
Die Google Cloud-Lösung von AI Edge für das Testen und Benchmarking von On-Device-Machine-Learning (ML) im großen Maßstab.
Die Optimierung der Leistung von ML-Modellen auf verschiedenen Mobilgeräten kann eine Herausforderung sein. Manuelle Tests sind langsam, kostspielig und für die meisten Entwickler oft nicht zugänglich, was zu Unsicherheiten bei der realen Modellleistung führt. Das Google AI Edge-Portal bietet hier eine Lösung, indem es LiteRT-Modellbenchmarking auf einer Vielzahl von Mobilgeräten ermöglicht. So können Entwickler die besten Konfigurationen für die Bereitstellung von ML-Modellen im großen Maßstab finden.
Optimierung der Bereitstellung von ML auf Mobilgeräten
Testzyklen für die vielfältige Hardwarelandschaft vereinfachen und beschleunigen: Bewerten Sie die Modellleistung auf Hunderten von repräsentativen Mobilgeräten in wenigen Minuten.
Proaktiv für Modellqualität sorgen und Probleme frühzeitig erkennen: Hardware-spezifische Leistungsvariationen oder Regressionen (z. B. auf bestimmten Chipsets oder Geräten mit eingeschränktem Arbeitsspeicher) vor der Bereitstellung erkennen.
Geringere Kosten für Gerätetests und Zugriff auf die neueste Hardware: Sie können Ihre App auf einer vielfältigen und ständig wachsenden Flotte physischer Geräte testen (derzeit über 100 Gerätemodelle von verschiedenen Android-OEMs), ohne dass Sie ein eigenes Labor unterhalten müssen.
Fundierte, datengestützte Entscheidungen treffen und Business Intelligence nutzen: Das Google AI Edge-Portal bietet umfangreiche Leistungsdaten und Vergleiche, die die entscheidenden Business Intelligence-Informationen liefern, die für eine fundierte Modelloptimierung und die Validierung der Bereitstellungsbereitschaft erforderlich sind.
Beispiel-Benchmark:
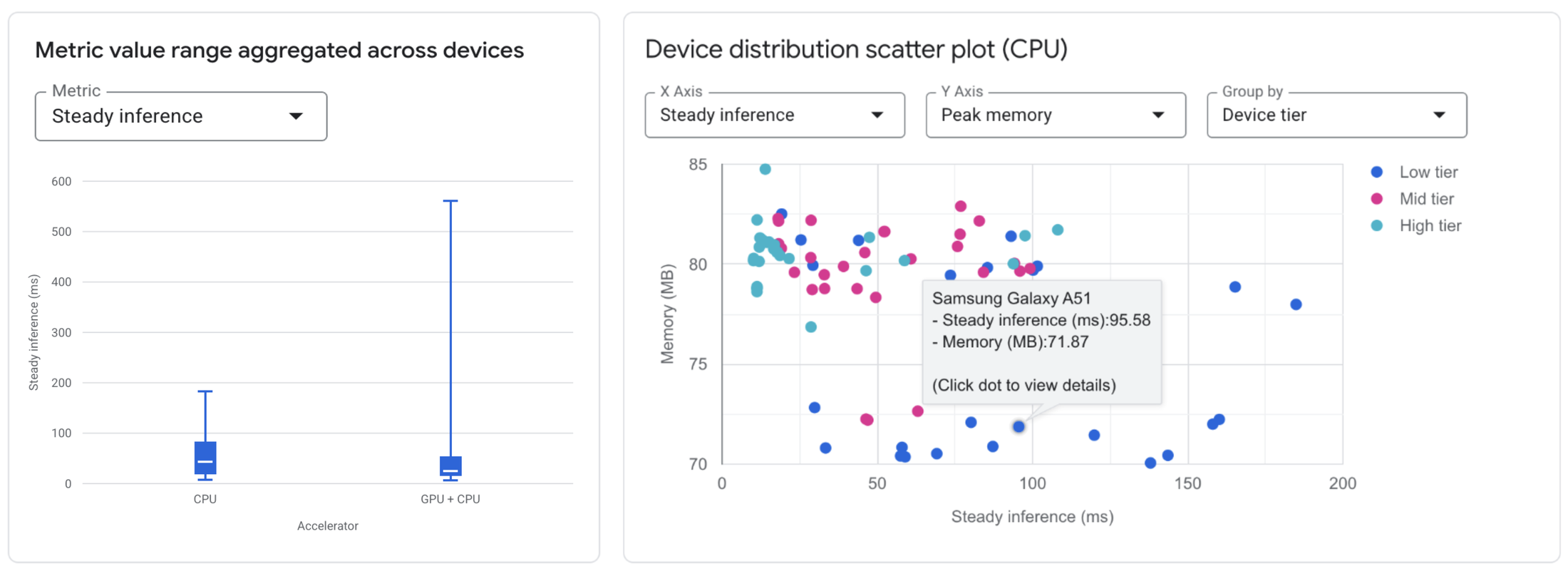
So können Sie mit dem Google AI Edge-Portal Ihre LiteRT-Modelle vergleichen
