_options aceita a sintaxe do proto3. Como alternativa, a calculadora
podem ser especificadas no campo options usando a sintaxe proto2.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Nem todas as calculadoras aceitam opções de calculadora. Para aceitar opções, um
padrão vai definir um novo tipo de mensagem protobuf para representar seu
opções, como PacketClonerCalculatorOptions. Então, a calculadora vai
ler essa mensagem protobuf no método CalculatorBase::Open e, possivelmente,
na função CalculatorBase::GetContract ou nas
CalculatorBase::Process. Normalmente, o novo tipo de mensagem protobuf retorna
ser definido como um esquema protobuf usando um arquivo ".proto" e um
mediapipe_proto_library().
mediapipe_proto_library(
name = "packet_cloner_calculator_proto",
srcs = ["packet_cloner_calculator.proto"],
visibility = ["//visibility:public"],
deps = [
"//mediapipe/framework:calculator_options_proto",
"//mediapipe/framework:calculator_proto",
],
)
Exemplo de calculadora
Esta seção discute a implementação de PacketClonerCalculator, que
faz um trabalho relativamente simples e é usado em muitos gráficos de calculadora.
PacketClonerCalculator apenas produz uma cópia dos pacotes de entrada mais recentes
sob demanda.
PacketClonerCalculator é útil quando os carimbos de data/hora dos pacotes de dados que chegam
não estão perfeitamente alinhadas. Imagine que temos um cômodo com microfone, luz
e uma câmera de vídeo que
está coletando dados sensoriais. Cada um dos sensores
opera de forma independente e coleta dados intermitentemente. Suponha que a saída
de cada sensor é:
- microfone = volume em decibéis do som no ambiente (número inteiro)
- sensor de luz = brilho do ambiente (número inteiro)
- câmera de vídeo = frame de imagem RGB do ambiente (ImageFrame)
Nosso pipeline de percepção simples foi projetado para processar dados sensoriais dessas três sensores para que, a qualquer momento, tenhamos dados de frames de imagem da câmera que é sincronizado com os últimos dados de volume e luz do microfone coletados dados de brilho do sensor. Para fazer isso com o MediaPipe, nosso pipeline de percepção tem 3 streams de entrada:
- room_mic_signal - Cada pacote de dados neste fluxo de entrada é formado por um número inteiro representando o volume do áudio em uma sala com marcação de tempo.
- room_lightening_sensor: cada pacote de dados nesse fluxo de entrada é um número inteiro. dados que representam a intensidade da iluminação da sala com um carimbo de data/hora.
- room_video_tick_signal - Cada pacote de dados nesse fluxo de entrada é frame de imagem de dados de vídeo representando o vídeo coletado da câmera no sala com carimbo de data/hora.
Confira abaixo a implementação do PacketClonerCalculator. É possível conferir
os métodos GetContract(), Open() e Process(), além da instância
A variável current_ contém os pacotes de entrada mais recentes.
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return absl::OkStatus();
}
absl::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return absl::OkStatus();
}
absl::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return absl::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
Normalmente, uma calculadora tem apenas um arquivo .cc. Não é necessário usar um arquivo .h, porque O mediapipe usa o registro para disponibilizar calculadoras. Depois de ter definiu sua classe de calculadora, registre-a com uma invocação de macro REGISTER_CALCULATOR(calculator_class_name).
Confira abaixo um gráfico trivial do MediaPipe que tem três fluxos de entrada e um nó (PacketClonerCalculator) e dois streams de saída.
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
O diagrama abaixo mostra como a PacketClonerCalculator define a saída
pacotes (inferior) com base na série de pacotes de entrada (superior).
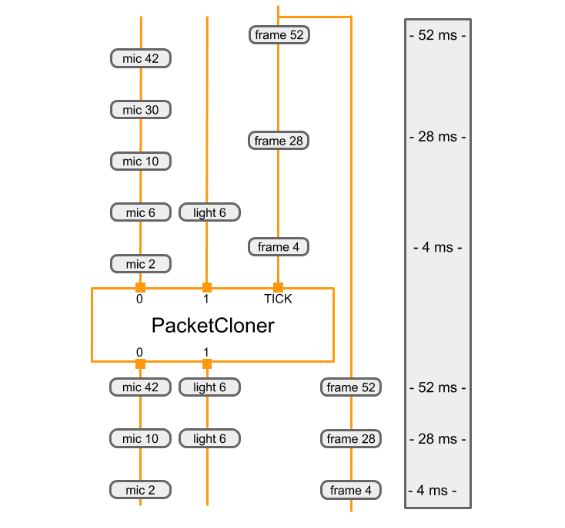 |
|---|
| Cada vez que recebe um pacote no fluxo de entrada TICK, o PacketClonerCalculator gera o pacote mais recente de cada um dos fluxos de entrada. A sequência dos pacotes de saída (parte inferior) é determinada pela sequência dos pacotes de entrada (superior) e os carimbos de data/hora deles. Os carimbos de data/hora aparecem no lado direito do diagrama. |