Geräte auswählen: Wählen Sie Ihre Zielgeräte aus unserem umfangreichen Pool mit spezifischen Hardwarefiltern aus, darunter NPU-Unterstützung, Geräteklasse, Marke, Chipsatz und RAM. Alternativ können Sie unsere kuratierten Verknüpfungen verwenden, um sofort auf beliebte Gerätelisten zuzugreifen.
Konfigurationen erstellen: Wählen Sie für Ihre Benchmarking-Aufgaben zwischen CPU-, GPU- oder NPU-Beschleunigern aus.
Erweiterte Anpassung: Passen Sie hardwarespezifische Einstellungen für den ausgewählten Beschleuniger an oder verwenden Sie die Standardwerte.
NPU-Unterstützung: Die Hardwarebeschleunigungsfunktionen umfassen jetzt NPUs und eine Reihe von über 30 Qualcomm-Geräten.
- Ahead-Of-Time-Kompilierung (AOT): Empfohlen für die Leistung auf Produktionsebene. Sie bietet eine deutlich schnellere Initialisierung und einen geringeren Speicherbedarf. In diesem Modus müssen kompilierte Modelle für jeden einzelnen SoC in Ihrer Geräteauswahl bereitgestellt werden.
- Just-In-Time-Kompilierung (JIT): Unterstützt ein einzelnes Modell für die Kompilierung auf ausgewählten Geräten.
Modelle hochladen: Laden Sie Ihre Modelldatei über die Benutzeroberfläche hoch oder verweisen Sie darauf in Ihrem Google Cloud Storage-Bucket.
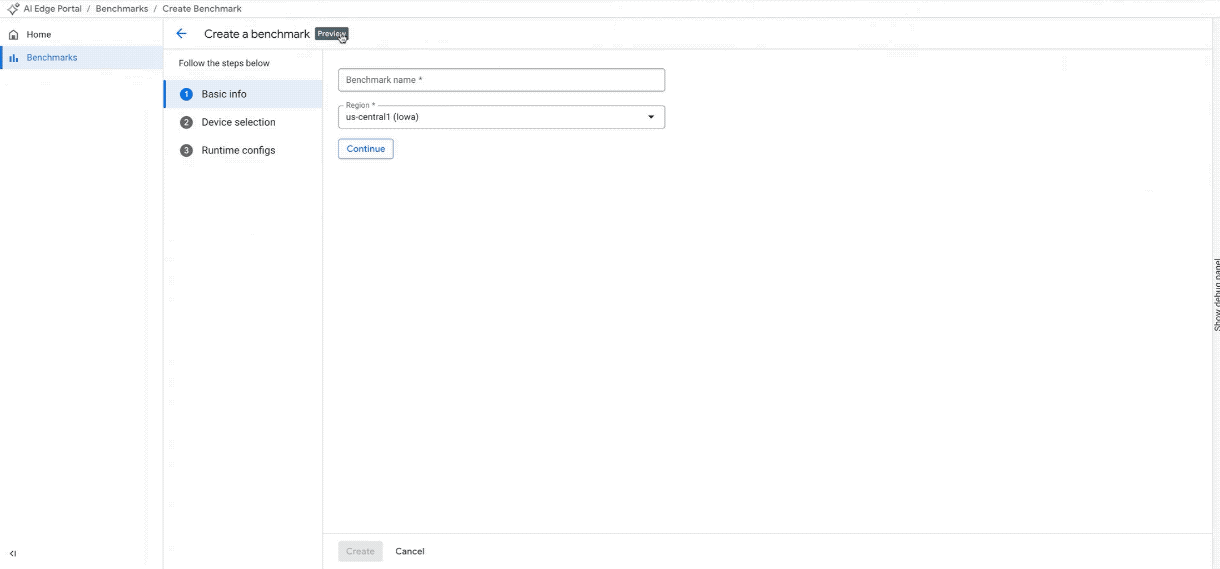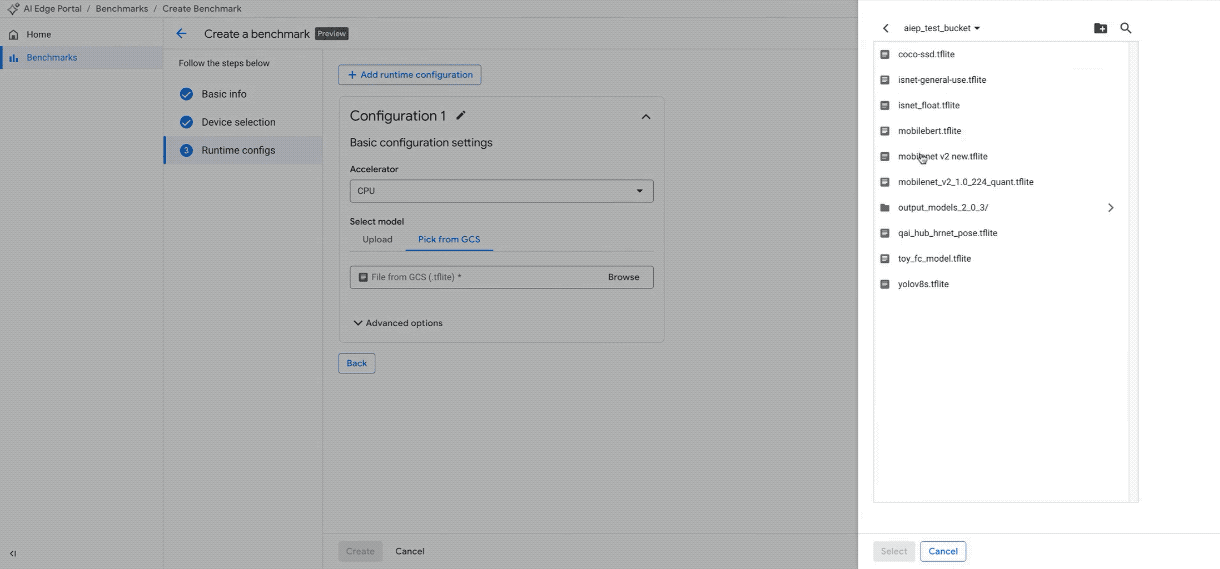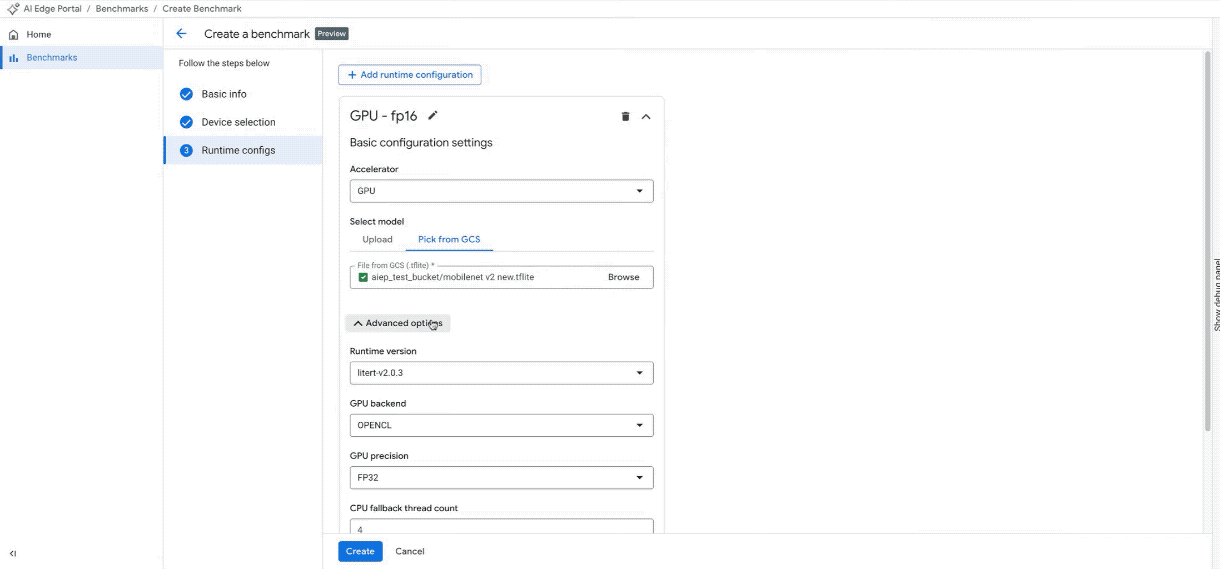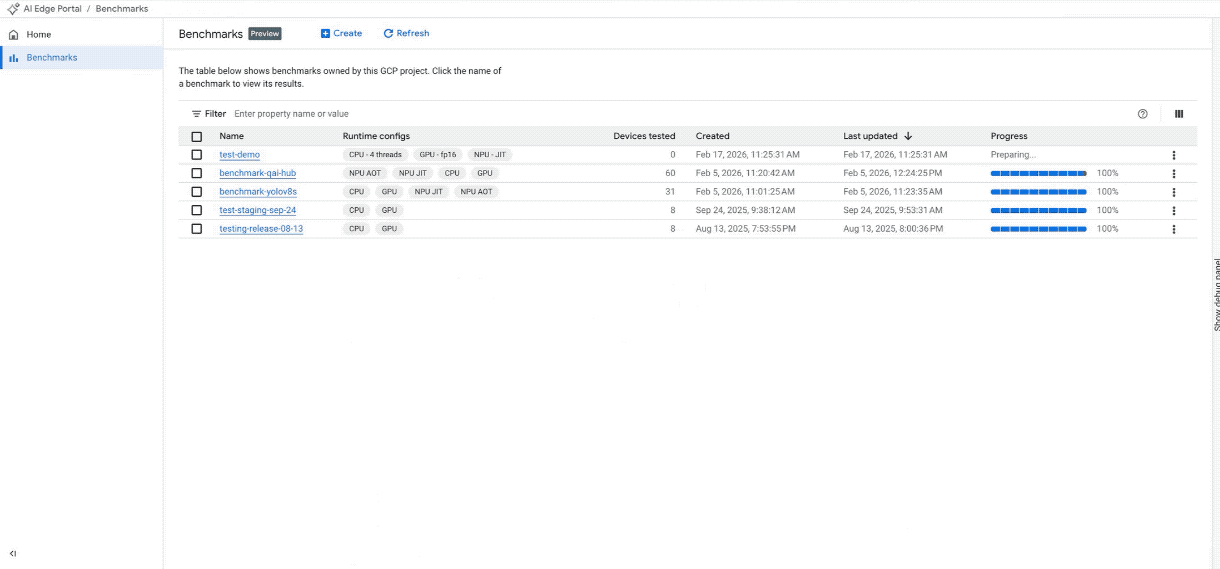
Neuen Benchmark-Job auf mindestens 100 Geräten erstellen. (Hinweis: Das GIF wurde beschleunigt und gekürzt.)
Senden Sie den Job und warten Sie, bis er abgeschlossen ist. Wenn Sie bereit sind, können Sie die Ergebnisse im interaktiven Dashboard ansehen:
Konfigurationen vergleichen: Sie können schnell visualisieren, wie sich Leistungsmesswerte (z.B. durchschnittliche Latenz, maximaler Speicher) bei Verwendung verschiedener Beschleuniger auf allen getesteten Geräten unterscheiden.
Geräteauswirkungen analysieren: Hier sehen Sie, wie eine bestimmte Modellkonfiguration auf den ausgewählten Geräten abschneidet. Mit Histogrammen und Streudiagrammen lassen sich Leistungsabweichungen, die mit Gerätecharakteristika zusammenhängen, schnell erkennen.
Detaillierte Messwerte: Sie können auf eine detaillierte, sortierbare Tabelle mit spezifischen Messwerten (Initialisierungszeit, Inferenzlatenz, Arbeitsspeicherverbrauch) für jedes einzelne Gerät sowie dessen Hardwarespezifikationen zugreifen. Prüfen Sie die Hardwareauslastung mit der Tabelle „Accelerator Allocation“ (Beschleunigerzuweisung). Dort sehen Sie, wie Modellvorgänge auf Kerne verteilt werden (für CPU und GPU verfügbar, NPU-Unterstützung folgt in Kürze).
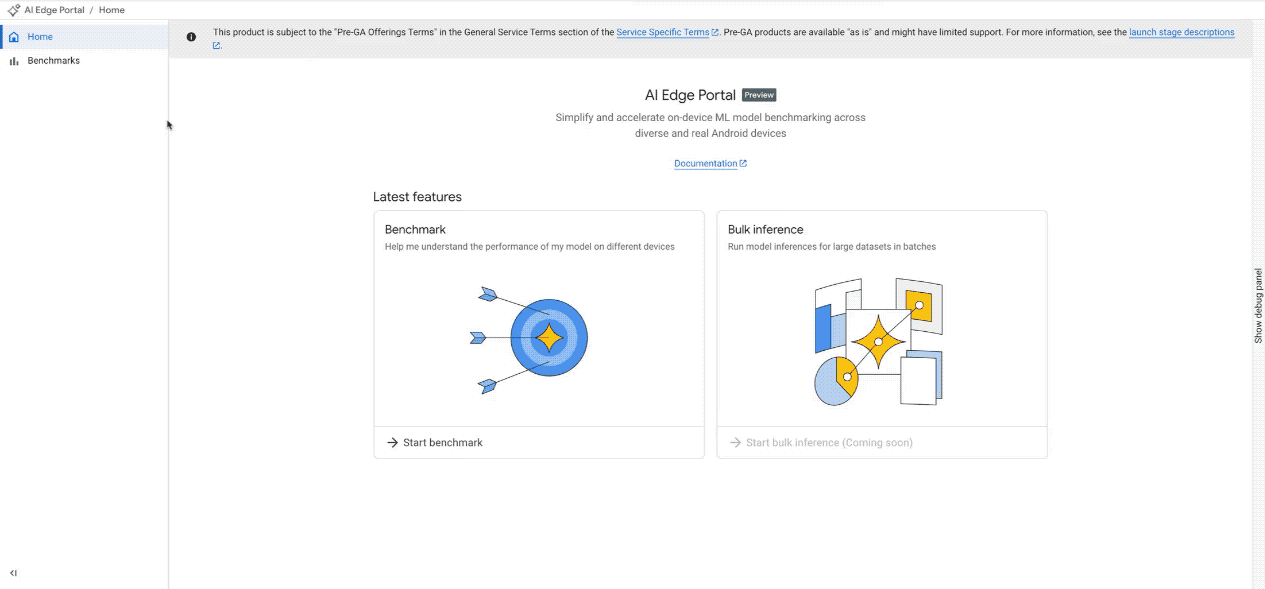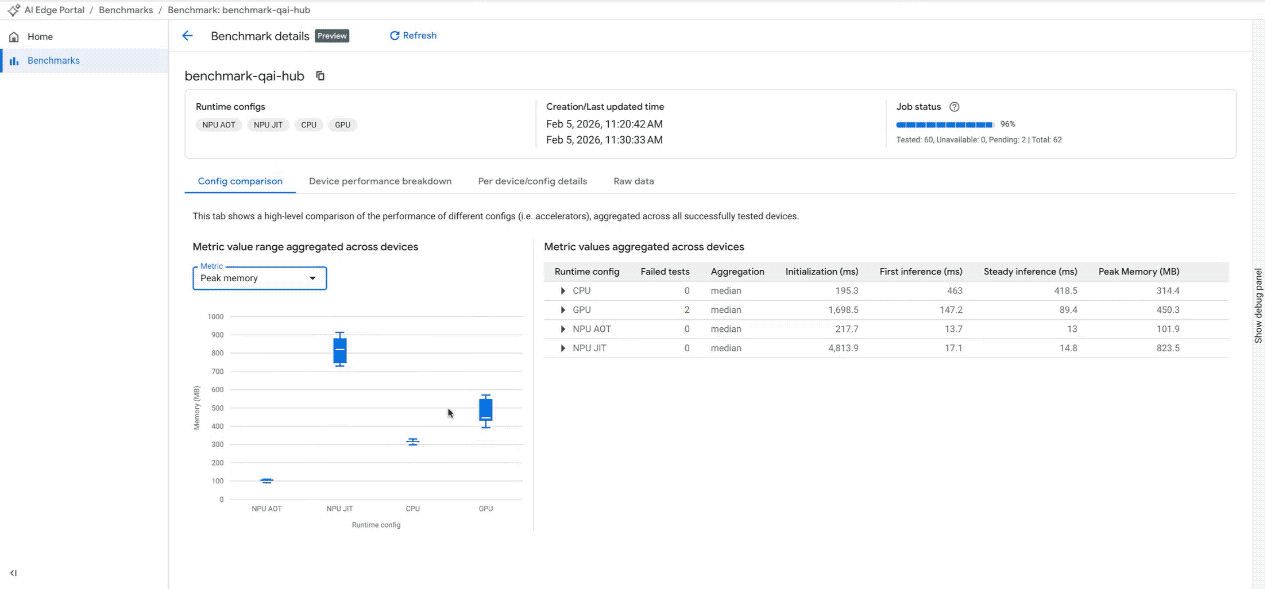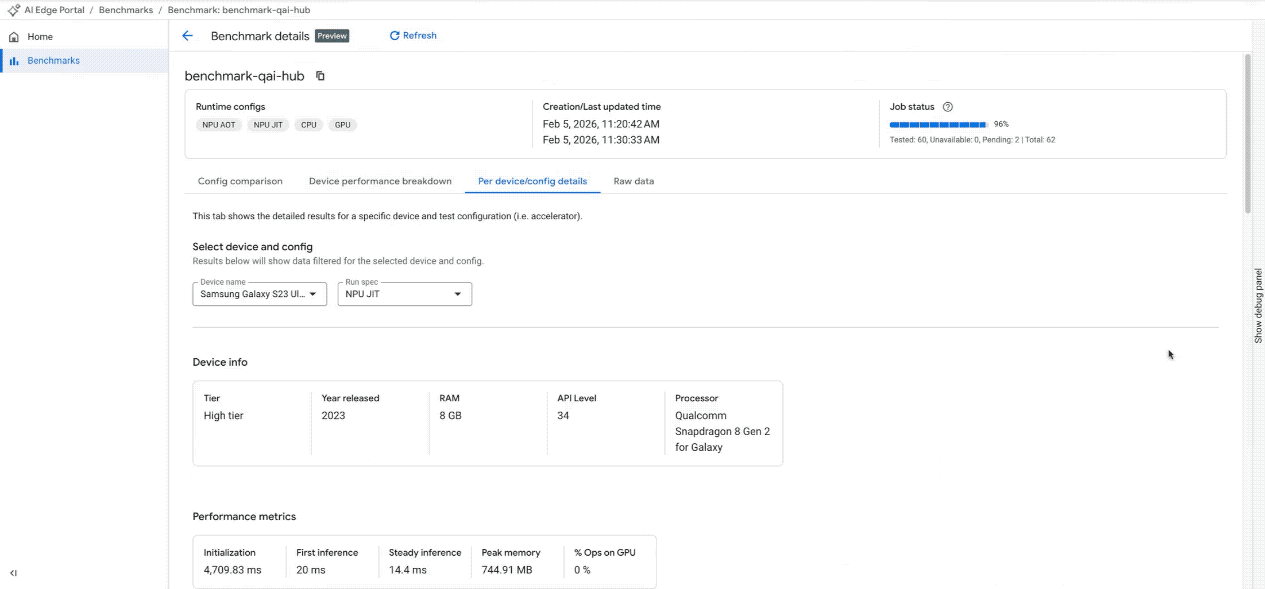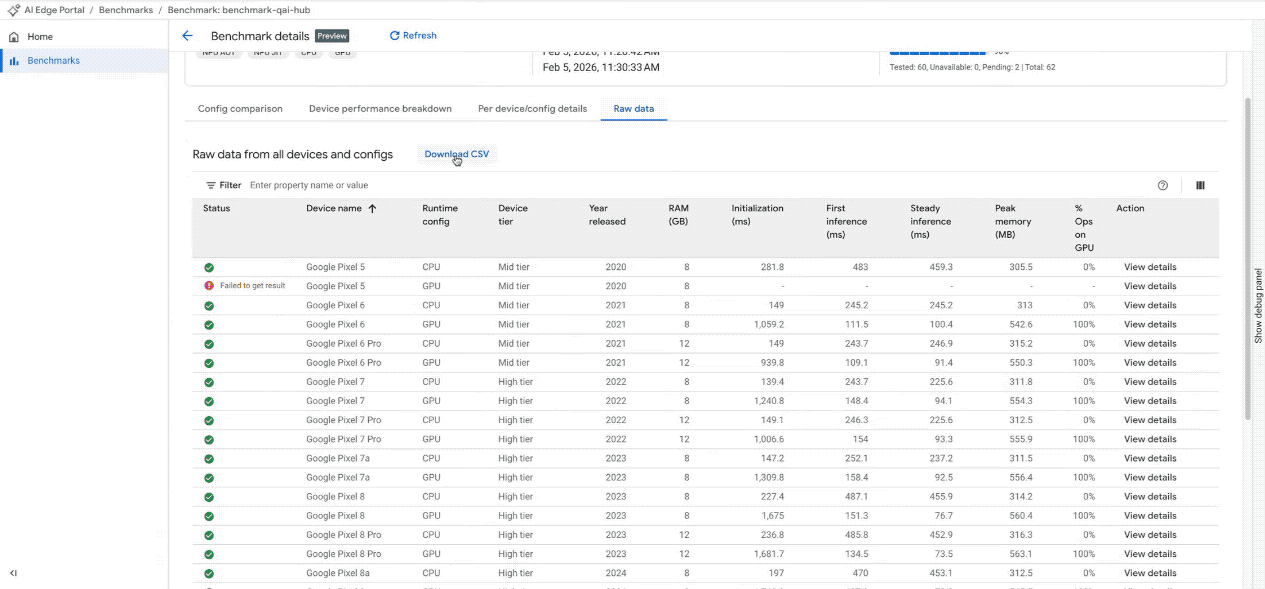
Benchmark-Ergebnisse im interaktiven Dashboard ansehen. (Hinweis: Das GIF wurde beschleunigt und bearbeitet, um es kürzer zu halten.)
Private Vorschau des Google AI Edge-Portals nutzen
Das Google AI Edge-Portal ist in der privaten Vorschau für Kunden auf der Zulassungsliste von Google Cloud verfügbar. Während des Zeitraums der privaten Vorschau ist der Zugriff gemäß den Vorschau-Nutzungsbedingungen kostenlos.
Diese Vorabversion ist ideal für Entwickler und Teams, die mobile ML-Anwendungen mit LiteRT erstellen, zuverlässige Benchmarking-Daten für verschiedene Android-Hardware benötigen und bereit sind, Feedback zu geben, um die Zukunft des Produkts mitzugestalten. Wenn Sie Zugriff anfordern möchten, füllen Sie bitte dieses Anmeldeformular aus. Der Zugriff wird über die Zulassungsliste gewährt.